Splunk
スプランク

よくある質問
Splunkとは?
Splunkって何?
ITサーチエンジンです。Splunkを使用すれば、ITインフラが出力するログデータやコンフィグレーションファイルなどのITデータをリアルタイムで検索し、容易に見つけ出すことができるようになります。Splunkはログデータや、アプリケーション、サーバ、ネットワーク機器が出力するデータに対し、リアルタイム検索を可能にするインデックスを作成します。
Splunkはサービスですか、アプライアンスですか、それともソフトウェアですか?
Splunkはどのような問題を解決できますか?
誰がSplunkを使うのですか?
Splunkはどんな用途で使われることが多いですか?
Splunkはオープンソースですか?
フリー版ライセンスとエンタープライズ版ライセンスの違いは何ですか?
分散したデータの横断的な検索やクラスタリングをしたい、また、アクセスコントロールや複数のユーザアカウントを設定したい、というご要望がある場合には、エンタープライズ版ライセンスをご利用ください。
価格情報
Splunkエンタープライズ版の価格はどれくらいですか?
Forwarder
Universal ForwarderとHeavy Forwarderの違いは?
Universal ForwarderとHeavy Forwarderインストーラーが異なります。
Universal Forwarderは、データの収集および転送に特化した機能が提供される小さいサイズのインストーラーとなり、Heavy Forwarderは通常のインデックスサーバと同じインストーラーになります。
転送時にデータの一部をマスク化したり、高度なフィルタ処理を行う場合には、Heavy Forwarderの利用が必要です。
シンプルにデータ収集・転送を行う場合には、Universal Forwarderの利用がお勧めです。
尚、下記に各Forwarderの違いについて記載がございますので、ご参照いただければと 存じます。
http://docs.splunk.com/Documentation/Splunk/latest/Forwarding/Typesofforwardersインストール時の注意点
Splunkのインストールにどれくらい時間がかかりますか?
運用システムやアプリケーション、ネットワークに対するSplunkの影響はどのようなものがありますか?またメモリはどれくらい使用しますか?
システム要件
Splunkは複数CPUやマルチコアであればパフォーマンスは高くなりますか?
Splunkはどのプラットフォーム上で動作しますか?
Linux、Windows、OS X(Mac OS X)など複数のOSに対応しています。
詳細はこちらをご覧ください。Splunkはエージェントを必要としますか?
SplunkはさまざまなフォーマットのITデータを特別なアダプタを用意することなく、あらゆるフォーマットのログデータを読み取り、インデックスを作成することができます。SplunkはsyslogやSNMP、あるいはrsyncでミラーされたファイルを読み取ったり、scpやftpでセンターのログホスト上にローテートされるファイルを読み取ったりすることにより、リモートからのデータを取得できます。
お客様の環境に、リモートからデータを収集する仕組みが無い場合などには、Splunk Universal Forwarderをご利用いただく事もできます。この場合でも、フォーマットに合わせた開発などは不要です。
データの取り込み
SplunkでシフトJISのログファイルを取り込むために必要な設定は?
シフトJIS形式のログファイルを取り込むためには、あらかじめエンコーディング種類を指定する設定ファイルを作成する必要があります。
- まず、取り込むログファイルに設定予定の「ソースタイプ」を決めます。例えば、Webアプリケーションであれば、「webapp」のようにします。
- Splunkのインストールフォルダ以下の「system\local」フォルダに、「props.conf」ファイルを作成し、次のように入力します。
[webapp]
CHARSET=SHIFT-JIS
※上記の設定は、ソースタイプに、webappと指定されたファイルを読み込む際SHIFT-JISから内部処理に利用するUTF-8へ明示的に変換を行う事を示しています。同様に、EUC-JPのログファイルの場合、CHARSET=EUC-JP とします。 - props.confで設定を入力してから、Splunkの再起動、もしくは、検索コマンド「| extract reload=t」にて、上記の設定を反映させてください。
※直接 props.conf を編集した際に、「| extract reload=t」を検索コマンドとして入力して検索する事で、設定ファイルが読み込まれ、反映されます。 - Splunkの管理画面、データ入力にてログファイルを指定する際に、「ソースタイプのセット」にて【手動】を選択します。そして「ソースタイプ」には、上記のprops.confにて指定したソースタイプを入力します。この例では、「webapp」と入力します。
なお、上記の設定がされていない状態で取り込んだために発生した文字化けは解消されません。お手数ですが、再度、イベントを取り込んでいただく必要があります。
特定の文字を含むデータは取込まないことができますか?
インデックスサーバ側での制御によって可能です。
設定は、「props.conf」と「transforms.conf」という2つの設定ファイル にて行います。
下記はサンプルの設定です。
----------------------------------------
■props.conf
[wmi]
TRANSFORMS-test=testnull
----------------------------------------
※wmiはソースタイプになりますので、お客様の環境にあわせて、設定いただく必要があります。
----------------------------------------
■transforms.conf
[testnull]
REGEX=^EventCode=(592|593)
DEST_KEY=queue
FORMAT=nullQueue
----------------------------------------
上記設定後、インデックサーバを再起動してください。
Splunk特有の用語
アトリビュート(Attribute)
設定ファイルのスタンザの下に指定できる各種パラメーターです。
key=valueの形で記載します。設定ファイルによって指定できるアトリビュートは異なり、またアトリビュートによって指定できる値も異なります。
インデクサー(Indexer)
サブサーチ(Sub Search)
サブサーチとは検索の結果を使って新たな検索を行ったり、複数の検索の結果を結合する際に利用する検索のテクニックです。
サブサーチは、角括弧"[]"で囲んで指定します。例えば、ファイアーウォールのログで、通信データ量が最大の通信元IPについて、通信先IPと通信量の内訳を調査する場合のようなケースで利用します。
サーチヘッド(Search head)
スタンザ(Stanza)
ダッシュボード(Dashboard)
1つもしくは複数のパネルで構成され、表やグラフなどを一覧表示するための機能です。
入力ボックスやドリルダウンの機能をダッシュボードに持たせ、動的に表示内容を変化させることが可能です。simpleXMLというSplunkオリジナルのコードや、HTMLを利用することにより、表示形式を変更することも可能です。
データモデル(Data model)
データモデルとは、1つ以上のデータソースを基に、意味のある検索単位をまとめた階層構造を持った分析モデルです。
階層構造とは、以下のように基準となる親検索を作成し、その検索から派生した意味のある検索(子検索)で構成されます。
- 親:Webサーバのアクセスログ
-
- 子:夜間の通信
- 子:昼間の通信
- 子:××を実施している通信
データモデルを作成することにより、例えば「夜間」で最も多い「接続先ドメイン」が何か調査する場合でも、Splunkコマンドを使わず、GUI操作(Pivot)で結果を得ることが可能です。つまり、データモデルを作成することで、特別な知識や技能を持たなくとも、データを分析する環境を用意することが可能となります。
なお、作成したデータモデルの高速化設定を有効にすると、通常の検索よりも最大1000倍高速に結果を得ることが出来ます。
パネル(Panel)
ダッシュボード上にグラフや表を配置する際の一区画のことを指します。
1つのパネルに複数のグラフを配置することができます。ダッシュボード上から新規のパネルを作成したり、内容の編集を行うことができます。
フォワーダー(Forwarder)
技術情報FAQ
機能説明
取り込みデータのタイムゾーンを認識する優先順位
- 公開日
- 2019.09.04
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.1.1
- 概要
-
Splunkではデータを取込む際に自動でタイムゾーンを認識して抽出する機能があります。
タイムゾーン抽出時の優先順位は以下の順番で評価します。1.取り込みデータに記載されているタイムゾーン
2.props.confで指定されているタイムゾーン
3.フォワーダーのシステムタイムゾーン
4.インデクサーのシステムタイムゾーン
- 内容
-
取り込みデータのタイムゾーンを認識する優先順位
Splunkは以下の項番1から優先的に取り込みデータのタイムゾーンを認識します。
- 取り込みデータの1イベント内にタイムゾーン情報が記載されている場合
(例: PST、-0800)、記載されているタイムゾーンで認識します。 - props.confの「TZ」パラメーターで取り込むデータのタイムゾーンを指定している場合、指定されたタイムゾーンで認識します。
※ユニバーサルフォワーダーを利用している場合、インデクサーのprops.confが使用されます。
※ヘビーフォワーダーを利用している場合、ヘビーフォワーダーのprops.confが使用されます。 - バージョン6.0以降のユニバーサルフォワーダー、又はヘビーフォワーダーを用いて取り込みを行っている場合、フォワーダーが動作しているOSのタイムゾーンで認識します。
- インデクサーが動作しているOSのタイムゾーンで認識します。
以上
- 取り込みデータの1イベント内にタイムゾーン情報が記載されている場合
add oneshot コマンドを使ったファイルの取り込み方法
- 公開日
- 2019-08-29
- 最終更新日
- 2024-02-28
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- Splunk の add oneshot コマンドを使用することで、指定したファイルをインデックスに取り込むことが出来ます。
障害発生時や設定不備等により上手く取り込めなかったファイルを再取り込みしたり、検証用のサンプルログを取り込む際にご利用ください。
- 参考情報
-
- CLI を利用したファイルとディレクトリのモニター
- 内容
-
add oneshotとは
add oneshot はCLIから実行するSplunkのコマンドの一種で、指定したファイルをインデックスに取り込むために使用します。
このコマンドでのファイルの取り込みは、実行時に1度だけ行われます。
具体的には、以下のような状況で利用できます。
- 設定の不備等により上手く取り込まれなかったファイルを再度取り込む
- delete コマンドで削除したファイルのデータを再度取り込む
- テスト用のファイルを試験的に取り込む
また、add oneshotコマンドを実行するSplunkのインスタンスによって動作が異なります。
- インデクサー:コマンドを実行したインデクサーに取り込まれます。
- ユニバーサルフォワーダー:転送先のインデクサーに取り込まれます。
add oneshotの構文
以下が add oneshot コマンドの構文です。
<構文>
$SPLUNK_HOME/bin/splunk add oneshot <取り込みファイルパス> [-オプション 値]※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下になります。
Windows :
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarderLinux :
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder以下は取り込みファイルパスと合わせて、インデックスとソースタイプ、認証用のオプションを追加して実行する際のコマンドの例となります。
<コマンド実行例>
/opt/splunk/bin/splunk add oneshot /var/log/secure
-index security -sourcetype linux_secure -auth admin:password※実際に実行する際は、オプション指定を含めて1行で入力してください。
<取り込み条件>
Splunk のインストールディレクトリ : /opt/splunk
取り込みファイルパス : /var/log/secure
取り込み先インデックス : security
取り込みログのソースタイプ : linux_secure
管理者ユーザー : admin
管理者パスワード : password<実行例>
/opt/splunk/bin/splunk add oneshot /var/log/secure -index security
-sourcetype linux_secure -auth admin:password※実際に実行する際は、オプション指定を含めて1行で入力してください。
各オプションの詳細については、下記「コマンドオプション」を参照ください。
注意事項
- 取り込みファイルパス以外は任意のオプションとなりますが、意図しないインデックスやソースタイプで取り込まれるのを防ぐために、必ず指定するようにしてください。
- 取り込みファイルパスには、取り込み対象のファイルをフルパスで指定してください。
- 複数ファイルを取り込む場合、"*" などのワイルドカードは利用できないため、1ファイルずつフルパスを指定して実行してください。
コマンドオプション
- -sourcetype <ログのソースタイプ>
- 取り込み時のソースタイプを指定する場合に使用します。指定しない場合には、取り込み時に自動認識されたソースタイプが設定されます。
- -index <取り込み先インデックス>
- 取り込み先インデックスを指定する場合に使用します。指定しない場合には main インデックスに取り込まれます。
- -hostname <ホスト名>または-host <ホスト名>
- 取り込み時のホスト名を指定する場合に使用します。指定しない場合にはサーバーのホスト名が設定されます。
※以下のファイルはログ内の情報からホスト名を取得していますのでオプション指定できません。
- *.evtxファイル
- syslogファイル(-sourcetype syslogを指定した場合)
- -hostregex <正規表現>または-host_regex <正規表現>
- ファイルのフルパスの一部を、ホスト名として抽出する際に指定します。正規表現内の、最初の括弧()内にマッチした部分がホスト名となります。正規表現がファイルパスにマッチしない場合は、サーバーのホスト名が設定されます。
- -hostsegmentnum <パス階層数>または-host_segment <パス階層数>
- ファイルのフルパスに含まれるディレクトリ名またはファイル名を、ホスト名として抽出する際に指定します。
例えば以下のようにオプション指定をした場合、上位から3階層目のディレクトリ名である、"splunk-server" がホスト名として設定されます。
- ファイルのフルパスに含まれるディレクトリ名またはファイル名を、ホスト名として抽出する際に指定します。
<Linuxでの例>
$SPLUNK_HOME/bin/splunk add oneshot
/var/log/splunk-server/messages.log -hostsegmentnum 3<Windowsでの例>
$SPLUNK_HOME\bin\splunk add oneshot
C:\var\log\splunk-server\messages.log -hostsegmentnum 3※Windows の場合はドライブ指定を除いた階層数の指定になります。
- -rename-source <ソース>
- 取り込み時のソースの値を指定します。指定しない場合にはファイルのフルパスが設定されます。
- -auth <ユーザー名>:<パスワード>
- 取り込み時のユーザー認証に利用するユーザー名とパスワードを指定します。指定していない場合には、コンソール上でユーザーとパスワードの入力を求められますので、Splunk の admin ユーザーで認証してください。
以上
サーチバーで利用できるショートカットキー
- 公開日
- 2019-08-29
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- Splunk Web上のサーチバーでは、いくつかのショートカットキーが用意されています。
ショートカットキーの利用によりサーチ文の編集やその他の操作を実行できます。
- 参考情報
- 内容
-
サーチ文の編集
# ショートカットキー 機能 1 Ctrl+\ サーチ文の整形
(パイプ区切りで改行され、更にサブサーチはインデントされる)2 Ctrl+Z 直前のサーチ文の編集操作を取り消し 3 Ctrl+Y もしくは
Ctrl+Shift+Z"Ctrl+Z"で取り消したサーチ文の編集操作の再実行 4 Shift+Enter カーソル行の下に空行を追加 5 Alt+Shift+上矢印 カーソル行を1行上にコピー 6 Alt+Shift+下矢印 カーソル行を1行下にコピー 7 Alt+上矢印 カーソル行を1行上に移動 8 Alt+下矢印 カーソル行を1行下に移動 9 Ctrl+D カーソル行の削除
(カーソル行が改行を含まずに複数行にまたがっている場合、複数行全体が削除される)10 Alt+Delete カーソル行のカーソル位置から行末までの削除 11 Alt+Backspace カーソル行のカーソル位置から行頭までの削除 12 Ctrl+Delete カーソル位置右側の単語もしくはスペースの削除 13 Ctrl+Backspace カーソル位置左側の単語もしくはスペースの削除 その他の操作
# ショートカットキー 機能 1 Ctrl+Shift+E サーチマクロや保存済みサーチの内容の展開 2 Ctrl+F 検索用ウィンドウの表示
(サーチ文が複数行にまたがる場合に使用可能)3 Ctrl+H 検索/置き換え用ウィンドウの表示 4 Ctrl+Space サーチアシスタントウィンドウ(入力補助機能)の表示 5 ALT+P サーチ履歴からひとつ前のサーチを表示 6 Alt+N サーチ履歴からひとつ後のサーチを表示 以上
検索時に小数点以下を切り捨て/四捨五入する方法
- 公開日
- 2019-08-06
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.1.0
- 概要
- evalコマンドを利用することで、小数点以下の数値を切り捨て/四捨五入することが可能です。統計の結果やログ内の数値を切り捨て/四捨五入する際にご利用ください。切り捨て/四捨五入をするには、evalコマンドのfloorやround関数を利用します。
- 内容
-
小数点以下を切り捨てる方法
- 利用する関数
floor() - 利用方法
...| eval <結果を入れるフィールド名>=floor(<数値もしくは切り捨てしたいフィールド名>)
例:
...| eval n=floor(1.9)
※nには「1」が返されます。
...| eval XXX=floor(AAA)
※AAAフィールドの値が「1.9」の場合、XXXフィールドには「1」が返されます。
小数点以下を四捨五入する方法
- 利用する関数
round() - 利用方法
...| eval <結果を入れるフィールド名>=round(<数値もしくは切り捨てしたいフィールド名>)
もしくは
...| eval <結果を入れるフィールド名>=round(<数値もしくは切り捨てしたいフィールド名>,四捨五入する位)
例:
...| eval n=round(3.5)
※nには「4」が返されます。
...| eval n=round(2.555, 2)
※nには「2.56」が返されます。
...| eval XXX=round(AAA, 2)
※AAAフィールドの値が「2.555」の場合、XXXフィールドには「2.56」が返されます。
以上
- 利用する関数
earliest/latest を利用した相対的な日時範囲の指定方法
- 公開日
- 2017-10-20
- 最終更新日
- 2024-07-01
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- earliest/latest を利用して、サーチ文で相対的な日時範囲を指定できます。
- 内容
-
earliest および latest を使用することで、サーチ文で相対的な日時範囲を指定することができます。
このサーチ文での日時範囲の指定は、タイムレンジピッカーの指定よりも優先されます。
earliest と latest を利用した日時範囲の指定
サーチするイベントの日時の範囲を絞り込む場合、earliest で開始日時を、latest で終了日時を指定できます。
この earliest および latest には様々な指定方法がありますが、現在の日時を基準にした、相対的な日時を指定する例をご紹介します。
- earliest=-12h
直近12時間のイベント - latest=-3d
3日以上前のイベント - earliest=-1w@w latest=-0w@w
先週一週間(日曜日~土曜日)のイベント - earliest=-3mon@y+3mon latest=-3mon@y+15mon
今年度(4/1~3/31)のイベント
このように、earliest および latest を使用することで、日時の範囲を指定できます。
また、latest を省略した場合は現在時刻までのイベントをサーチできますが、明示的に latest=now と指定することもできます。
日時の単位の種類と"@"(アットマーク)については次項を参照ください。
日時単位の種類と使い方
使用可能な日時単位の種類は以下の通りです。
- 年 : y
- 月 : mon
- 週 : w
- 日 : d
- 時 : h
- 分 : m
- 秒 : s
例えば、3日前を指定する場合は -3d、4ヶ月前を指定する場合は -4mon と指定します。また、1週間前を指定する場合など、数値が1の場合は -w のように省略することもできます。
日時範囲を丸める(端数を切り捨てる)方法
日時指定をする際に、@(アットマーク)を使用することで、指定した日時を丸める(端数を切り捨てる)ことができます。
単純に -1mon などと指定すると、実行した日の 1ヶ月前の同日の同時刻を指定したことになりますが、この機能を利用することで「先月の一か月間」などの指定ができるようになります。
例えば、サーチを実行した日時が 9/21 9:37 の場合を例に挙げると、サーチされる時間の範囲は以下のようになります。
- earliest=-1mon
8/21 9:37 以降のイベント - earliest=-1mon@mon
8/1 0:00 以降のイベント - earliest=-1mon@d
8/21 0:00 以降のイベント
例えばもし、日時範囲の指定として先月(8月)いっぱいを指定したい場合には、earliest=-1mon@mon latest=-0mon@mon と指定することで実現できます。
また、現在時刻をそのまま丸める場合には latest=@d のように相対的な日時指定を省略できます。
以上
- earliest=-12h
元号の変更や国民の祝日の追加・変更の影響
- 公開日
- 2017-08-07
- 最終更新日
- 2024-07-01
- バージョン
- Splunk Enterprise 9.0.5
- 概要
- Splunkでは和暦は使用されていないため、元号が変わった場合や国民の祝日が追加・変更された場合のいずれにおいても影響はございません。
- 内容
-
Splunk EnterpriseおよびSplunk Universal Forwarderでは、和暦は使用されておりません。タイムスタンプのフォーマットで年を指定する為に用意されているのは、以下の2種類の変数のみとなります。
- %y - 世紀を含まず下2桁のみ(00~99)
- %Y - 西暦表示(2017など)
こちらの変数については参考情報のドキュメントをご覧ください。
以上
CLIからsplunkのアラート設定を有効化/無効化する方法
- 公開日
- 2017-01-11
- 最終更新日
- 2023-06-02
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- CLIからアラートの設定を有効化/無効化する方法
- 内容
-
splunkに設定したアラートを下記のCLIコマンドで有効化/無効化することが出来ます。
アラートを無効化する場合
curl -ku <username>:<password>
https://<server_IP>:8089/servicesNS/<owner-name>/
<app-name>/saved/searches/<saved-search-name> -d "disabled=1"アラートを有効化する場合
curl -ku <username>:<password>
https://<server_IP>:8089/servicesNS/<owner-name>/
<app-name>/saved/searches/<saved-search-name> -d "disabled=0"※<owner-name>、<app-name>、<saved-search-name>には設定を無効にしたいアラートの所有者、app名、アラート名を入力してください。詳細につきましては参考情報をご覧ください。
以上
ユーザーのタイムゾーンを設定した場合の動作
- 公開日
- 2015-11-12
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- サマータイムを導入しているタイムゾーンを設定した場合、サマータイム期間はサマータイム表示となります。
- 参考情報
- 内容
-
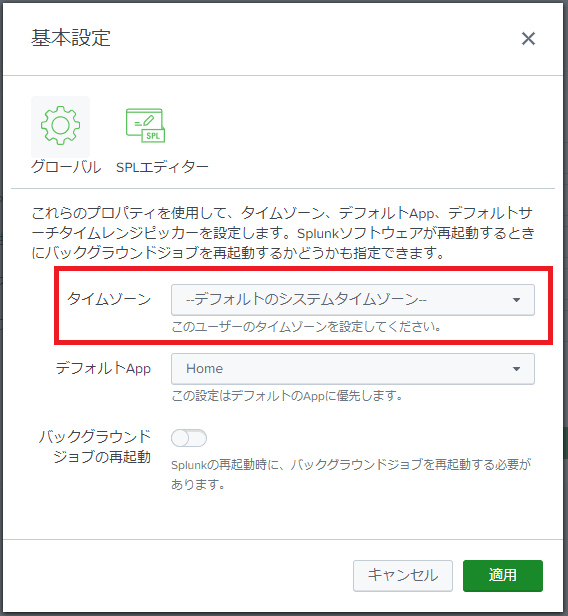
Splunk Webのアカウント名>基本設定>グローバルより、アカウントの「タイムゾーン」を変更すると、他のタイムゾーンで取り込まれたログのタイムスタンプも、設定したタイムゾーンの時間で表示されます。
設定したタイムゾーンがサマータイムを導入している場合、サマータイム期間中はサマータイム表示となります。
※参考画像:タイムゾーン設定画面
以上
うるう秒によるSplunk Enterpriseの動作への影響について
- 公開日
- 2015-06-22
- 最終更新日
- 2023-06-30
- バージョン
- Splunk Enterprise 9.0.5
- 概要
- タイムスタンプがうるう秒のイベントを取り込んだ場合の影響として、タイムスタンプがうまく認識できずにイベントが複数行になってしまうことや、タイムスタンプが実際と異なる値で認識されることが考えられます。
- 内容
-
うるう秒によるSplunkのサービスの停止などの影響はありません。
しかし、Splunkはうるう秒をタイムスタンプとして認識しません。タイムスタンプがうるう秒の場合に考えられる影響として、下記2つがあります。
タイムスタンプが認識できず、イベントが複数行になってしまう可能性があります。
タイムスタンプが実際のタイムスタンプと異なる値で認識されます。
イベントが複数行になる場合について
Splunkはデフォルトの設定では、イベント区切りをタイムスタンプとしています。
複数行を1イベントと設定している場合、区切り文字を明示的に指定しているため影響はありません。1行1イベントでデータが出力されている場合、対象のデータ取り込み設定のソースタイプに対して、props.confに"SHOULD_LINEMERGE=false"※が明示的に定義されていないと、タイムスタンプが認識できず、イベントが複数行になってしまう可能性があります。
※「SHOULD_LINEMERGE=false」という設定は1行1イベントとして取り込むための設定です。このデフォルトの値は「true」であり、またBREAK_ONLY_BEFORE_DATEという設定が「true」になっているため、タイムスタンプの前でイベントを区切ります。タイムスタンプが認識できない場合、1行はLINE_BREAKERという設定に定義されている正規表現によって判断されます。LINE_BREAKERのデフォルトの値は ([\r\n]+)です。
認識されるタイムスタンプが実際と異なる場合について
Splunkが取り込んでいるログやデータに8:59:60秒(うるう秒)のように、""60""が表示されたタイムスタンプが出力された場合、下記の動作をします。その後は、1.~4.の順で該当するものが適用され、処理されます。
- Splunkがイベントのタイムスタンプ(日付+時間)を認識できない場合、同じソースの最新イベントと同じタイムスタンプで認識します。
例えば、2015年7月1日 8時59分60秒の前が59秒のイベントであれば、60秒のタイムスタンプは認識できないため、直前の2015年7月1日8時59分59秒として認識します。 - Splunk Enterpriseの取り込み対象のログファイル等にイベントの時刻のみ(日付情報が無い)が含まれている場合、ログファイルのファイル名やソース名から日付の情報を適用します。
- 上記2.に該当しない場合は、Splunkはファイルの更新日付をイベント取り込み時に適用します。
- 上記のいずれの対応もできない場合、Splunkはイベント取り込み時のシステム時間を適用して取り込みます。"
以上
- Splunkがイベントのタイムスタンプ(日付+時間)を認識できない場合、同じソースの最新イベントと同じタイムスタンプで認識します。
Splunkへのログイン、またはログアウトを行ったユーザーを管理者が特定する方法
- 公開日
- 2017-04-06
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- Splunkへのログイン、またはログアウトを行ったユーザーを管理者が特定する方法を紹介します。
- 内容
-
ログイン/ログアウト時に出力される内部ログについて
ユーザーがSplunkにログイン、またはSplunkからログアウトすると、Splunkの内部ログにデータが書きこまれます。
Splunkでは自身の内部ログを、取り込んだデータと同様にSplunkにて検索できるため以下の検索をすることで、ユーザーのログイン/ログアウト状況を把握することが出来ます。
ログイン/ログアウト時に出力されるログを検索する検索文
○ログイン
以下の検索文にて、ログインした際に出力されるログを検索することが出来ます。
index="_audit" action=log* action="login attempt"【サンプルログ】
Audit:[timestamp=02-20-2023 14:41:59.309, user=admin, action=login attempt, info=succeeded reason=user-initiated useragent=xxxxxxx clientip=xx.xxx.xx.xxx method=Splunk session=xxxxxxxxxxx]○ログアウト
Splunkから“ログアウト”を選択してログアウトした際に出力されるログは、以下の検索文にて検索することができます。
index="_audit" action=log* action="logout"【サンプルログ】
Audit:[timestamp=02-20-2023 14:43:07.949, user=admin, action=logout, info=succeeded reason=user-initiated useragent=xxxxxxx clientip=xx.xxx.xx.xxx session=xxxxxxxxxxx]※注意
ブラウザを閉じてSplunkとのセッションを切断した場合には、ログアウトログは出力されません。以上
SplunkにおけるApache Strutsの利用有無
- 公開日
- 2018-05-30
- 最終更新日
- 2023-12-11
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- SplunkにおけるApache Strutsの利用有無
- 内容
-
SplunkではApache Strutsを利用していません。
WebアプリケーションフレームワークとしてCherryPyを利用しています。
詳細は「参考情報」に記載されているサードパーティ製品の一覧をご確認ください。
以上
Splunkのcronの動作
- 公開日
- 2018-06-14
- 最終更新日
- 2024-07-01
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- Splunkではスケジュールアラートなどで、cronでの実行時刻を指定することができます。Splunkのcron動作はバージョンによって異なるため、実行時刻を指定する際はご注意ください。
- 内容
-
バージョンごとの差異
7.2.1以前
Splunkのcron動作は、一般的なLinuxのcron動作と異なる点があります。
Linux:第3フィールドと第5フィールドがOR条件で動作します。
Splunk:第3フィールドと第5フィールドがAND条件で動作します。例)0 9 15-21 * 1 の場合
(第1フィールド:分、第2フィールド:時、第3フィールド日、第4フィールド:月、第5フィールド:曜日)
- Linux:
15日〜21日 または 月曜日 と判断され、15日〜21日のAM9時と、毎週月曜日のAM9時に実行されます。 - Splunk:
15日〜21日 かつ 月曜日 と判断され、15日〜21日の月曜日のAM9時に実行されます。
7.2.2以降
Splunkのcron動作は、一般的なLinuxのcron動作と同じです。
Linux・Splunk:第3フィールドと第5フィールドがOR条件で動作します。例)0 9 15-21 * 1 の場合
(第1フィールド:分、第2フィールド:時、第3フィールド日、第4フィールド:月、第5フィールド:曜日)
- Splunk、Linux:
5日〜21日 または 月曜日 と判断され、15日〜21日のAM9時と、毎週月曜日のAM9時に実行されます。
7.2.1以前と同じタイミングでアラートを実行する方法
7.2.1以前(7.0系、7.1系)のバージョンでスケジュールアラートのcronの実行時刻を「0 9 15-21 * 1 」のように設定していた場合、最新版へのバージョンアップ後にアラートの実行時刻が変わります。
バージョンアップ前と同様に毎月15日〜21日の月曜日のAM9時にアラートを実行する場合はアラートの設定を以下のように変更します。
手順
SplunkWebにログインします。
[設定]-[サーチ、レポート、アラート]画面に移動します。
対象アラートの編集画面を開き、サーチに判定条件を追加します。<変更例>
・サーチ
(既存のサーチ文)| eval daynum=strftime(now(),"%d"),
| eval weekday=strftime(now(),"%a"),
| eval isThirdMonday=if(weekday=="Mon" AND daynum>14 AND daynum<22,"true","false" )
| search isThirdMonday="true"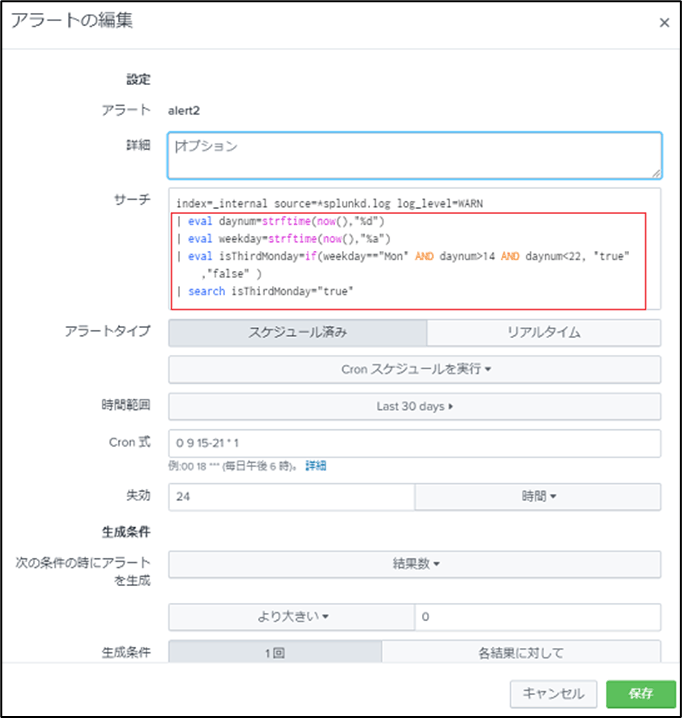
以上
- Linux:
英字の大文字と小文字を区別して検索する方法
- 公開日
- 2016-10-17
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- 英字の大文字と小文字を区別して検索する方法
- 内容
-
キーワード検索について
Splunkではキーワードを検索する際に、英字の大文字と小文字の区別を行いません。
例えば、"error"というキーワードにて検索を実施すると、小文字のerrorというキーワードを含むデータだけではなくERROR、Errorなどのキーワードを含むデータを検索結果に出力します。
CASE()について
大文字と小文字の区別をつけて検索を実施する際には、CASE()を使用して検索を実施します。
例えば、CASE(error)のように検索を実施すると、小文字のerrorというキーワードを含むデータだけを検索結果として出力しERROR、Errorなどのキーワードを含むデータは検索結果に出力しません。
またCASE()を使用すると、使用しない場合よりも検索速度は遅くなる可能性がございます。
以上
簡易的なダミーデータを作成する方法
- 公開日
- 2017-01-30
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- 簡易的なダミーデータを作成する方法について説明します。
- 内容
-
ダミーデータについて
検索コマンドの動作確認をするためにサンプルデータが必要な場合、makeresultsコマンドを利用することでデータの取り込み設定などを実施せずに、サンプルデータを生成することができます。
尚、makeresultsコマンドを利用した場合、データはインデックスされませんので実施検索内でのみ利用可能なデータとなります。
makeresultsコマンドについて
makeresultsコマンドは、検索が実行された時刻を画面に表示するコマンドです。
以下のように検索を実施することで、使用できます。
| makeresults※|(パイプコマンド)を検索文の一番初めに記載します。
evalコマンドと併用することで、別のフィールドを作成することも可能です。
例:
| makeresults | eval user="Taro", ip="1.1.1.1"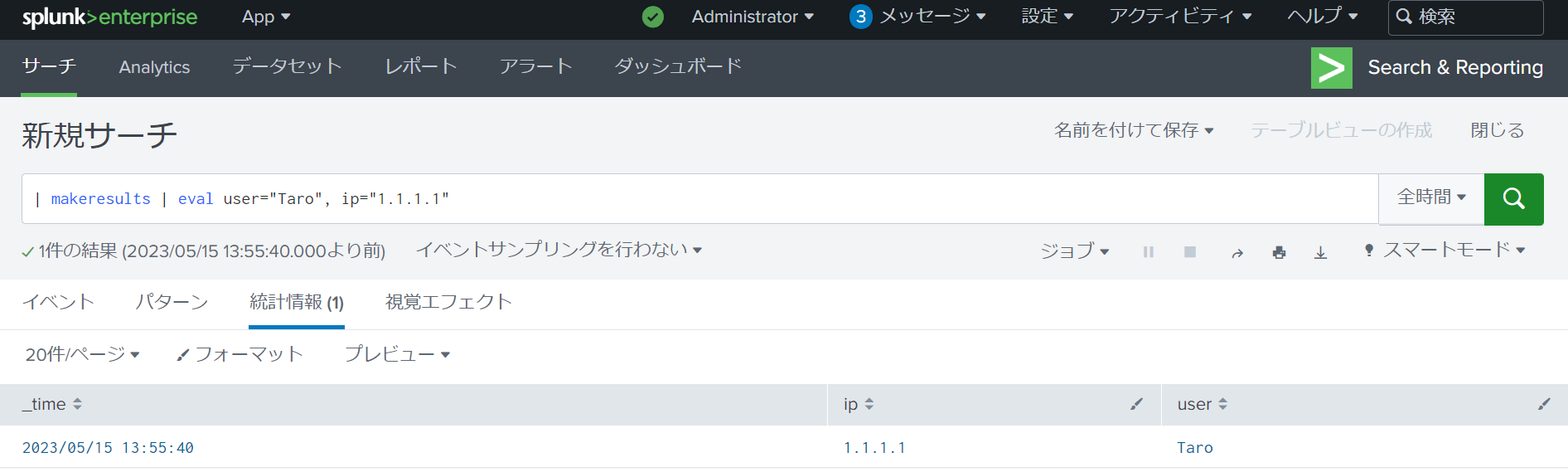
以上
統計情報の列の順番を入れ替える方法
- 公開日
- 2017.12.06
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- tableコマンドを用いて、統計情報の列の順番を入れ替えることができます。
- 内容
-
統計情報の出力結果について
Splukにて統計情報を分析した場合、出力結果の列の順番はコマンドによって異なります。
任意の列の順番に並び替えるにはtableコマンドを利用します
tableコマンドについて
tableコマンドでは引数に取ったフィールド名順に、列を並び替えます。
コマンド例:
<任意のサーチ文> | table field1, filed2, field3
上記の場合、field1,field2,field3の順で、列を入れ替えます。例えば、以下のようなコマンドを実行したとします。
コマンド例:
sourcetype=access_combined_wcookie
| stats count sum(bytes) as size by clientip,action実行した結果は以下のようになります。
以上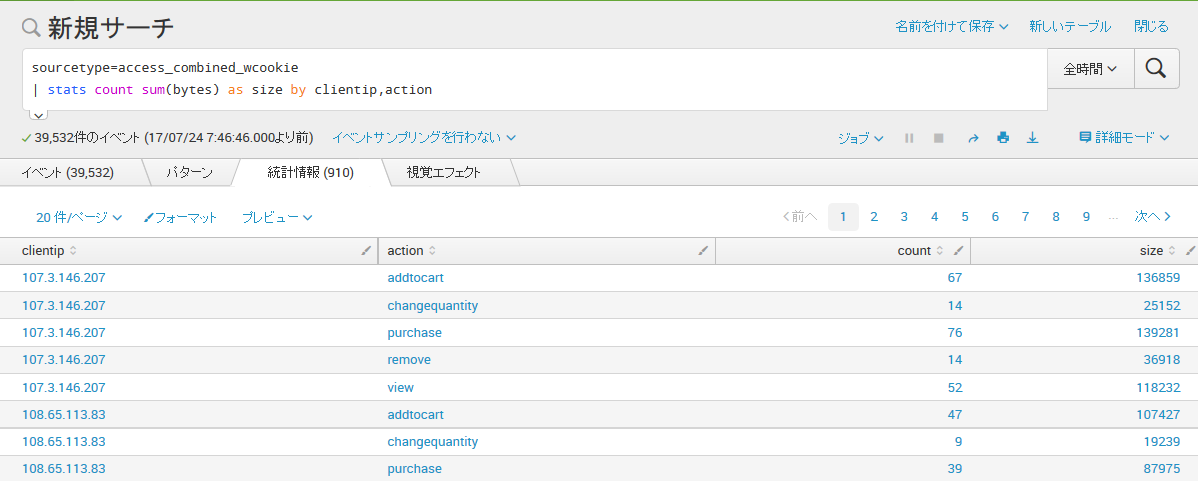
検索ボックスの背景の色を変更する方法
- 公開日
- 2018-03-23
- 最終更新日
- 2023-12-11
- バージョン
- Splunk Enterprise 9.1.1
- 概要
- 検索ボックスの背景の色を変更する方法
- 参考情報
- 内容
-
検索ボックスの色について
検索に利用する検索ボックスは、デフォルトで白背景であり、検索文を書きこむと検索コマンドや論理演算子が色分けされて表示されます。

この色の組み合わせを以下の3つから選択することが出来ます。
- デフォルトのシステムテーマ(ライトのテーマがデフォルトして設定されています。)
- ライト
- ダーク
- 白地に黒
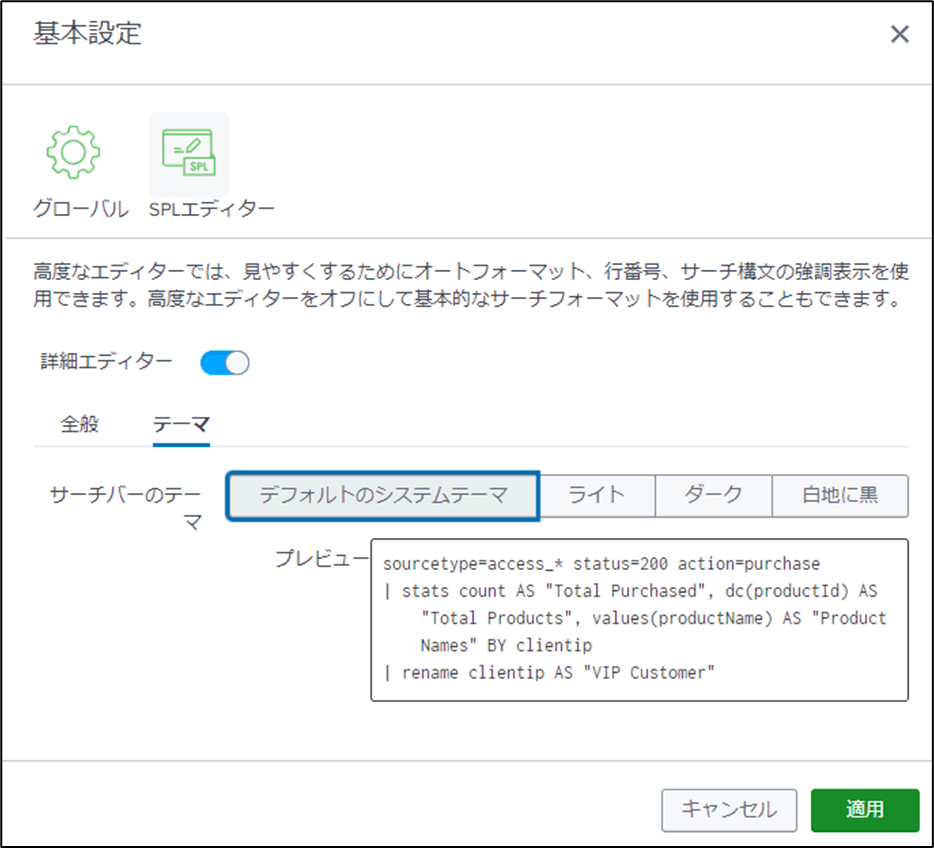
検索ボックスの色の変更方法
以下の手順で、検索ボックスの色を変更することが可能です。
- SplunkWebにログインします。
- Splunkバーの「ユーザー名」>「基本設定」を選択します。
- 「SPLエディター」タブの「詳細エディター」を有効にします。
- 「テーマ」タブの「サーチバーのテーマ」により、変更したいテーマを選択します。
- 「適用」を選択します。
例えば、ダークを選択すると以下のようになります。

以上
圧縮ファイルの取り込み時のライセンス消費の考え方
- 公開日
- 2018-08-01
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- 圧縮したファイルをSplunkに取り込みを行った際のライセンス消費の考え方について説明します。
- 参考情報
-
- Configure Splunk licenses
https://docs.splunk.com/Documentation/Splunk/9.1.2/Admin/HowSplunklicensingworks
- Configure Splunk licenses
- 内容
-
Splunkは圧縮したファイルの取り込みを行った場合、解凍後のファイルサイズ(生データのサイズ)でライセンス消費の計算が行われます。
例)
圧縮状態testdata.zip 200MB
解凍後testdata.csv 1GB上記の場合はライセンスの消費量は「1GB」となります。
以上
LookupテーブルでCIDRマッチする方法
- 公開日
- 2016-10-11
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- LookupテーブルでCIDRマッチする方法
- 内容
-
Lookupテーブルを利用したCIDRマッチの方法
$SPLUNK_HOME/etc/apps/
/local/transforms.confに以下を設定することによりCIDRマッチを利用した検索ができます。 [<Lookup定義名>]
match_type = CIDR(Lookupフィールド名)・手順内の$SPLUNK_HOMEのパスについて
手順内の$SPLUNK_HOMEはSplunkのインストールディレクトリです。
デフォルトでは以下です。---------
Linux : /opt/splunk
Windows : C:\Program Files\Splunk
---------【設定例】
- ルックアップテーブルを作成します。
例)ipam.csv
---------
src_ip,Dept
10.8.1.0/18,Dept1
10.17.101.0/16,Dept2
---------※文字コードUTF-8(BOM無)で保存します。
※SplunkのWeb画面の設定>ルックアップ>ルックアップテーブルファイルよりファイルをアップロードします。
もしくは$SPLUNK_HOME/etc/apps/<app_name>/lookups/ に配置します。
(Search&Reportで使用する場合は<app_name>はsearchとなります。)- ルックアップ定義を行います。
$SPLUNK_HOME/etc/apps/<app_name>/local/transforms.confファイルを直接編集(存在しない場合は新規作成)して、下記を設定します。
例)transforms.conf
---------
[ipam]
filename = ipam.csv
match_type = CIDR(src_ip)
---------※filenameには配置したファイル名を指定します。
※transforms.confファイルlookupテーブルの詳細につきましては下記をご参照ください。
https://docs.splunk.com/Documentation/Splunk/9.0.4/Admin/Transformsconf#Lookup_tables- 必要に応じて、自動ルックアップ設定を行います。(必須ではありません)
例)props.conf
---------
[my_sourcetype]
#既存設定の下に下記を追加
LOOKUP-ipam = ipam src_ip OUTPUTNEW Dept AS Department
---------※設定する際にはSplunkのWeb画面の設定>ルックアップ ≫ 自動ルックアップにて設定するか、上記のように$SPLUNK_HOME/etc/apps/<app_name>/local/props.confファイルを直接編集し、既存設定の下に自動ルックアップの設定を追記します。(上記はイベント内のフィールド名とlookupテーブルのフィールド名が同一の場合の定義です)
以上
Splunkに取り込まれたデータの圧縮率を調べる方法
- 公開日
- 2016-11-14
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- Splunkに取り込まれたデータの圧縮率を調べる方法
- 参考情報
- 内容
-
取り込みデータの圧縮について
Splunkは取り込み対象のデータを、約50%程度に圧縮してファイルシステム上に保存します。この50%の圧縮率は目安であり、実際の圧縮率はデータによって異なります。
そのため、ハードウェアの選定などを行う際には事前に取り込み対象のデータがどの程度に圧縮されてSplunkに取り込まれるかを確認する必要があります。
※1. Splunkはデータを保存する際に、インデックスファイルとrawデータファイルを作成します。rawデータは取り込み対象ファイルの10%程度、インデックスファイルは取り込み対象ファイルの10~110%程度の大きさで作成されるため、50%程度の圧縮率にならない場合があります。
※2. 日本語(ダブルバイト文字)が含まれるデータや、取り込み時にフィールドを抽出している場合インデックスファイルが大きくなる場合があります。
詳細は下記のドキュメントをご覧ください。
※1.の圧縮率について
https://docs.splunk.com/Documentation/Splunk/6.5.0/Capacity/Estimateyourstoragerequirements※2.のフィールド抽出について
http://docs.splunk.com/Documentation/Splunk/6.5.0/Data/Aboutindexedfieldextraction取り込みデータの圧縮率の調べ方について
管理コンソールを使用することにより、インデックスごとの圧縮率を調査することが出来ます。
以下に手順を記載します。
データ圧縮率調査手順
- SplunkWebにアクセスし、設定 > インデックス > 新規インデックスより新規のインデックスを作成します。
- 圧縮率の確認をするデータを1)で作成したインデックスに保存します。
※圧縮率を確認されたいデータが、既に特定インデックスに保存されている場合には、1)及び2)の手順を飛ばしてください。 - 設定 > モニターコンソールを選択します。
- ナビゲーションメニューより インデックス化 > インデックス詳細:インスタンスを選択します。
- 入力フォームのインデックスより、1)で作成したインデックスを指定します。
- 概要のダッシュボードの以下の項目を確認します。
- Index Size
-
- Splunkに保存されている圧縮後のデータサイズ
- Uncompressed Raw Data Size
-
- 実データサイズ
- Raw to Index Size Ratio
-
- 圧縮後のデータサイズと実データサイズの比率
※例えば2:1の場合、圧縮率は50%であることが分かる
- 圧縮後のデータサイズと実データサイズの比率
以上
ロールの仕様および作成手順
- 公開日
- 2015-05-06
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- デフォルトロールの仕様説明、ロールの新規作成手順
- 参考情報
- 内容
-
デフォルトロールの仕様説明
Splunkにデフォルトで用意されているロールは以下の4種類です。
- admin:
管理者用ロールです。データの取り込みや設定変更などの管理に必要な権限が割り当てられています。 - power:
サーチやアラート、タグ、イベントタイプを他のユーザーと共有することを許可されたロールです。 - user:
一般ユーザー用ロールです。基本的に、管理者に用意された環境で検索を行うことを想定し、設定変更は許可されません。 - can_delete:
取り込んだデータに対して、deleteコマンドの実行が許可されたロールです。
なお、「splunk-system-role」はシステム内部で使用するロールとなり、ユーザに割り当てることは推奨しておりません。
権限はadminロールと同じですが「サーチの制限」の設定が異なり、例えば、adminと比べてサーチ時間範囲や同時サーチジョブ数などが制限されています。
具体的な違いにつきましては、Splunk Webの下記設定よりご確認ください。
- 設定>ロール>admin の「サーチの制限」
- 設定>ロール>splunk-system-role の「サーチの制限」
ロールの新規作成手順
細かい権限をユーザーに割り当てたい場合には、新規のロールを作成し、割り当てたい権限を選択する必要があります。
割り当てたい権限を決定後、下記の設定手順にて新規のロールを作成します。
【新規ロール設定手順】
- adminユーザーにてSplunk Webにアクセスします。
- 「設定」>「ロール」>「新しいロール」をクリックします。
- 「1. 継承」および「2. 権限」リストから利用したい権限にチェックをします。
- 「4.インデックス」タブにて作成中のロールが割り当てられるユーザーが検索できるインデックスを指定します。
ロールを作成後、下記の設定手順にて、ユーザーにロールを割り当てます。
【新規ユーザー作成手順】
- adminユーザーにてSplunk Webにアクセスします。
- 「設定」>「ユーザー」>「新規ユーザー」をクリックします。
- 「選択されたロール」に割り当てたいロールを選択し、「保存」をクリックします。
上記設定によって、ロールの作成とそれを割り当てるユーザーを作成することが可能となります。
以上
- admin:
outputcsvコマンドの利用方法
- 公開日
- 2015-06-01
- 最終更新日
- 2025-04-16
- バージョン
- Splunk Enterprise 9.4.0
- 概要
- outputcsvコマンドの利用方法
- 参考情報
- 内容
-
検索結果の出力
SplunkではSplunkWeb上で実行した検索の結果を、CSV形式にてSplunkサーバー内の$SPLUNK_HOME/var/run/splunk/csv配下に出力することが可能です。
※$SPLUNK_HOMEのパス情報(デフォルトインストールの場合)
Linux OS:/opt/splunk
Windows OS:C:\Program Files\Splunk出力方法
検索結果の出力には、outputcsvコマンドを使用します。
outputcsvコマンドを使用すると、splunkの検索結果で得られたrawデータや統計情報をCSV形式でサーバー上に保存することが可能です。
使用方法
| outputcsv <保存するファイル名>.csv使用例
index=_internal | head 10 | table host,source | outputcsv test.csv上記のコマンドを実行すると、test.csvというファイルが出力されます。
※outputcsvコマンドはリスクの高いコマンドに指定されている為、実行時に警告が出力されます。警告が出力されると「キャンセル」「実行」「調査」から次のアクションを選択でき、「実行」を選択するとそのままコマンドが実行されます。詳細については、下記のSplunk社公式ドキュメントをご参照ください。
https://docs.splunk.com/Documentation/Splunk/9.4.0/Security/SPLsafeguards
SplunkWeb上での出力結果の確認方法
上記手順にて出力されたCSVファイルは、SplunkWeb上でinputcsvコマンドを使用することによって中身を見ることができます。
- inputcsvコマンド使用例
コマンド例
| inputcsv test.csv上記のコマンドを実行すると、test.csvファイルの中身を画面上に表示させることが可能です。
以上
マクロ機能を利用して、検索文を簡略化して表示する方法
- 公開日
- 2015-05-07
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- マクロを利用して、よく利用する検索文を簡略化します。
- 内容
-
マクロとは、コマンドも含めた検索文字列をまとめて保存することができる機能です。検索文に `マクロ名` を加えることで、設定した検索文字列が検索条件に追加されます。
よく使う検索条件が長い場合、マクロを利用することで検索条件を記述する手間を省くことが可能です。
マクロ利用例および設定例
利用例: 2023/4/1 00:00:00 から 2023/4/2 01:00:00 および 2023/4/2 08:55:00 から 2023/4/2 09:00:00 の範囲の全てのイベントを検索対象から除外します。
設定手順
Splunk Webにて設定を行います。
- 画面右上の設定>ナレッジ 詳細サーチ>サーチマクロにて、新規作成をクリックします。
- 任意の宛先Appを選択します。
- 名前欄にマクロ名を記入します。ここで設定した名前を検索時に使用します。
※使用できる文字は英数字、アンダースコア(_)、ダッシュ(-)です。 - 定義欄に以下を記入します。
NOT ((_time > 1427814000 _time < 1427817600) OR (_time > 1427932500 _time < 1427932800)) - 設定を保存します。任意でサーチマクロの画面にて、共有中の権限をクリックし、作成したマクロの権限を追加します。
- 検索文に`<マクロ名>`を追加し、検索を実行します。
検索例: index=test ERROR `macro`
以上
検索文内でインデックスを指定しなかった場合の動作
- 公開日
- 2015-11-19
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- 検索文内でインデックスを指定しない場合、検索対象となるインデックスは各ロールに設定されているものとなります。
- 内容
-
検索文内で「index=xxx」とインデックスを指定しない場合、検索対象となるインデックスは、各ロールに設定されている、デフォルトでサーチするインデックスとなります。
デフォルトでサーチするインデックスの確認方法
- admin権限を持つユーザーでログインし、Splunk Webの設定>ロールより、検索を実行したユーザーに設定されているロール名をクリックします。
- 参考画像内の「3. インデックス」より、デフォルトに選択されているインデックスを確認します。
参考画像
以下の画像では、デフォルト列の「main」にチェックが入っているため、検索文内でインデックスを指定しなかった場合、「main」インデックスをサーチします。
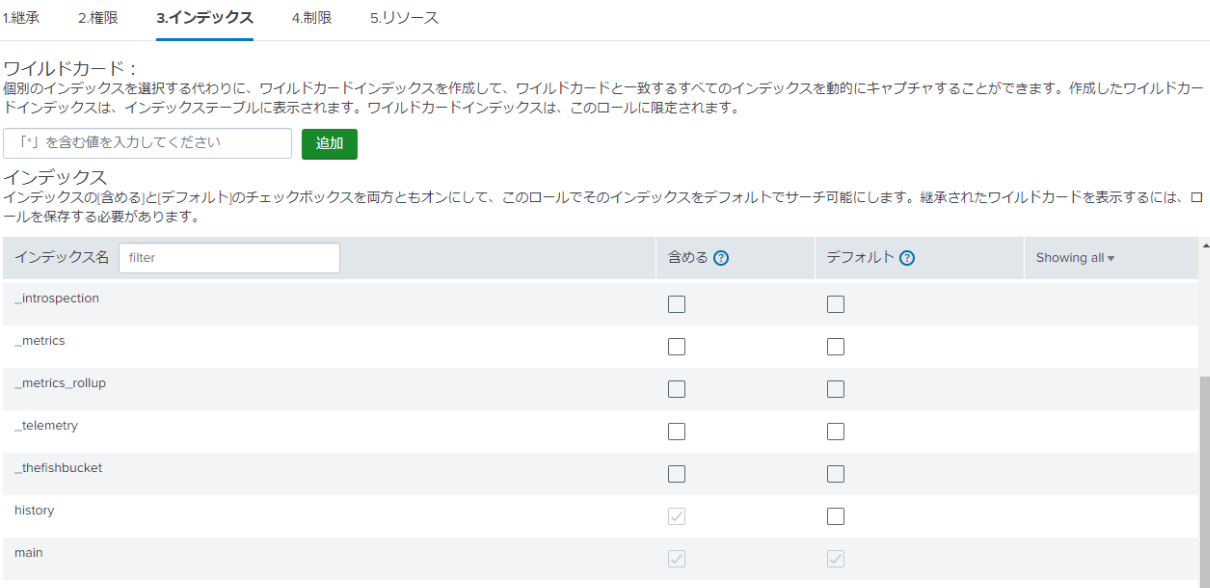
上記以外のインデックスを検索する場合には、検索文にてインデックス名を指定してください。
以上
タイムスタンプを認識する順番
- 公開日
- 2018-06-18
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.0
- 概要
- タイムスタンプを認識する順番・仕様を説明しています。
- 参考情報
-
- https://docs.splunk.com/Documentation/Splunk/9.0.0/Data/HowSplunkextractstimestamps
- https://docs.splunk.com/Documentation/Splunk/9.0.0/Data/Configurepositionaltimestampextraction
- https://docs.splunk.com/Documentation/Splunk/9.0.0/Data/Configuretimestamprecognition
- https://docs.splunk.com/Documentation/Splunk/9.0.0/Data/Configuredatetimexml
- 内容
-
タイムスタンプを認識する順番・仕様
Splunkは以下の順番でタイムスタンプを認識しようとします。
- イベント内に日時情報がある場合
①props.confで「TIME_FORMAT」が指定されている場合
明示された「TIME_FORMAT」を使ってイベント内のタイムスタンプを探そうとします。②props.confで「TIME_FORMAT」が指定されていない場合
イベント内からタイムスタンプを認識しようとします。- イベント内に日時情報がない場合
同じソースから取り込んだ直近のタイムスタンプを認識しようとします。
- ソース内に日時情報がない場合
Splunkはソース名やファイル名からタイムスタンプを認識しようとします。
- ファイル名に日時情報がない場合
ファイルの最終更新日時をタイムスタンプとして認識しようとします。
- datetime.xmlを使用して、イベントからタイムスタンプを認識しようとします。
- 上記1-5でもタイムスタンプを認識できない場合
Splunkサーバーのシステム時刻をタイムスタンプとして認識します。
(取り込んだ時間=そのイベントのタイムスタンプ)以上
特定の時間帯のイベントを簡単に検索する方法
- 公開日
- 2018-06-18
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- date_hourやdate_minute等のDefault datetime fieldsを使用して、特定の時間帯のイベントを検索することが可能です。
- 内容
-
使用例
9時から17時の間のタイムスタンプを持つイベントのみ検索したい場合、以下の条件を検索文に追加します。
date_hour>=9 AND date_hour<=17また、予めタイムレンジピッカーで特定期間を指定した上で上記フィールドを用いて検索することも可能です。
以上
円グラフ上に数値を%表示させる方法
- 公開日
- 2018-06-18
- 最終更新日
- 2018-06-18
- バージョン
- Splunk Enterprise 6.4.1
- 概要
- 円グラフ上に数値を%表示させるには、evalコマンドもしくはダッシュボードのオプションを使用する
- 参考情報
-
- evalコマンドについて
- 内容
-
検索結果を視覚エフェクトのタブで表示する際に、円グラフ上に値を表示したい場合には、各値の項目の後に値を表示するように検索文を作成する必要があります。
(検索文例)
index=_internal | top 5 component | eval percent=round(percent, 2) | eval component=component.", ".count.", ".percent."%"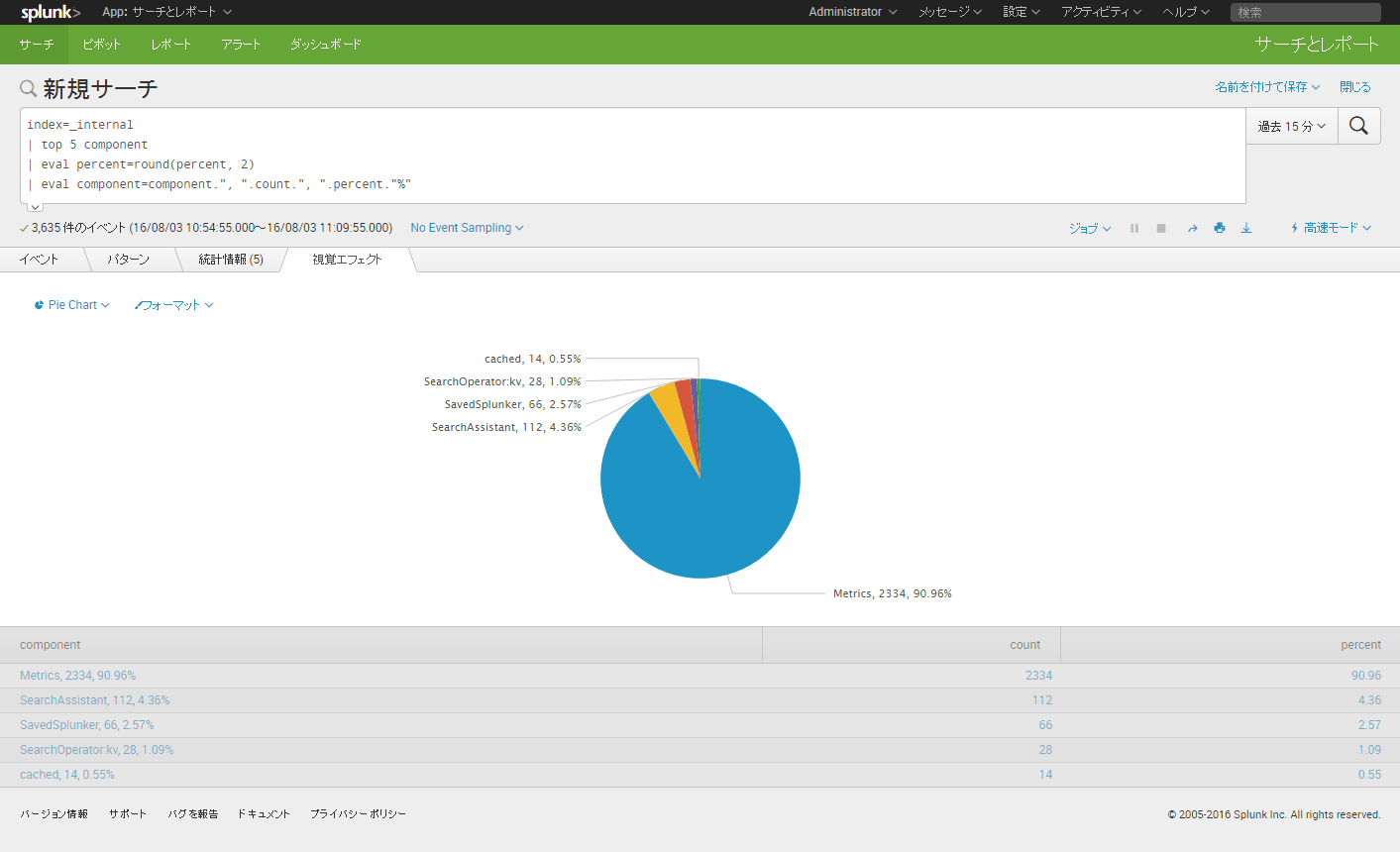
ダッシュボード上では、%値を表示する以下のオプションが利用できます。
<option name="charting.chart.showPercent">1</option>
こちらをxmlに追記することで、円グラフ上に%値を表示することが可能です。
なお、この方法では少数第3位まで表示されてしまいますので、表示桁数を変えたい場合には上記のようにevalコマンドのround関数等を利用して値を表示してください。
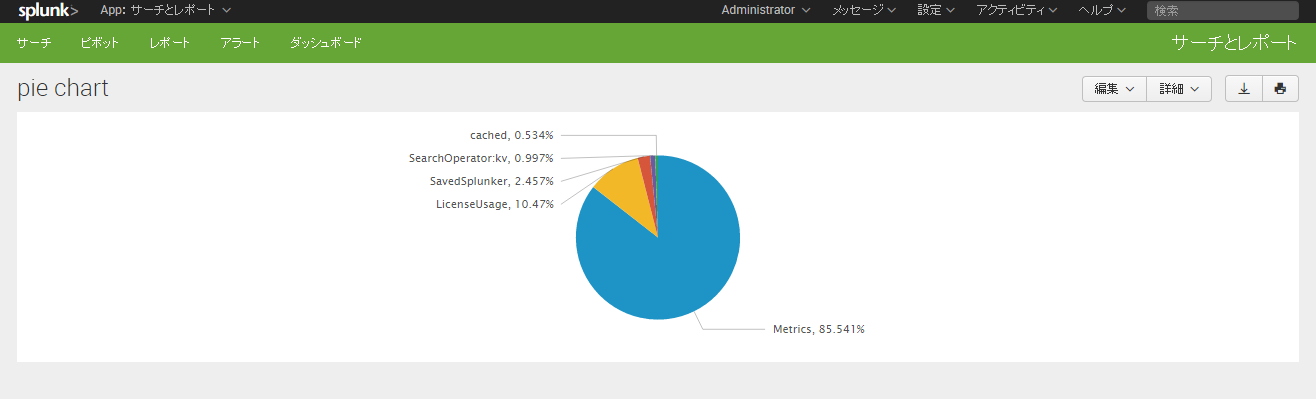
以上
deleteコマンドを使用して検索結果から任意のイベントを削除する(非表示にする)
- 公開日
- 2018-06-18
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- deleteコマンドを使用して検索結果から任意のイベントを削除する(非表示にする)方法
- 参考情報
- 内容
-
deleteコマンドを使って任意のイベントを検索結果から削除する(非表示にする)ことが可能です。特定のユーザーに対しcan_deleteのロールを付与することで、そのユーザーはdeleteコマンドを実行することができるようになります。
[手順]
- 設定>アクセス制御>ユーザーより、任意のユーザーを選択します。
- 手順1. で選択したユーザーに対し、「利用できるロール」からcan_deleteを選択し、保存します。
- 手順1. で選択したユーザーでSplunk Webにログインし、検索画面を表示します。
- 非表示にしたい検索結果を得られるような検索文を実行します。 表示された結果を非表示にしても問題ないか確認します。
※検索条件にマッチしたイベントが、以後検索結果に表示されないようになります。
(例)sourcetype="syslog" abcdef - 手順4.の検索文にdeleteコマンドを追加し、検索を実行します。(例)sourcetype="syslog" abcdef | delete
[注意事項]
- 上記の例は、 sourcetype=“syslog”の中でabcdefという文字列を持つイベントを検索結果から削除する(非表示にする)例となります。
- deleteコマンドを使用する方法は、該当するイベントに対して削除フラグを立てるものです。しかしながら、削除フラグをもったイベントはいかなる権限を以ってしても検索できません。
- deleteコマンドによって削除されたイベントは、データとして削除されていないためディスク容量を空けるために使用することは推奨されていません。
- deleteコマンドによって削除されたイベントを検索対象に戻すことはできません。検索対象に戻すためには、再度データを取り込む必要があります。
- 削除作業するユーザーに対して、イベントを削除するロール「can_delete」を付与する必要があります。
- deleteコマンドを実行するには「delete_by_keyword」の権限に加えて、deleteコマンドが実行可能なインデックスを指定する権限「deleteIndexesAllowed」が必要になります。
- ロールの割り当てにcan_deleteを選択せずに「delete_by_keyword」の権限を追加しても、deleteコマンド実行時に下記のメッセージが検索画面に表示され、イベントの削除が行われません。
You do not have the capability to delete from index=<インデックス名>
上記のメッセージが検索画面に表示されている場合、上記【手順】1.2.のようにロールの割り当てに「can_delete」を選択することで、「deleteIndexesAllowed」を設定しなくても、deleteコマンドが実行可能となります。
※「deleteIndexesAllowed」の権限を設定する場合、設定ファイル「authorize.conf」を直接編集し、Splunkサービスの再起動が必要となります。
deleteコマンドやcan_deleteのロールについては参考情報をご覧ください。
以上
設定方法
データの削除方法
- 公開日
- 2015-05-06
- 最終更新日
- 2019-03-29
- バージョン
- Splunk Enterprise 6.6.0, Splunk Enterprise 7.0.2
- 概要
-
インデクサーに取り込んだデータを物理削除する場合、インデクサークラスタリングを利用しているかどうかで手順が異なります。
データを物理削除する方法には、「clean eventdata」コマンドを利用して取り込んだデータを削除する方法と「frozenTimePeriodInSecs」を用いてデータの保存期間を短くする方法があります。
- 内容
-
取り込んだデータを、インデックスからデータごと削除する手順について記載します。
インデクサークラスタリングを使用しているかどうかで手順が異なりますので、環境に合わせた方法にて削除を行ってください。
なお、特定のイベントのみデータをディスクから削除する方法はありません。
スタンドアロン構成(非インデクサークラスタリング環境)の場合
方法1:個別のインデックスを削除する手順
【手順】
- Splunkを停止します。
例)
$SPLUNK_HOME/bin/splunk stop※デフォルトインストールの場合の$SPLUNK_HOME
Linux:/opt/splunk
Windows:C:\Program Files\splunk- 以下のコマンドを実行します。
例)
$SPLUNK_HOME/bin/splunk clean eventdata -index <index_name>※インデックス単位でデータを削除することが可能です。例えば、<index_name>としてmainを指定しますと、mainに蓄積されているデータは全て削除されます。
例)
$SPLUNK_HOME/bin/splunk clean eventdata -index main※-index以降を省略すると、全インデックスデータを削除します。
例)
$SPLUNK_HOME/bin/splunk clean eventdata- Splunkを開始します。
例)
$SPLUNK_HOME/bin/splunk start方法2:frozenTimePeriodInSecsの利用
削除対象のインデックスの保存期間を変更し、自然にローテーション(削除)されるのを待つ方法となります。
frozenTimePeriodInSecsの詳細は、下記ドキュメントをご覧ください。
http://docs.splunk.com/Documentation/Splunk/7.0.2/Indexer/Setaretirementandarchivingpolicy
【手順】
- データを削除したいIndexに、ファイルやフォルダ監視などでデータを取り込んでいる場合、フォワーダーもしくはインデクサー上のinputs.confからその設定を削除し、データが新しく取り込まれないようにします。
- $SPLUNK_HOME/etc/system/local配下もしくは$SPLUNK_HOME/etc/apps/<任意のapp>/local配下のindexes.conf(無ければ新規作成)に下記のスタンザを追加します。
(設定例)
[<削除したいindex名>]
frozenTimePeriodInSecs = 100※秒単位で指定します。例えば上記設定を行った場合、バケツの中に存在するイベントの中で一番新しいタイムスタンプが、SplunkのインストールされているOSの時刻より、100秒以上前の場合、そのバケツをfrozen状態に移行します。
- Splunkを再起動し、設定を反映させます。
- Indexのデータが削除されているか確認した後、上記2.で設定したスタンザを削除します。
- 再びSplunkを再起動します。
インデクサークラスタリングを使用している場合
インデクサークラスタリング機能を使用している場合、特定のインデクサー上にある、特定のインデックス単体を削除することは出来ません。
クラスター構成の場合は、以下の方法にて全インデクサー(クラスターピア)上よりインデックス単位でデータを削除することが可能です。
【手順】
- データを削除したいIndexに、ファイルやフォルダ監視などでデータを取り込んでいる場合、フォワーダーもしくはインデクサー上のinputs.confからその設定を削除し、データが新しく取り込まれないようにします。
- クラスタマスター上の$SPLUNK_HOME/etc/master-apps/_cluster/local配下のindexes.conf(無ければ新規作成)に下記のスタンザを追加します。
(設定例)
[<削除したいindex名>]
frozenTimePeriodInSecs = 100※秒単位で指定します。例えば上記設定を行った場合、バケツの中に存在するイベントの中で一番新しいタイムスタンプが、SplunkのインストールされているOSの時刻より、100秒以上前の場合、そのバケツをfrozen状態に移行します。
- CLIにて下記コマンドを使用し、クラスタマスターの設定をクラスタピアに配布します。
$SPLUNK_HOME/bin/splunk apply cluster-bundle※上記コマンドを実行すると、全てのピアを再起動するか確認を求められますのでyesを入力してください。
※変更されたfrozenTimePeriodInSecsの設定値を配布したのみでは、Splunkサービスは再起動されませんが、配布後の設定が有効な状態になります。
上記コマンドの詳細につきましては、下記ドキュメントをご覧ください。
http://docs.splunk.com/Documentation/Splunk/7.0.2/Indexer/Updatepeerconfigurations
- HOTのステージにあるバケツをWARMのステージに遷移させるため、クラスターマスターからクラスタピアをローリングリスタートさせます。
$SPLUNK_HOME/bin/splunk rolling-restart cluster-peers上記コマンドの詳細につきましては、下記ドキュメントをご覧ください。
http://docs.splunk.com/Documentation/Splunk/7.0.2/Indexer/Userollingrestart
- Indexのデータが削除されているか確認した後、上記2.で設定したスタンザを削除します。
- 上記③を再び実行します。
以上
Splunk WebのSSL通信を有効にする方法
- 公開日
- 2019-03-08
- 最終更新日
- 2023-02-15
- バージョン
- Splunk Enterprise 9.0.3
- 概要
-
- Splunk WebのSSL通信を有効にする方法は3通りあります
-
- Splunk Web の「サーバー設定」から有効にする
- CLI から splunk enable web-ssl コマンドを実行する
- 設定ファイルの web.conf を編集する
- 参考情報
-
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Security/AboutsecuringauthenticationtoSplunkWeb
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Security/TurnonbasicencryptionwithSplunkWeb
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Security/Turnonbasicencryptionusingweb.conf
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Security/SecureSplunkWebusingasignedcertificate
- 内容
-
Splunk Web はデフォルトでは暗号化されていませんので、必要に応じて以下のいずれかの方法で有効にしてください。
- Splunk Web からSSL通信を有効にする
- コマンドからSSL通信を有効にする
- 設定ファイルからSSL通信を有効にする
デフォルトでSplunk WebのSSL通信を有効化する場合、Splunkがデフォルトで用意しているサーバー証明書(cert.pem)を利用します。
Splunk Web からSSL通信を有効にする方法
Splunk Web を使用して、GUI上からSSL通信を有効にすることができます。以下の手順で設定してください。
- admin ロールを持つユーザーで Splunk Web にログインする
- 画面右上のメニューから、「設定」 > 「サーバー設定」 をクリックする
- サーバー設定画面にて「全般設定」をクリックする
- 「Splunk Web で SSL (HTTPS) を有効にしますか?」で「はい」を選択する
- 「保存」をクリックする
- 画面右上のメニューから、「設定」 > 「サーバーコントロール」 をクリックする
- 「Splunkの再起動」をクリックする
- 再起動の確認ダイアログで「OK」をクリックして Splunk を再起動する
再起動完了後、https で Splunk Web にアクセスできることを確認してください。
SSL通信を無効に戻す場合は、上記の手順と同様の手順で「全般設定」画面を開き、「Splunk Web で SSL (HTTPS) を有効にしますか?」で「いいえ」を選択して保存し、⑧の再起動までを行ってください。
コマンドからSSL通信を有効にする方法
以下のコマンドで Splunk Web のSSL通信を有効にすることができます。SSL通信有効化コマンドの実行後、設定を反映させるためにサービスの再起動コマンドを実行してください。
<Splunk WebのSSL通信有効化>
$SPLUNK_HOME/bin/splunk enable web-ssl -auth <管理ユーザー>:<パスワード><Splunk サービスの再起動>
$SPLUNK_HOME/bin/splunk restart再起動完了後、https で Splunk Web にアクセスできることを確認してください。
SSL通信を無効に戻す場合は以下のコマンドを実行し、Splunk サービスを再起動してください。
<Splunk WebのSSL通信無効化>
$SPLUNK_HOME/bin/splunk disable web-ssl -auth <管理ユーザー>:<パスワード>※$SPLUNK_HOME は Splunk のインストールディレクトリで、以下がデフォルトです。
Linux:/opt/splunk
Windows:C:\Program Files\Splunk設定ファイルからSSL通信を有効にする方法
設定ファイルで Splunk Web のSSL通信を有効にする場合は、web.conf に設定する必要があります。以下の設定ファイルに設定を追加してください。
<設定ファイル>
$SPLUNK_HOME/etc/system/local/web.conf<設定例>
[settings]
enableSplunkWebSSL = true設定後、Splunk サービスを再起動することで、SSL通信が有効になります。再起動完了後、https で Splunk Web にアクセスできることを確認してください。
SSL通信を無効に戻す場合は、設定前の状態に戻すか、enableSplunkWebSSL に false を設定し、Splunk サービスを再起動してください。
※$SPLUNK_HOME は Splunk のインストールディレクトリで、以下がデフォルトです。
Linux:/opt/splunk
Windows:C:\Program Files\Splunk以上
Splunk WebのSSL通信に任意の自己署名証明書を使用する方法
④
- 公開日
- 2019-03-08
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.3
- 概要
-
Splunk WebへのSSL通信に任意の自己署名証明書を使用するには、Splunkに対応した証明書の準備と、設定ファイルの編集が必要です。
証明書の準備
- PEM形式のルートCA証明書、サーバー証明書、秘密鍵ファイルを用意します
-
- ルートCA証明書とサーバー証明書を結合して一つのファイルにしておきます
- 秘密鍵ファイルはパスワード保護されていないものを用意しておきます
Splunk への設定
- 結合したした証明書(ルートCA+サーバー証明書)と秘密鍵ファイルのパスを web.conf に設定します
- 参考情報
- 内容
-
証明書の準備
Splunk Web でのSSL通信に自己署名証明書を使用する場合は、PEM形式のサーバー証明書とサーバー証明書の秘密鍵のファイルが必要です。
サーバー証明書はルートCA証明書と結合して1つのファイルにしておく必要があります。Linux の cat コマンドや、Windows の type コマンドを使用してファイルを結合してください。
また、Splunk Web に設定するサーバー証明書の秘密鍵はパスワード保護に対応していないため、パスワード保護されていない秘密鍵ファイルをご用意ください。
以下のコマンド実行例は、準備した証明書および秘密鍵ファイルを格納するために作業用ディレクトリを作成し、このディレクトリに移動した状態での実行例となります。
<作業用ディレクトリ>
$SPLUNK_HOME/etc/auth/mycert※$SPLUNK_HOME はインストールディレクトリを示しており、デフォルトでは以下のパスになります。
Linux : /opt/splunk
Windows : C:\Program Files\Splunk<証明書ファイル>
ルートCA証明書ファイル-rootCACert.pem
サーバー証明書ファイル-serverCert.pem<Linuxでのコマンド実行例>
cat ./rootCACert.pem >> ./serverCert.pem<Windowsでのコマンド実行例>
type rootCACert.pem >> serverCert.pemSplunk Web の設定
ブラウザから Splunk Web へのアクセスに任意の自己署名証明書を使用する場合は、サーバー証明書とサーバー証明書の秘密鍵のパスを web.conf に設定する必要があります。
サーバー証明書およびサーバー証明書の秘密鍵のファイルパスにつきましては、実際のファイルに合わせて変更してください。
ファイルパスには、絶対パスと $SPLUNK_HOME で始まる相対パスが使用できます。
<設定ファイル>
$SPLUNK_HOME/etc/system/local/web.conf<設定例>
[settings]
enableSplunkWebSSL = true
privKeyPath = <サーバー証明書の秘密鍵のファイルパス>
serverCert = <サーバー証明書のファイルパス>設定を有効にするためには Splunk サービスの再起動が必要になります。設定後は以下のコマンドを実行し、再起動を実施してください。
<再起動コマンド>
$SPLUNK_HOME/bin/splunk restart動作の確認方法
設定完了後はブラウザでSplunk Webにアクセスし、画面が表示されることとサーバー証明書が用意した自己署名証明書であることをご確認ください。
上記の設定例では以下の URL で Splunk Web にアクセスできます。
https://サーバーのFQDNまたはIPアドレス:8000/以上
サーチヘッドの内部ログとサマリーインデックスをインデクサーへ転送する方法
- 公開日
- 2019.01.11
- 最終更新日
- 2019.01.11
- バージョン
- Splunk Enterprise 6.2.6, 7.1.4
- 概要
-
- サーチヘッドのインデックスデータをインデクサーに転送することで内部ログやサマリーインデックスをインデクサーで一元管理することが可能です。
- 設定方法にはSplunkWebからの設定と設定ファイル編集の2種類があります。
- この設定ではいくつかの注意事項があります。
-
- 環境によって内部インデックスサイズを調整する必要がある可能性があります。
- この設定ではサーチヘッドで取り込まれている全てのデータが転送されます。
- インデクサーへ転送されるデータは設定後に生成されたもののみとなります。
- 参考情報
-
- サーチヘッドからインデクサーへデータ転送する方法
http://docs.splunk.com/Documentation/Splunk/7.1.4/DistSearch/Forwardsearchheaddata
- サーチヘッドからインデクサーへデータ転送する方法
- 内容
-
設定の目的
サーチヘッドのインデックスデータをインデクサーに転送することで、サーチヘッドとインデクサーの内部ログやサマリーインデックスを一元管理することが可能となります。
設定方法
設定方法にはWebGUIからの設定と設定ファイルの編集の2種類あります。
○WebGUIからの設定
【手順】
- SplunkWeb画面右上より「設定>転送と受信」を選択します。
- 転送と受信メニュー内の「転送のデフォルト」を選択します。
- 「転送されたイベントをローカルにコピーして保管しますか?」を「いいえ」にセットして「保存」を選択します。
- 転送と受信メニュー内の「転送の設定」の右側ボタン「新規追加」を選択します。
- データの転送先を入力する画面が開かれるので、ホスト欄に送信先を「ホスト:ポート」または「IP:ポート」の形式で指定し「保存」を選択します。
○設定ファイルの編集 サーチヘッドのoutputs.confを下記のように変更します。
【内部ログ転送の設定例】
※インデクサー3台(Indexer A,B,C)に対してデータを分散転送する場合の設定例となります。
$SPLUNK_HOME/etc/system/local/outputs.conf[indexAndForward]
index = false
[tcpout]
defaultGroup = test
forwardedindex.filter.disable = true
indexAndForward = false
[tcpout:test]
server=<IndexerAのIP>:<受信ポート>,<Indexer BのIP>:<受信ポート>,<Indexer CのIP>:<受信ポート>
autoLB=true※デフォルトインストールの場合
$SPLUNK_HOME(Linux) : /opt/splunk
$SPLUNK_HOME(Windows) : C:\Program Files\splunk※設定を反映させるには、Splunkサービスの再起動が必要となります。
例
$SPLUNK_HOME/bin/splunk restart注意事項
- サーチヘッドの内部ログがインデクサーに追加で保存されるため、転送量によってはインデクサーの内部インデックス(_internalなど)の容量を大きくする必要があります。
- この設定を行うとサーチヘッドに取り込むデータが全てインデクサーへ転送されます。もしも内部ログ等以外にサーチヘッドへ取り込んでいるデータがある場合、そのデータも転送対象となります。
- 転送対象のデータは設定後に追加されたもののみとなります。設定前に取り込まれたデータについてはインデクサーへ転送されません。
以上
Windowsイベントログをフィルタ転送する方法
- 公開日
- 2016-05-27
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- Windowsイベントログをフィルタ転送する方法
- 参考情報
-
- Windowsでファイルシステムの変更をモニターする
https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/MonitorfilesystemchangesonWindows
- Windowsでファイルシステムの変更をモニターする
- 内容
-
Windowsイベントログをフォワーダーを使用してインデクサーへ転送する際、Windowsイベントログの内容に基づいてblacklistやwhitelistによるフィルタリングを実装することが可能です。
フィルタリングには、WindowsイベントログのイベントIDやmessageなどをキーとして利用できます。
本FAQでは、イベントIDで対象ログを指定する方法を中心にご案内します。
※設定についての留意事項
- blacklistやwhitelistで転送/除外したいWindowsイベントログに対して、イベントIDやmessage等のキーを正規表現で指定してください。
- イベントID以外をフィルタリング条件として使用したい場合は、下記のリンクをご覧ください。
https://docs.splunk.com/Documentation/Splunk/9.0.3/Forwarding/Routeandfilterdatad#Filter_event_data_and_send_to_queues - インデクサー側でフィルタリングを実装する必要がある場合、後述する「※注意事項1」の内容を参考にしてください。blacklist、whitelistを使用したフィルタリングはご利用できません。
特定のイベントIDを除外して転送する方法
特定のイベントIDを持つWindowsイベントログを除外したい場合はフォワーダーのinputs.confに対してblacklistの設定を行ってください。
下記に具体的な設定例をご案内します。
例1)イベントID"4672"のWindowsイベントログを除外したい
[WinEventLog://System]
blacklist = EventCode="4672"例2)イベントID"4672","4660","5065"のWindowsイベントログを除外したい
※下記のいずれかの表現が可能です。
[WinEventLog://System]
blacklist = EventCode="4672|4660|5065"もしくは
[WinEventLog://System]
blacklist1 = EventCode="4672"
blacklist2 = EventCode="4660"
blacklist3 = EventCode="5065"※blacklist1~9の範囲で指定してください。
例3)イベントID"4672"かつアカウント名がWINから始まるユーザーのイベントを除外したい
[WinEventLog://System]
blacklist = EventCode="4672" Message="アカウント名:\t\tWIN.+"特定のイベントIDを指定して転送する方法
指定した複数のイベントIDを持つWindowsイベントログを転送したい場合はフォワーダーのinputs.confに対してwhitelistの設定を行ってください。
例4)イベントID"4672"のWindowsイベントログを指定して転送したい
[WinEventLog://System]
whitelist = EventCode="4672"例5)イベントID"4672","4660","5065"のWindowsイベントログを指定して転送したい
※下記のいずれかの表現が可能です。
[WinEventLog://System]
whitelist = EventCode="4672|4660|5065"もしくは
[WinEventLog://System]
whitelist1 = EventCode="4672"
whitelist2 = EventCode="4660"
whitelist3 = EventCode="5065"※whitelist1~9の範囲で指定してください。
例6)イベントID"4672"かつアカウント名がWINから始まるユーザーのイベントを転送したい
[WinEventLog://System]
whitelist = EventCode="4672" Message="アカウント名:\t\tWIN.+"※注意事項1
インデクサー側でフィルタリングを実装する必要がある場合はインデクサーのprops.confとtransforms.confを編集してください。
インデクサーでフィルタリングを実装する方法について、詳細は下記のリンクをご覧ください。
https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/Whitelistorblacklistspecificincomingdata
※注意事項2
blacklistとwhitelistで同じファイルが指定された場合、blacklistの設定が優先されます。
また、数字付のblacklist、whitelistは1~9のみサポートされます。それ以上の数字は割り当てないようお願い致します。
blacklistとwhitelistのどちらにも指定されなかったファイルは全て読み込み対象となります。
詳細は下記のリンクをご覧ください。
https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/Whitelistorblacklistspecificincomingdata
以上
1イベントの最大サイズとその変更方法
- 公開日
- 2015-08-03
- 最終更新日
- 2024-01-18
- バージョン
- Splunk Enterprise 9.1.0
- 概要
- 1イベントの最大サイズ(1行の最大サイズ、最大行数)のデフォルト値と変更方法について
- 内容
-
1イベントの最大サイズ(1行の最大サイズ、最大行数)のデフォルト値と変更方法を以下に記載します
1行の最大サイズについて
1行の最大サイズは、デフォルトでは10000バイトです。
1行が10000バイトを超えるデータは、10001バイト以降が切り捨てられます。
変更する場合はprops.confファイルのTRUNCATEの値を変更します。
設定例
<対象ファイル>
ヘビーフォワーダー、(ヘビーフォワーダーを使用していない場合は)インデクサー
$SPLUNK_HOME/etc/apps/<App名>/local/props.confまたは
$SPLUNK_HOME/etc/system/local/props.conf<設定内容>
[test]
TRUNCATE=50000※1行の最大サイズを、バイト数で指定します。
※TRUNCATE=0を設定することで切り捨てを行わない動作となります。
以下に注意の上、環境に合わせて必要なサイズを指定してください。
注意
1行当たりの文字数が膨大なデータを取り込んだ際にパフォーマンスに影響を与えてしまう可能性があります。※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
<Linux>
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder<Windows>
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder設定変更後は、Splunkサービスを再起動してください。
$SPLUNK_HOME/bin/splunk restart1イベントの最大行数について
1イベントの最大行数はデフォルトでは257行です。
それ以降はイベントが分割されて取り込まれます。変更する場合はprops.confファイルのMAX_EVENTSの値を変更します。
<設定例>
イベントをソースタイプ「test」として取り込み、その最大行数を変更する場合
<対象ファイル>
ヘビーフォワーダー、(ヘビーフォワーダーを使用していない場合は)インデクサー
$SPLUNK_HOME/etc/apps/<App名>/local/props.confまたは
$SPLUNK_HOME/etc/system/local/props.conf<設定内容>
[test]
MAX_EVENTS=256※行数を指定します。上限値はありません。
※設定変更後は、Splunkサービスを再起動してください。
$SPLUNK_HOME/bin/splunk restart注意事項
TRUNCATE、MAX_EVENTSのいずれも、インデックス処理や検索パフォーマンスへの影響を避けるための制限となります。
変更する際には、実質的に無制限となるような値ではなく、必要なサイズを指定してください。
以上
JSON形式のログ検索時フィールドが2重に表示されてしまう場合の回避方法
- 公開日
- 2018-06-14
- 最終更新日
- 2023-05-19
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- JSON形式のログ検索時フィールドが2重に表示されてしまう場合の回避方法
- 参考情報
- 内容
-
JSON形式のログを取り込むためのソースタイプにてカスタムでフィールドを定義した場合、取り込んだログファイルを検索した際にフィールドが2重に表示される場合があります。
これはインデックス処理時(データ取り込み時)にフィールドが抽出され、なおかつ、データ検索時にもフィールドが抽出されたために同じフィールドが2重に表示される事が原因として考えられます。
対処方法として、サーチを実行するSplunkサーバーのprops.confファイルに、以下のパラメーターを追記する事で事象の回避が可能です。
設定ファイル
サーチを実行するSplunkサーバーのprops.conf
(設定ファイル例)
$SPLUNK_HOME/etc/system/local/props.conf
$SPLUNK_HOME/etc/apps/<App名>/local/props.conf※注:デフォルトインストールの場合の$SPLUNK_HOME
Linux:/opt/splunk
Windows:C:\Program Files\splunk設定内容
[<フィールドが重複しているデータのソースタイプ名>]
KV_MODE = none<設定例>
[SourcetypeA]
KV_MODE = none設定ファイル編集後、下記のURLへアクセスし「refresh」ボタンをクリックすることで再起動せずに設定内容を反映させることができます。
http://<SplunkサーバーのIPアドレス>:8000/debug/refresh以上
クラスター環境でSplunkサービスを全停止全起動させる手順
- 公開日
- 2015-05-28
- 最終更新日
- 2023-11-30
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- クラスター環境でSplunkサービスを全停止/全起動させる順序と実行コマンド
- 参考情報
-
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Indexer/Upgradeacluster
- https://docs.splunk.com/Documentation/Splunk/9.0.3/DistSearch/UpgradeaSHC
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Indexer/Usemaintenancemode
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Indexer/Takeapeeroffline
- 内容
-
クラスター環境でSplunkサービスを停止/起動させる順序
バージョンアップ等ではなく、定期停電やサーバーのメンテナンスを目的としてSplunkサーバーを停止/起動させる場合には、以下の順序にてSplunkサービスを停止/起動させてください。
[停止]
①フォワーダー停止
②サーチヘッド停止
③デプロイメントサーバー停止
④デプロイヤー停止
⑤インデクサー停止
⑥クラスターマスター停止
⑦ライセンスマスター停止[起動]
①ライセンスマスター起動
②クラスターマスター起動
③インデクサー起動
④サーチヘッド起動
⑤フォワーダー起動
⑥デプロイメントサーバー起動
⑦デプロイヤー起動具体的に、Splunkサービスの全停止と全起動をさせる場合には、以下の手順を実行ください。尚、以下手順の$SPLUNK_HOMEはSplunkのインストールディレクトリに読み替えて実行ください。
※デフォルトインストールの場合
<Linux>
$SPLUNK_HOME : /opt/splunk<Windows>
$SPLUNK_HOME : C:\Program Files\splunk▼全停止
- フォワーダーのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop- サーチヘッドのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop- デプロイメントサーバーのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop- デプロイヤーのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop- メンテナンスモードへの切り替え(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk enable maintenance-mode --answer-yes -auth admin:<password>メンテナンスモードに切り替えることで、インデクサーを停止させた際にダウンと判断させず不要なレプリケーション処理を防ぐことができます。メンテナンスモードの詳細につきましては、下記のドキュメントをご参照ください。
http://docs.splunk.com/Documentation/Splunk/6.6.2/Indexer/Usemaintenancemode
- メンテナンスモードに切り替えることで、インデクサーを停止させた際にダウンと判断させず不要なレプリケーション処理を防ぐことができます。メンテナンスモードの詳細につきましては、下記のドキュメントをご参照ください。
https://docs.splunk.com/Documentation/Splunk/9.1.2/Indexer/Usemaintenancemode
- メンテナンスモードに切り替わっていることを確認(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk show maintenance-mode -auth admin:<password>※メンテナンスモードに切り替わっている場合、以下のように出力されます。
Maintenance mode is : 1- タイムアウト値の調整(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk edit cluster-config
-restart_timeout <秒数> -auth admin:<password>※インデクサー全台のSplunkサービス停止にかかる時間を指定してください。
※短くなければ、大よその時間で問題ありません。
※短く設定した場合、不要なバケツのコピーが発生する可能性や、起動時に時間を要する可能性があります。
※このタイムアウト値は offlineコマンドで停止させる際にのみ有効になるため、元に戻す必要は特にありません。
- インデクサーのSplunkサービス停止
$SPLUNK_HOME/bin/splunk offline- クラスターマスターのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop- ライセンスマスターのSplunkサービス停止
$SPLUNK_HOME/bin/splunk stop▼全起動
- ライセンスマスターのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- クラスターマスターのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- メンテナンスモードへの切り替え(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk enable maintenance-mode --answer-yes -auth admin:<password>※Splunk6.5.x以前のバージョンでは、再起動後にメンテナンスモードが無効化されるため、再度メンテナンスモードに切り替える必要があります。
- メンテナンスモードに切り替わっていることを確認(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk show maintenance-mode -auth admin:<password>※メンテナンスモードに切り替わっている場合、以下のように出力されます。
Maintenance mode is : 1- インデクサーのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- メンテナンスモードの無効化(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk disable maintenance-mode -auth admin:<password>- メンテナンスモードが無効化されていることを確認(クラスターマスターで実施)
$SPLUNK_HOME/bin/splunk show maintenance-mode -auth admin:<password>※メンテナンスモードが無効化された場合、以下のように出力されます。
Maintenance mode is : 0- サーチヘッドのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- フォワーダーのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- デプロイメントサーバーのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start- デプロイヤーのSplunkサービス起動
$SPLUNK_HOME/bin/splunk start以上
デフォルトのサーバー証明書を更新する方法
- 公開日
- 2018-03-16
- 最終更新日
- 2023-12-11
- バージョン
- Splunk Enterprise 9.0.4
Splunk Universal Forwarder 9.0.4
- 概要
- デフォルトのサーバー証明書を更新する手順
- 内容
-
Splunkがデフォルトで用意しているサーバー証明書(server.pem)は、Splunkインストール後、最初にSplunkサービスを起動したタイミングで作成されます。
このサーバー証明書の失効日は最初に起動した日付から起算して3年後となります。失効日が近づいた場合、下記の手順でサーバー証明書を更新することが可能です。
server.pemの更新手順
- $SPLUNK_HOME/etc/auth フォルダ配下にある現在のserver.pem を一旦、$SPLUNK_HOME外のディレクトリより退避します。
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下の通りです。
Linux :
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder
Windows :
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder- Splunkサービスを再起動します。
コマンド例:
$SPLUNK_HOME/bin/splunk restart- 再起動後、$SPLUNK_HOME/etc/authに新しいserver.pemが作成されていることを確認します。
※新しく作成したserver.pemの失効日は、$SPLUNK_HOME/etc/auth で下記のコマンドを実行することで確認ができます。
openssl x509 -enddate -noout -in server.pem以上
検索時に利用するソースタイプ名を変更する方法
- 公開日
- 2019-08-29
- 最終更新日
- 2023-11-27
- バージョン
- Splunk Enterprise 9.1.1
- 概要
- Splunkにはソースタイプ名を変更して検索できるようにする「rename」という機能が用意されています。
ログの取り込み時とは異なるソースタイプ名で対象のログを検索したい場合や、複数のソースタイプを同一のものとして検索したい場合等に、この機能を利用します。
この機能を利用する場合、props.confでパラメーター 「rename」を設定します。
- 内容
-
「rename」の機能について
Splunkではログの取り込み時に利用したソースタイプ名を指定することで、対象のログの検索を行うことが可能です。
「rename」という機能により、ログの検索時に指定するソースタイプ名を変更することが可能です。
この機能を利用することで、以下のような操作が行えます。
- 取り込み時に指定したソースタイプ名とは別名でログを検索する
- 検索時に利用する複数のソースタイプを同一のものとして扱う
設定例
<前提>
取り込み時に指定したソースタイプ名:sourcetypeA
検索時に利用したいソースタイプ名:sourcetypeB<設定対象ファイル>
サーチヘッドの
$SPLUNK_HOME/etc/system/local/props.conf もしくは
$SPLUNK_HOME/etc/apps/<任意のApp>/local/props.conf※$SPLUNK_HOMEはインストールディレクトリです。また、デフォルトでは以下の通りです。
<Linux>
Splunk Enterprise : /opt/splunk<Windows>
Splunk Enterprise : C:\Program Files\Splunk追加する設定
[sourcetypeA]
…既存の設定…
rename = sourcetypeB上記の設定追加後、検索時の対象のソースタイプの扱いは以下となります。
- sourcetypeBを指定して検索すると、sourcetypeAで取り込みを行ったログが検索結果に表示されます。
- sourcetypeAを指定して検索すると、sourcetypeAで取り込みを行ったログは検索結果に表示されません。
尚、検索時にフィールド「_sourcetype」を利用すると、変更前のソースタイプ名で対象のログを検索することが可能です。
<例>
_sourcetype = sourcetypeA注意事項
「rename」の機能は検索時のみ利用できます。ログ取り込み時に指定するソースタイプ名を変更することはできません。
以上
SplunkWebのデフォルトのサーバー証明書(cert.pem)を更新する方法
- 公開日
- 2019-08-29
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.1.2
- 概要
-
SplunkWebをSSL化(HTTPS)した場合にデフォルトで使用するサーバー証明書(cert.pem)の有効期限は新規インストール後に最初にサービスを起動した日から起算して3年後となります。
証明書を更新する場合は以下のいずれかの方法で更新します。
- 方法1:古い証明書を別の場所に移動し、Splunkのサービスを再起動する
- 方法2:createsslコマンドを実行して証明書を更新し、Splunkサービスを再起動する
- 内容
-
更新方法
SplunkWebでSSL(HTTPS)を有効にした場合にデフォルトで使用するサーバー証明書(cert.pem)の失効日が近づいた場合、下記の手順でサーバー証明書を更新することが可能です。2通りの方法がありますので、いずれかの方法で更新してください。
尚、下記手順の$SPLUNK_HOMEはSplunkのインストールディレクトリに読み替えて実行ください。
※デフォルトインストールの場合
<Linux>
$SPLUNK_HOME : /opt/splunk<Windows>
$SPLUNK_HOME : C:\Program Files\splunk方法1
手順
- $SPLUNK_HOME/etc/auth/splunkweb フォルダ配下にある現在のcert.pem 、privkey.pemを$SPLUNK_HOME外のディレクトリへ移動します。
- Splunkサービスを再起動します。
コマンド:$SPLUNK_HOME/bin/splunk restart - 再起動後、$SPLUNK_HOME/etc/authに新しいcert.pem が作成されていることを確認します。
方法2
方法1で作成された証明書のキーサイズは2048bitです。キーサイズを変更する場合は本手順をご利用ください
手順
- $SPLUNK_HOME/etc/auth/splunkweb フォルダ配下にある現在のcert.pem、 privkey.pemを$SPLUNK_HOME外のディレクトリへ移動します。
- 下記コマンドを実行して証明書を更新します。
コマンド:
※3072はサーバ証明書のキーサイズです。省略した場合は方法1と同じキーサイズになります。cd $SPLUNK_HOME/etc/auth/splunkweb
$SPLUNK_HOME/bin/splunk createssl web-cert 3072 - Splunkサービスを再起動します。
コマンド:
$SPLUNK_HOME/bin/splunk restart - 再起動後、$SPLUNK_HOME/etc/auth/splunkwebに新しいcert.pem、privkey.pemが作成されていることを確認します。
以上
SplunkWebのデフォルトのサーバー証明書(cert.pem)の有効期限と確認方法
- 公開日
- 2019-08-29
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.1.2
- 概要
-
SplunkWebをSSL化(HTTPS)した場合にデフォルトで使用するサーバー証明書(cert.pem)の有効期限は新規インストール後に最初にサービスを起動した日から起算して3年後となります。
証明書を更新する方法について説明します。
- 方法1:古い証明書を別の場所に移動し、Splunkのサービスを再起動する
- 方法2:createsslコマンドを実行して証明書を更新し、Splunkサービスを再起動する
- 内容
-
更新方法
SplunkWebでSSL(HTTPS)を有効にした場合にデフォルトで使用するサーバー証明書(cert.pem)の失効日が近づいた場合、下記の手順でサーバー証明書を更新することが可能です。
2通りの方法がありますので、いずれかの方法で更新してください。
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下の通りです。
<Linux>
Splunk Enterprise : /opt/splunk<Windows>
Splunk Enterprise : C:\Program Files\Splunk方法1
【手順】
$SPLUNK_HOME/etc/auth/splunkweb フォルダ配下にある現在のcert.pem、privkey.pemを
$SPLUNK_HOME外のディレクトリへ移動します。
Splunkサービスを再起動します。
コマンド:
$SPLUNK_HOME/bin/splunk restart再起動後、$SPLUNK_HOME/etc/authに新しいcert.pem が作成されていることを確認します。
方法2
方法1で作成された証明書のキーサイズは2048bitです。
キーサイズを変更する場合は本手順をご利用ください。
【手順】
$SPLUNK_HOME/etc/auth/splunkweb フォルダ配下にある現在のcert.pem、privkey.pemを
$SPLUNK_HOME外のディレクトリへ移動します。
下記コマンドを実行して証明書を更新します。
コマンド:
cd $SPLUNK_HOME/etc/auth/splunkweb
$SPLUNK_HOME/bin/splunk createssl web-cert 3072※3072はサーバ証明書のキーサイズです。
省略した場合は方法1と同じキーサイズになります。
Splunkサービスを再起動します。
コマンド:
$SPLUNK_HOME/bin/splunk restart再起動後、$SPLUNK_HOME/etc/auth/splunkwebに新しいcert.pem、privkey.pemが作成されていることを確認します。
以上
追加データのみ取り込む方法
- 公開日
- 2016-09-21
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- データ量増大を防ぐため追加データのみを取り込みたい場合、inputs.confの[Monitor]スタンザ内にfollowTail=1を追加することで、設定実施以降に取り込まれたデータのみを取り込むことが可能です。
- 内容
-
データ取り込みについて
Splunkではデータ取り込みの設定を行うと、取り込み対象のフォルダ/ファイル内のデータを全て取り込みます。取り込み対象のデータが膨大である場合、データの取り込み処理に時間が掛かることやライセンスオーバーの恐れがあります。
以下の設定をすることにより、取り込み設定を実施した以降に取り込まれたデータからSplunkに取り込ませることが可能となります。
設定方法
- <SPLUNK_HOME>/etc/system/local/inputs.confをテキストエディタで開きます。
- 以下の設定を追記します
[monitor://<取り込みたいファイルのパス>]
followTail = 1例:上記設定を用いて/var/logフォルダ配下のデータの取り込みを実施する場合
[monitor:///var/log]
followTail = 1- splunkを再起動します
以上
ユーザーを削除する際の注意点
- 公開日
- 2016-11-07
- 最終更新日
- 2024-01-29
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- ユーザーを削除する際は、そのユーザーが作成したサーチやレポート等の表示先/所有者を変更する必要があります。
- 内容
-
ユーザーの異動等により対象ユーザーのアカウントを削除する際の注意点について
表示先が「プライベート」に設定されているサーチやレポート等は、対象ユーザーのアカウント削除伴い、そのサーチやレポート等は「所有者なし」となり、「Orphaned knowledge objects」と呼ばれ、想定しない動作を起こす可能性があります。
回避方法としてはサーチ、レポート等の表示先や所有者を変更する方法があります。
※所有者も併せて変更したい場合は事前にサーチ、レポート等の表示先を変更後、下記<参考>に従って、サーチ、レポート等の「オーナー」を変更してください。
表示先を変更する方法
表示先が「このAppのみ」もしくは「すべてのApp」に設定されているサーチやレポート等は、該当のAppを使用するユーザーが引き続きそのサーチやレポート等を使用できるため、一部のユーザーアカウントの削除を行っても特に問題ありません。
表示先が「プライベート」に設定されているサーチやレポート等を、引き続き他のユーザーにて使用する場合は、下記の手順に従ってサーチやレポート等の表示先を変更します。
- adminロールを持つユーザーでSplunk Webにログインし、「設定」>「すべての環境設定」を選択します。
- 左上の「App」を「すべて」に、「オーナー」を削除するユーザーにそれぞれ変更し、設定変更したいサーチ、レポート等を表示します。
- 2.で表示したサーチやレポート等に対して、「共有中」列の「権限」をクリックします。
- 「<保存済みサーチやビュー>の表示先」 を 「このAppのみ」もしくは 「すべてのApp」 へ変更します。
また、読み込み/書き込み権限を任意のロールに対して割り当てたのち、「保存」をクリックします。
※他ユーザーへのサーチやレポート等の共有範囲として、下記のパターンがあります。
- プライベート:サーチやレポート等を作成した所有者のみに共有されます。
- このAppのみ:該当するApp(例:search)を使用しているユーザー内で共有されます。
- すべてのApp:利用Appに関わらず、全てのユーザー内で共有されます。
※「<保存済みサーチやビュー>の表示先」 を変更できるのはadminロールを持つユーザーとなります。
表示先を変更する方法
削除を行うユーザーが作成したサーチ、レポート等の所有者を変更するには、下記の手順を実施してください。
- adminロールを持つユーザーでSplunk Webにログインし、「設定」>「すべての環境設定」を選択します。
- 右上の「ナレッジオブジェクトの再割り当て」をクリックします。
- 「所有者でフィルター」を展開し、削除するユーザーを選択します。
- 該当のナレッジオブジェクトの「再割り当て」を展開し、新しい所有者を選択して「保存」します。
以上
検索可能な時間範囲をユーザー毎に制限する方法
- 公開日
- 2016-11-18
- 最終更新日
- 2023-09-29
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- 検索可能な時間範囲をユーザー毎に制限する方法
- 内容
-
データの検索可能な時間範囲について
デフォルトでは、ユーザーはSplunkに取り込まれている全時間のデータを検索することが出来ます。
ユーザー毎に検索可能なデータの時間範囲を制限したい場合、以下の方法にて設定することが出来ます。
検索可能時間範囲設定方法
- SplunkWebにアクセスし、設定 > アクセス制御 > ロール > 新規を選択します。
- ロール名を記載し、"サーチ時間範囲の制限"に、検索可能にしたい時間範囲を秒数で記載します。
※例えば、過去7日間のデータを検索可能に設定する場合、604800と記載します。 - 保存ボタンを選択します。
- 設定 > アクセス制御 > ユーザーから、検索対象時間範囲を制限したいユーザーを選択します。
- "ロールに割り当て"から、作成したロールを割り当てて保存します。
以上
グラフの種類を増やす方法
- 公開日
- 2016-11-25
- 最終更新日
- 2024-01-16
- バージョン
- Splunk Enterprise 9.1.1
- 概要
- Splunkは様々な視覚化方法に対応しており、必要に応じて使用できるグラフの種類を増やすことができます。
- 参考情報
-
- Custom visualizations overview(カスタム可視化)
- 内容
-
Splunkで利用できるグラフについて
Splunkは以下のグラフがデフォルトで利用できます。
- 折れ線グラフ
- 面グラフ
- 縦棒グラフ
- 横棒グラフ
- 円グラフ
- 散布図
- バブル・チャート
- 単一値
- 放射状ゲージ
- フィラーゲージ
- マーカーゲージ
- クラスタマップ
- コロプレスマップ
グラフの種類を増やす方法
デフォルトのグラフ以外を利用したい場合、以下の手順にてグラフの種類を拡張させることが出来ます。
グラフの種類の拡張手順
- SplunkWebにアクセスします。
- ホーム画面左上の歯車アイコン「Appの管理」を選択します。
- 「他のAppを参照」を選択します。
- APP CONTENTの「視覚エフェクト」にチェックを入れます。
※Splunk社サポートの視覚エフェクトを選択する場合はSUPPORT TYPEの「Splunk Supported」にチェックします。 - 追加したい視覚エフェクトの「インストール」を選択し、インストールをします。
※Splunk社サポートの視覚エフェクト名は「<グラフ名>- Custom Visualization」です。
以上
サーチ画面の時間範囲選択に任意の検索期間を追加する方法
- 公開日
- 2017-01-23
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.1.0
- 概要
- times.confに定義を追加することで、任意のサーチ対象期間をタイムレンジ・ピッカーで選択できるようになります。
- 参考情報
- 内容
-
タイムレンジ・ピッカーについて
サーチ対象期間を指定することができ、任意のサーチ対象期間を追加することも可能です。
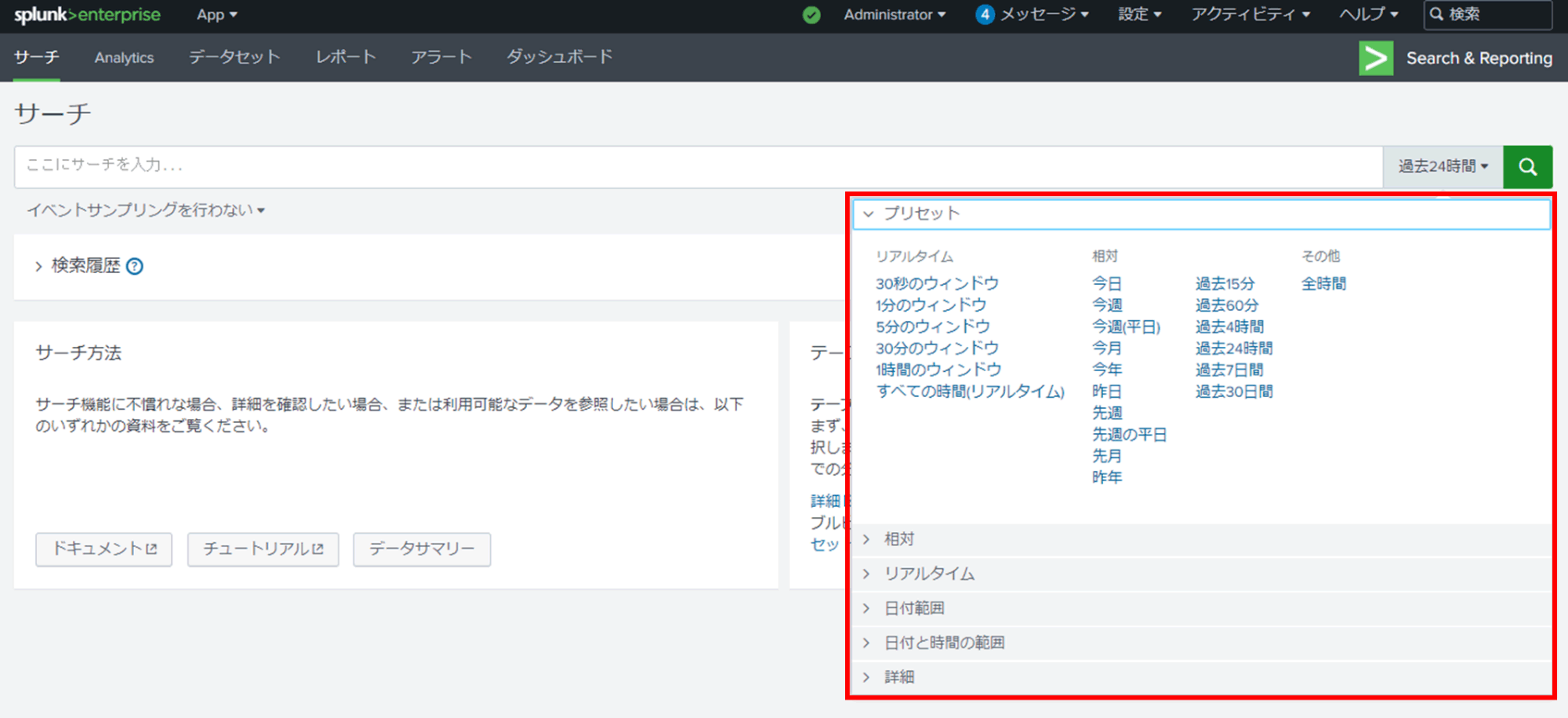
タイムレンジ・ピッカーに任意のサーチ対象期間を追加する手順
- times.confを、テキストエディタ等で開きます。
※ファイルが無い場合は、ファイルを新規作成します。
追加したサーチ対象期間を全体で共有する場合、以下のディレクトリにあるtimes.confを編集します。
$SPLUNK_HOME/etc/system/local/times.conf※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでインストールした場合、下記のパスになります。
Linux : /opt/splunk
Windows : C:\Program Files\Splunk- 以下のフォーマットに沿って任意のサーチ対象期間を追記します。
[<サーチ対象期間名称>]
label = <タイムレンジ・ピッカーに表示する文字列>
earliest_time = <サーチ対象期間の開始日>
latest_time = <サーチ対象期間の終了日>例えば、2023年度秋期というサーチ対象期間を追加したい場合、以下のように記載します。
[Fall_2023]
label = Fall Semester 2023
earliest_time = 1693494000
latest_time = 1701356399※「1693494000」、「1701356399」はUNIXタイムスタンプ表記で、それぞれ2023/09/01 0:00:00、2023/11/30 23:59:59を表します。
また、「本日より2日前(おととい)」のように、現時点を基準にサーチ対象期間の開始日や終了日を相対的に指定できます。
[Day_before_Yesterday]
label = Day before Yesterday
earliest_time = -2d@d
latest_time = now- times.confを保存します。
- Splunkを再起動します。
$SPLUNK_HOME/bin/splunk restart
- サーチ画面のタイムレンジ・ピッカーを表示すると、追加した任意のサーチ対象期間を選択できます。
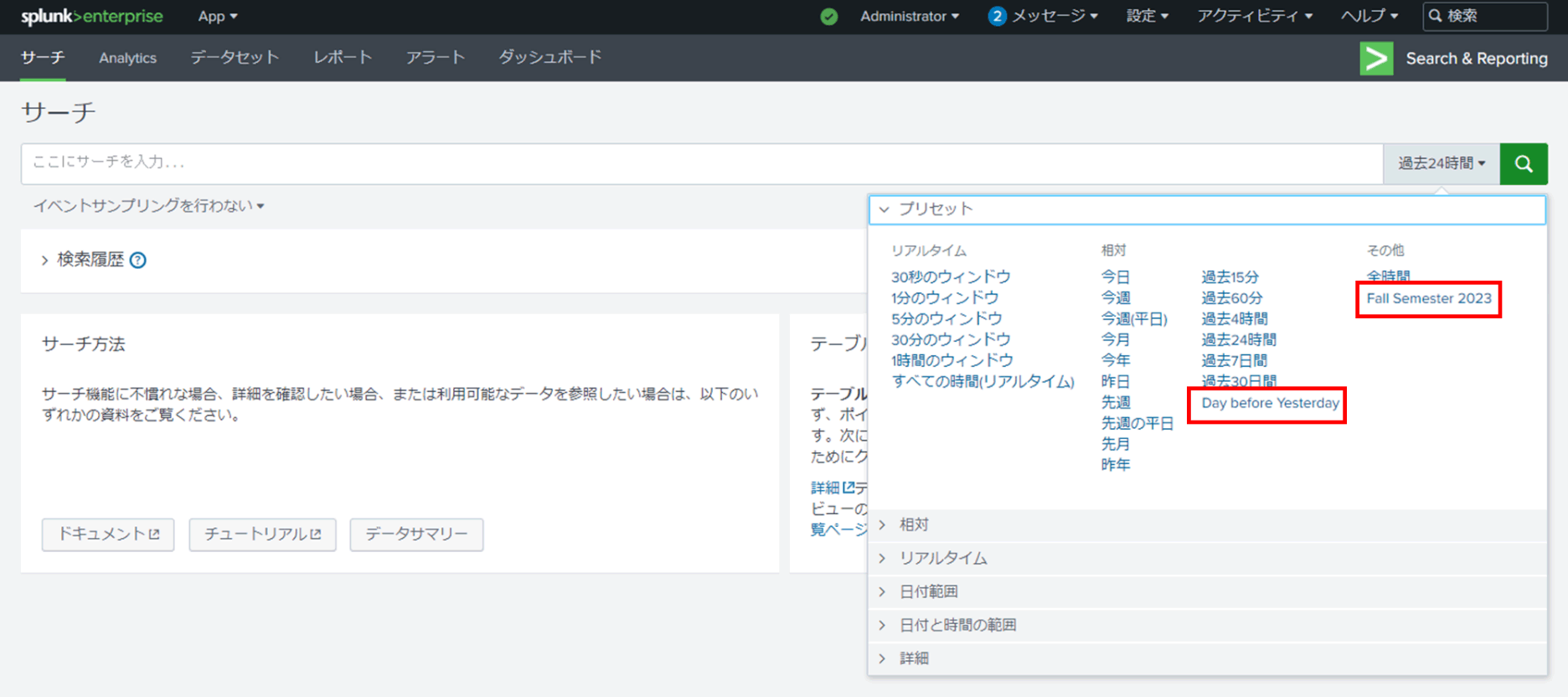
以上
- times.confを、テキストエディタ等で開きます。
サーチ結果の保存期間について
- 公開日
- 2015-05-05
- 最終更新日
- 2018-11-22
- バージョン
- Splunk Enterprise 6.3.0
- 概要
- サーチ結果の保存期間は、サーチの方法とアラートアクションが実行されたかどうかによって異なります。保存期間の考え方と、変更方法について紹介します。
- 内容
-
サーチ結果の保存期間
サーチ結果の保存期間は、サーチの方法とアラートアクションが実行されたかどうかによって異なります。
- 手動でのサーチの場合の保存期間は、デフォルトで600秒です。
- スケジュールサーチ(アラートの実行等)の場合の保存期間は、デフォルトでスケジュール間隔の2倍となります。例えば1時間ごとにスケジュールが実行される場合、保存期間は2時間となります。
- 上記保存期間とは別に、スケジュールサーチでアラートアクションが実行された場合、実行されたアラートアクションで設定されている保存期間が有効となります。
保存されたサーチ結果は、Splunk Webのページ右上のアクティビティ>ジョブより、確認することが可能です。
またサーチ結果はdispatch領域(デフォルトでは$SPLUNK_HOME/var/run/splunk/dispatch)に保存されます。
※デフォルトインストールの場合
<Linux>
$SPLUNK_HOME : /opt/splunk
<Windows>
$SPLUNK_HOME : C:\Program Files\splunkスケジュールサーチの保存期間の変更方法
設定例: Search Appで作成した保存済みサーチ「sample」に、100秒の保存期間を設定する場合
【GUIによる設定手順】
Splunk Enterprise 6.3.0以降のバージョンでは、GUIからも設定値を変更することが可能です。
GUIから設定を変更する場合、Splunkサービスの再起動は不要です。
- SplunkWebのGUI画面を開きます。
- 右上のメニューより「設定>サーチ、レポート、アラート」をクリックします。
- サーチ名「sample」のアクション欄から「詳細編集」をクリックします。
- 「dispatch.ttl」のパラメータの数値を100へ変更します。
(デフォルト値の2pはスケジュール間隔の2倍を意味します) - 画面右上の「保存」をクリックします。
【CLIによる設定手順】
Splunk Enterprise 6.3.0よりも前のバージョンをご利用の場合、以下の手順で設定ファイルを直接編集する必要があります。
- 下記いずれかの設定ファイルに下記設定を追記します。
- スケジュールサーチがプライベートで設定されている場合
$SPLUNK_HOME/etc/users/ユーザ名/search/local/savedsearches.conf - スケジュールサーチをAppで共有している場合
$SPLUNK_HOME/etc/apps/search/local/savedsearches.conf
記入例:
[sample]
dispatch.ttl = 100※[]内にサーチ名、dispatch.ttlに保存期間を秒数で記載します。
- 設定変更後、Splunkサービスを再起動します。
アラートアクションが実行された場合の保存期間の変更方法
設定例:メール送信のアラートアクションで、100秒の保存期間を設定する場合
- 下記いずれかの設定ファイルに下記設定を追記します。
- システム全体で保存期間を変更する場合
$SPLUNK_HOME/etc/sytem/local/alert_actions.conf - App別に保存期間を変更する場合
$SPLUNK_HOME/etc/apps/<App名>/local/alert_actions.conf
記入例:
[email]
ttl = 100※[]内にアラートアクション名、ttlに保存期間を秒数で記載します。
※スケジュールサーチの保存期間とパラメーター名が異なります。
- 設定変更後、Splunkサービスを再起動します。
以上
デプロイメントサーバーおよびクライアント機能の有効化/無効化の方法
- 公開日
- 2017-10-23
- 最終更新日
- 2023-12-11
- バージョン
- Splunk Enterprise 9.0.0
Splunk Universal Forwarder 9.0.0
- 概要
- デプロイメントサーバー及びデプロイメントクライアント機能を有効化/無効化する方法
- 内容
-
デプロイメントサーバー機能有効化/無効化の設定方法と確認方法
有効化/無効化の設定方法
- 有効化
デプロイメントサーバーのCLIで以下のコマンドを実行します。
$SPLUNK_HOME/bin/splunk enable deploy-server - 無効化
デプロイメントサーバーのCLIで以下のコマンドを実行します。
$SPLUNK_HOME/bin/splunk disable deploy-server
$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
Linux : /opt/splunk
Windows : C:\Program Files\Splunk※機能を無効化した場合はSplunkサービスの再起動は不要です。
機能の有効/無効の確認方法
上記有効化/無効化のコマンドを実行すると以下のように設定値が変わります。設定ファイルから設定の有効/無効を確認することが可能です。
<設定ファイル>
$SPLUNK_HOME/etc/system/local/serverclass.conf<設定例>
[global]
disabled = trueデプロイメントサーバー機能はdisable=trueもしくは1の時は無効、falseもしくは0の時は有効です。
デプロイメントクライアント機能有効化/無効化の設定方法と確認方法
有効化/無効化の設定方法
- 有効化
デプロイメントクライアントのCLIで以下のコマンドを実行します。
$SPLUNK_HOME/bin/splunk enable deploy-client - 無効化
デプロイメントクライアントのCLIで以下のコマンドを実行します。
$SPLUNK_HOME/bin/splunk disable deploy-client
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
(Universal Forwarderの場合)
Linux :/opt/splunkforwarder
Windows :C:\Program Files\SplunkUniversalForwarder(Heavy Forwarderの場合)
Linux :/opt/splunk
Windows : C:\Program Files\Splunk上記コマンドで機能を有効化/無効化した場合、設定を反映させるためにSplunkサービスの再起動が必要です。
機能の有効/無効の確認方法
上記有効化/無効化のコマンドを実行すると以下のように設定値が変わります。設定ファイルから設定の有効/無効を確認することが可能です。
<設定ファイル>
$SPLUNK_HOME/etc/system/local/deploymentclient.conf<設定例>
[deployment-client]
disabled = trueデプロイメントクライアント機能はdisabled=trueもしくは1の時は無効、falseもしくは0の時は有効です。
以上
- 有効化
特定の時刻よりも古いファイルを取り込まない方法(ignoreOlderThan の利用方法)
- 公開日
- 2018-06-05
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.5
- 概要
- inputs.confにignoreOlderThanパラメーターを使用し、特定の時刻よりも古いファイルを取り込まない方法
- 内容
-
inputs.confのパラメーターの一つであるignoreOlderThanを設定すると、Splunkはファイルの更新日時が設定された基準時刻よりも古いファイルは取り込まないという動作を行います。
inputs.conf 設定例
[monitor:///var/log/abc/xyz.log]
sourcetype = test
ignoreOlderThan = 1dなお、ignoreOlderThanで指定した時刻の基準の日時はSplunkのサービスが起動し、上記の設定を反映させた時刻となります。
この基準はSplunkを起動/再起動による設定の読み込み直しが発生しない限り、変わりません。例えば、2023/6/2 00:00:00に上述のようにignoreOlderThan=1dを設定し、/var/log/abc/xyz.logファイルの更新日時が2023/6/1 00:00:00より前の場合、Splunkへの取り込みの対象から除外されます。
※注意点※
ignoreOlderThanで指定した時間範囲の基準についてはSplunkの再起動を実施したタイミングで再起動を実施した日時に更新されます。
本FAQにて説明した内容の詳細に関しては、後述の参考資料をご確認ください。設定ファイルの確認方法
inputs.confにて設定した内容が正しく反映されているか確認する場合、以下のコマンドを実行し、設定した内容が表示されるか確認してください。
$SPLUNK_HOME/bin/splunk cmd btool inputs list※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
<Linux>
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder<Windows>
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder以上
MMDBファイルの更新手順
- 公開日
- 2018-10-03
- 最終更新日
- 2023-10-02
- バージョン
-
Splunk Enterprise 9.1
- 概要
- iplocationコマンドが参照しているMMDBファイル(ロケーション情報)は変更することが可能です。
limits.confの設定を変更することでMMDBファイルを更新することができます。
- 参考情報
-
- MMDBファイルの更新手順
- 内容
-
Splunkでiplocationコマンドを用いたとき、MaxMind社が提供しているMMDBファイルを参照して、ロケーション情報を出力しています。
MMDBファイルの更新手順
- Splunkサーバーの$SPLUNK_HOME/etc/system/local配下に移動し、limits.confをテキストエディタで開きます。(無い場合、limits.confを新しく作成してください。)
※$SPLUNK_HOMEのデフォルトのインストールパスは以下の通りです。
Linux: /opt/splunk/
Windows: C:\Program Files\splunk- limits.confに下記設定を追記してください。
==========
[iplocation]
db_path = <更新するMMDBファイルのフルパス>
==========(例)「$SPLUNK_HOME/etc」に配置している「GeoLite2-City.mmdb」に更新する場合
==========
[iplocation]
db_path = $SPLUNK_HOME/etc/GeoLite2-City.mmdb
==========- Splunkサービスを再起動してください。
補足情報
分散環境でサーチヘッドとインデクサーが別インスタンスになっている場合、サーチヘッドとインデクサー両方のMMDBファイルを更新してください。
以上
ローテートするログの取り込み設定方法
- 公開日
- 2015-05-07
- 最終更新日
- 2015-05-07
- バージョン
- Splunk Enterprise 6.0.1
- 概要
- ローテーションするログの取り込み設定方法について
- 参考情報
- 内容
-
Splunkは監視対象であるデータが取り込み済みかどうか、データのハッシュ値を見て判断しています。
ログがローテートされ圧縮形式に変換されるとハッシュ値が変わるため、Splunkは既に取り込み済みのデータでも新しいデータであると認識し、再度取り込みを行います。
ローテートしたファイルが圧縮形式になり、またローテートされたファイルが監視対象ディレクトリに含まれている場合、イベントの重複取り込みが発生する恐れがあります。
この場合、whitelistやblacklistの設定を行い、ローテートされたファイルを監視対象から除外することが可能です。
※whitelistとblacklist設定について
- whitelist:指定した文字列を含むファイル名のみ取り込みを行う
- blacklist:指定した文字列を含まないファイル名のみ取り込みを行う
特定のファイルを検索対象から除外する設定について
【whitelistにて特定のファイルのみ取り込み対象とする設定手順】
- 以下の設定ファイルを編集します。
$SPLUNK_HOME/etc/<任意のapp>/local/inputs.conf
[monitor://<監視対象ディレクトリおよびファイルのパス等>]
whitelist = \.log$※whitelistに取り込み対象を指定する正規表現を設定します。
- Splunkサービスを再起動します。
【blacklistにて特定のファイルのみ取り込み対象から除外する設定手順】
- 以下の設定ファイルを編集します。
$SPLUNK_HOME/etc/<任意のapp>/local/inputs.conf
[monitor://<監視対象ディレクトリおよびファイルのパス等>]
blacklist = \.gz$※blacklistに取り込み除外対象を指定する正規表現を設定します。
- Splunkサービスを再起動します。
以上
"
IPアドレス、ホスト名の変更方法
- 公開日
- 2016-12-13
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- IPアドレスやホスト名を変更する場合の変更箇所、及び手順
- 参考情報
-
- フォワーダーの転送設定
- デプロイメントサーバー/クライアントの設定
- ライセンスの設定
- https://docs.splunk.com/Documentation/Splunk/9.0.4/Admin/Serverconf#License_manager_settings_for_configuring_the_license_pool.28s.29
- https://docs.splunk.com/Documentation/Splunk/latest/DistSearch/PropagateSHCconfigurationchanges#Point_the_cluster_members_to_the_deployer
- https://docs.splunk.com/Documentation/Splunk/9.0.4/Admin/Configurealicensepeer
- サーチヘッドクラスタリング設定
- https://docs.splunk.com/Documentation/Splunk/9.0.4/Admin/Serverconf#search_head_clustering_configuration
- https://docs.splunk.com/Documentation/Splunk/latest/DistSearch/PropagateSHCconfigurationchanges#Point_the_cluster_members_to_the_deployer
- https://docs.splunk.com/Documentation/Splunk/9.0.4/DistSearch/Staticcaptain
- 内容
-
SplunkサーバーのIPアドレスやホスト名が変更になった場合に影響を受ける設定、及び変更方法について記載しています。
変更手順
変更手順は以下の通りです。
手順
- Splunkサービスを停止
- IPアドレスの変更、Splunkの設定を変更
- Splunkサービスの起動
※クラスター環境の場合、クラスター環境での停止順に従って停止を実施してください。
※フォワーダーをご利用の場合は、フォワーダーを停止した後にインデクサーを停止し、インデクサーの起動が完了してからフォワーダーを起動してください。
影響を受ける設定
Splunkサーバー名、デフォルトのホスト名の設定を変更する場合は、以下の設定を変更してください。
Splunkサーバー名
- confファイル名: $SPLUNK_HOME/etc/system/local/server.conf
- スタンザ名: general
- attribute名 : serverName
設定例)
[general]
serverName = myhostname1デフォルトホスト名
- confファイル名: $SPLUNK_HOME/etc/system/local/inputs.conf
- スタンザ名: default
- attribute名 : host
設定例)
[default]
host = myhostname1Splunkのホスト名やIPアドレスを変更する場合、以下の設定に影響があります。該当する設定箇所を変更してください。
- Splunkフォワーダーの転送先設定
- 分散サーチピアノードの設定
- デプロイメントサーバのデプロイ先サーバクラス設定
- デプロイメントクライアントのデプロイメントサーバ設定
- ライセンスマスタのプールのインデクサーの設定
- ライセンススレーブのマスタURI設定
- サーチヘッドクラスターメンバーの管理URIの設定
- サーチヘッドクラスターメンバーのデプロイヤーのURLの設定
- サーチヘッドクラスターメンバーの静的キャプテンの設定
- DMCの設定
- ネットワーク機器(syslogなど)の転送先設定
- 監視ツール(pingやプロセス起動状態の監視など)による監視先設定
以上
異なるフォーマットで出力されたデータのフィールド設定方法
- 公開日
- 2015.06.22
- 最終更新日
- 2015.06.22
- バージョン
- Splunk Enterprise 6.1.4
- 概要
- 同じsourcetype名で、異なるフォーマットで出力されたデータにそれぞれのフォーマットに対応したフィールド抽出の設定を行います
- 参考情報
-
- http://docs.splunk.com/Documentation/Splunk/6.1.4/Knowledge/Createandmaintainsearch-timefieldextractionsthroughconfigurationfiles#Create_advanced_search-time_field_extractions_with_field_transforms
- http://docs.splunk.com/Documentation/Splunk/6.1.4/Admin/Propsconf
- http://docs.splunk.com/Documentation/Splunk/6.1.4/Admin/Transformsconf
- 内容
-
同一ファイル内に異なる2種類のフォーマットが存在する場合、transforms.confに設定を行うことで、それぞれのフォーマットに合わせたフィールド抽出を行うことが可能です。
参考画像
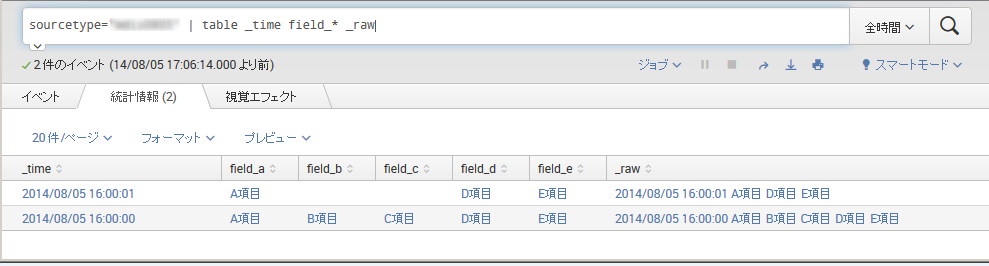
データ例および設定方法
データフォーマット: 下記の通りA,Bの両方のフォーマットのイベントが同一ソースに存在します。
A: 日時 A項目 B項目 C項目 D項目 E項目
B: 日時 A項目 D項目 E項目このデータをソースタイプ: sampleとして取り込むこととします。
設定手順
※設定ファイルは$SPLUNK_HOME/etc/<任意のapp>/local配下のものを編集します。
- transforms.confへ、A、Bそれぞれのケースでフィールド抽出できるように正規表現を設定します。
Aは、フォーマットに合わせて下記typeAの形式でフィールド抽出し、Bも同様に、フォーマットに合わせて下記typeBの形式でフィールド抽出します。
設定例:
[typeA]
REGEX = ^[^\s]+\s[^\s]+\s(?[^\s]*)\s(? [^\s]*)\s(? [^\s]*)
\s(?[^\s]*)\s(? [^\s]*)$ [typeB]
REGEX = ^[^\s]+\s[^\s]+\s(?[^\s]*)\s(? [^\s]*)\s(? [^\s]*)$ - props.confへと、1つのソースタイプに、REPORTを2つ設定します。
設定例:
[sample]
REPORT-sample = typeA,typeB※[]内はsourcetype等のスタンザ名を記載します。REPORT-<一意のクラス名> = <transforms.confで設定したスタンザ名> とします。
以上
_auditインデックスのサイズを縮小する方法
- 公開日
- 2015-08-10
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- _auditインデックスのサイズを縮小する方法について説明します。
- 内容
-
_auditインデックスについて
_auditインデックスには主にSplunkの動作履歴が内部ログとして蓄積されます。
_auditインデックスは、インストール直後、次のように設定されています。
インデックス名:_audit
最大サイズ:500,000MB (≒ 500GB)
保持期間:約6年利用状況により、増加量は異なりますが、長期間の運用を継続する事でディスク容量を圧迫する事につながる可能性があります。
_auditインデックスの最大サイズ変更手順
- SplunkWebにadminロールのユーザーでログインします。
- 右上の「設定」メニューから、「インデックス」を選択します。
- インデックスの一覧から、「_audit」をクリックします。
- 「インデックス全体の最大サイズ(MB)」を適切な値へ変更します。
- 「保存」ボタンをクリックします。
これにより、Splunkはサービスの再起動なしに、_auditインデックスの最大サイズの変更を行います。
ここで指定したサイズが、現在のインデックスサイズよりも小さい場合、超過した分の過去のデータが削除されますので、ご注意ください。
以上
Splunkからの外部通信を設定にてオフにする方法
- 公開日
- 2015-05-05
- 最終更新日
- 2017-05-26
- バージョン
- Splunk Enterprise 9.0.5
- 概要
- Splunkからの外部通信を設定にてオフにする方法を説明します。
- 参考情報
- 内容
-
外部通信の種類ついて
Splunkは以下AからDへのURLへアクセスを行います。
- A:Splunkの最新バージョン確認 https://quickdraw.splunk.com/js/
- B:Splunk.comへのログインページ https://www.splunk.com/page/sign_up
- C:オンラインヘルプ情報リンク https://quickdraw.splunk.com/help
- D:Appの最新バージョン確認 https://apps.splunk.com/api/apps
※上記リンクはブラウザーから直接アクセスできません。バージョン6.5より、上記のAからDに加えて以下E、Fに関しても通信が発生します。但し、E、Fの通信先は非公開となります。
6.5より、上記のAからDに加えて以下E、Fに関しても通信が発生します。但し、E、Fの通信先は非公開となります。
- E:Anonymized Usage Data※Splunkサーバーのパフォーマンス情報がSplunk社へ送信されます。
- F:License Usage Data※ライセンス使用状況がSplunk社へ送信されます。
※E、Fにて送信される情報に関しては以下のドキュメントをご参照下さい。
https://docs.splunk.com/Documentation/Splunk/9.0.5/Admin/Shareperformancedata
アクセスを無効化したい場合、以下の設定を行います。Universal Forwarder場合は、Appをインストールしている場合Dの通信が発生するため、Dのみ実施します。
※対象の設定ファイルが存在しない場合は新規作成し、設定を追加してください。
【A、BおよびCへのアクセスを無効にする設定手順】
- 以下の設定を追加して、保存します。
$SPLUNK_HOME/etc/system/local/web.conf
[settings]
updateCheckerBaseURL = 0
userRegistrationURL =
docsCheckerBaseURL =
設定詳細:
Aを無効にする場合、以下のように記載します。
updateCheckerBaseURL = 0
Bを無効にする場合、以下のように記載します。
userRegistrationURL =
Cを無効にする場合、以下のように記載します。
docsCheckerBaseURL =
※userRegistrationURL および docsCheckerBaseURLの「=」の右側は空白です。 - Splunkを再起動します。
【Dへのアクセスを無効にする設定手順(全Appが対象)】
- 以下の設定を追加して、保存します。
$SPLUNK_HOME/etc/system/local/server.conf
[applicationsManagement]
allowInternetAccess = false - Splunkを再起動します。
【Dへのアクセスを無効にする設定手順(App単位で設定)】
App単位でバージョン確認を無効にする場合は以下の設定を行います。
- 以下の設定を追加して、保存します。
設定場所:
$SPLUNK_HOME\etc\apps\<対象のapp>\local\app.conf
設定内容;
[package]
check_for_updates = 0 - Splunkを再起動します。
【Eへのアクセスを無効にする設定手順】
- Splunkにログインします。
- 「設定」>「インストルメンテーション」> 「歯車」を開きます。
- Aggregated Usage Data 及び、Support Usage Dataにて「無効」をクリックします。
【Fへのアクセスを無効にする設定手順(全Appが対象)】
- 以下の設定を追加して、保存します。
$SPLUNK_HOME/etc/system/local/telemetry.conf
sendLicenseUsage = false - Splunkを再起動します。
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
<Linux>
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder<Windows>
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder以上
アラートメールのFromを変更する方法
- 公開日
- 2015-11-10
- 最終更新日
- 2023-05-19
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- アラートアクションにより送信されるメールの送信者(From)を変更する方法を記載します。
- 内容
-
アラートアクションにより送信されるメールの送信者(From)を変更する場合は、以下の方法で変更することができます。(2通りあります)
全アラートメール共通の送信者(From)を変更する場合
設定>サーバー設定 > メール設定のメール形式の「メール送信形式(Send emails as)」の値を変更します。
個々のアラート毎にメール送信者(From)を変更する場合
検索を行うサーバーのsavedsearches.confに下記を設定します。
<savedsearches.confの保存先パス>
- 権限が「プライベート」の場合
Linux:$SPLUNK_HOME/etc/users/<所有者>/<App名>/local/savedsearches.conf
Windows:$SPLUNK_HOME\etc\users\<所有者>\<App名>\local\savedsearches.conf
例)$SPLUNK_HOME/etc/users/admin/search/local/savedsearches.conf - 権限が「App」の場合
Linux:$SPLUNK_HOME/etc/apps/<App名>/local/savedsearches.conf
Windows:$SPLUNK_HOME\etc\apps\<App名>\local\savedsearches.conf
例)$SPLUNK_HOME/etc/apps/search/local/savedsearches.conf
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
Linux: Splunk Enterprise : /opt/splunk
Universal Forwarder: /opt/splunkforwarder
Windows: Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder: C:\Program Files\SplunkUniversalForwarder
<設定内容>[アラート名]action.email.from=<from用アドレス>
例)アラート名がtest_alert、from用アドレスがsplunk@macnica.co.jp の場合
[test_alert]
action.email.from=splunk@macnica.co.jp※設定変更後はsplunkサービスを再起動してください。
以上
- 権限が「プライベート」の場合
アラートやレポートによるルックアップテーブルの参照タイミング
- 公開日
- 2016-05-27
- 最終更新日
- 2024-07-01
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- ルックアップテーブルの更新をリアルタイムサーチに反映させる方法を記載します。
- 内容
-
リアルタイムサーチのルックアップテーブル参照タイミング
リアルタイムサーチをアラート/レポートとして利用している場合、参照するルックアップテーブルは最初にリアルタイムサーチを実行した時点のものが参照され続けます。
常に最新のルックアップテーブルをリアルタイムサーチに反映させるためにはupdate=trueオプションが必要になります。
- update=trueオプションがない場合
リアルタイムサーチは初めに参照したルックアップテーブルのみを参照し、それ以後、ルックアップテーブルが更新されてもリアルタイムサーチには反映されません。
サーチ実行例) sourcetype=cc | lookup testlookup zz OUTPUT xx yy
- update=trueオプションがある場合
リアルタイムサーチは常に最新のルックアップテーブルを参照します。
サーチ実行例) sourcetype=cc | lookup update=true testlookup zz OUTPUT xx yy
以上
取り込み対象/除外するファイルを正規表現で指定する方法
- 公開日
- 2017-02-27
- 最終更新日
- 2023-12-01
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- 取り込み対象/除外するファイルを正規表現で指定する方法について記載します。splunkへ取り込みたい/取り込み対象から除外したい場合、inputs.confのwhitelist/blacklistを設定することで、取り込み対象のファイルを正規表現により指定することが出来ます。
- 参考情報
-
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/Whitelistorblacklistspecificincomingdata
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/Specifyinputpathswithwildcards
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Admin/Inputsconf
- https://docs.splunk.com/Documentation/Splunk/9.0.3/Data/Monitorfilesanddirectories
- 内容
-
あるディレクトリ配下の複数のファイルをsplunkへ取り込みたい/取り込み対象から除外したい場合、inputs.confのwhitelist/blacklistを設定することで、取り込み対象のファイルを正規表現により指定することが出来ます。
※blacklistとwhitelistを併用した場合、blacklistの設定が優先して適用されます。
設定[monitor://<監視ディレクトリのパス>]
whitelist = <取り込み対象ファイルを指定する正規表現>
blacklist = <取り込み対象から除外するファイルを指定する正規表現>設定例1)/mnt/logsディレクトリ配下のファイルの内、ファイル名の末尾が「.log」のファイルだけ取り込む場合
$SPLUNK_HOME/etc/system/local/inputs.conf
--------
[monitor:///mnt/logs]
whitelist = \.log$
--------※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
Linux :
Splunk Enterprise : /opt/splunk
Windows :
Splunk Enterprise : C:\Program Files\Splunk設定例2)/mnt/logsディレクトリ配下のファイルの内、ファイル名の末尾が「.txt」のファイルだけ取り込み対象から除外する場合
$SPLUNK_HOME/etc/system/local/inputs.conf
--------
[monitor:///mnt/logs]
blacklist = \.txt$
--------また監視対象の複数のファイル/ディレクトリを指定する際、ワイルドカード「*」や「...」を使用してください。
ワイルドカード「*」を使用することで任意の複数の文字列を指定することが可能です。
ワイルドカード「...」を使用することで任意のサブディレクトリまで監視対象とすることが可能です。
設定例3)/DATA/testディレクトリ配下の下記のファイルを取り込む場合
監視対象ファイル:
/DATA/test/EVT_file_a.log1
/DATA/test/TXT_file_b.log2$SPLUNK_HOME/etc/system/local/inputs.conf
---
[monitor:///DATA/test/*_file_*.log*]
---設定例4)/DATA/配下の任意の「.log」ファイルを取り込む場合
監視対象ファイル:
/DATA/test/EVT_file_a.log1
/DATA/test/TXT_file_b.log2
/DATA/test/sample/text.log3$SPLUNK_HOME/etc/system/local/inputs.conf
---
[monitor:///DATA/.../*.log*]
---ワイルドカードの仕様やinputs.confの詳細につきましては参考情報もご参考ください。
以上
サーチヘッドクラスターへ展開されたAppの削除方法
- 公開日
- 2017-07-05
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- サーチヘッドクラスターへ展開されたAppを削除する場合、デプロイヤーを利用して削除することができます。ただし削除対象のAppが無効になっていた場合は削除できません。無効になっていた場合は一度有効にしてから削除してください。
- 更新履歴
- 2017/07/05 初版
2018/10/11 誤記修正(誤:apps.conf 正:app.conf)
2023/3/4 更新
- 内容
-
デプロイヤーを利用してサーチヘッドクラスターへ展開されたAppが不要となった場合、以下の方法にてクラスターから削除することが可能です。
設定手順
- デプロイヤーの$SPLUNK_HOME/etc/shcluster/apps ディレクトリから削除対象のAppを削除
- 以下のコマンドを実行
$SPLUNK_HOME/bin/splunk apply shcluster-bundle -target <URI>:<管理ポート> -
auth <管理ユーザー>:<パスワード>
- ※注1:
-
- target:任意のクラスターメンバーを指定してください。最終的にはすべてのメンバーに配布されるため、1つのサーバーのみの指定で問題ありません。
- auth:デプロイヤーのユーザ名・パスワード
- 管理ポートのデフォルトは8089です。
- ※注2:$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
-
- デフォルトインストールの場合の$SPLUNK_HOME
- Linux:Splunk Enterprise : /opt/splunk
- Windows:Splunk Enterprise : C:\Program Files\Splunk
注意点
- 削除対象のAppが無効になっていた場合
削除対象Appのapp.confにて以下のようにAppが無効になっていた場合、サーチヘッドクラスターからAppを削除することができません。
[install]
state = disabled無効になっているAppを削除する場合は、削除前に対象のAppを有効にしてください。手順は下記の通りです。
【手順】
デプロイヤーの$SPLUNK_HOME/etc/shcluster/apps/<削除対象のApp名>/local/app.confを以下のように変更
[install]
state = enabled以下のコマンドを実行
$SPLUNK_HOME/bin/splunk apply shcluster-bundle -target <URI>:<管理ポート> -auth <管理ユーザー>:<パスワード>
- Splunkの再起動について
Appの有効/無効を切り替えた時、及びAppの削除時には、最新の設定をSplunkに反映させるためSplunkの再起動が発生します。
サーチヘッドクラスター環境の場合、ダウンタイムを回避する為、すべてのサーチヘッドが一斉に再起動せず、タイミングをずらしながら順番に再起動されます。このため、サーチの行えない時間等は発生しませんが、影響の少ない時間帯を選んで作業を実施することをおすすめします。
以上
ユーザーに対して特定のダッシュボードを表示・検索のみ許可する方法
- 公開日
- 2017-07-05
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- ユーザーに対して特定のダッシュボードを表示・検索のみ許可する方法
- 参考情報
- 内容
-
ダッシュボードに関しては各ユーザーのロールに従い、制御されます。
このため、特定のユーザーに対して特定のダッシュボードのみ表示・検索を行えるようにする場合、共有しているダッシュボード毎に各ロールに対して読み取り権限の編集を実施する必要があります。作業内容としては以下の通りです。なお、以下の作業内容はロール、ユーザーともに新規作成する場合を想定したものとなります。
【作業概要】
- 手順1.ユーザー専用のロールを作成する
- 手順2.ユーザーを作成し、手順1にて作成したロールを割り当てる
- 手順3.ロールに対してダッシュボードの読み取り権限を付与する
【作業内容詳細】
以下の順序にてロール、ユーザーへ作成したロールの割り当て、ロールへの権限付与を行います。
手順1.ロールの作成手順- adminユーザーにてSplunk Webにアクセスします。
- 「設定」>「ロール」>「新しいロール」を選択します。
- 「権限」タブから利用したい権限を選択します。
- 「インデックス」タブにて作成中のロールが割り当てられるユーザーが検索できるインデックスを指定し、「保存」します。
※この時、ダッシュボードにて利用するインデックスを忘れずに指定してください。
手順2.新規ユーザー作成、ロール割り当て手順- adminユーザーにてSplunk Webにアクセスします。
- 「設定」>「ユーザー」>「新規ユーザー」を選択し、ユーザーを新規追加します。
- ユーザーの新規追加画面にて「ロールの割り当て」にて作成したユーザー専用のロールを選択して「選択済みアイテム」に追加し、「保存」します。
手順3.ダッシュボードの権限の設定- adminユーザーにてSplunk Webにアクセスします。
- Search & Reporting Appのダッシュボード一覧にて、対象のダッシュボードの「アクション」から「権限の編集」を選択します。
- 新規作成したロールに対して「読み取り」の権限のみ付与します。
なお、特定のユーザに対してダッシュボードを表示させない設定を行いたい場合、上述の方法にて該当のユーザに対する専用のロールを作成し、表示させたくないダッシュボードを編集する際に新規作成したロールに対しては読み取り・書き込み、いずれの権限も付与しない設定を行います。
以上
timechartコマンドで表示するグラフにすべての値を表示する方法
- 公開日
- 2017-09-01
- 最終更新日
- 2024-01-29
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- timechartコマンドで表示するグラフにすべての項目を表示する方法について説明します。
- 更新履歴
- 2018/08/02 limit オプションの「limits」を「limit」に修正
2017/06/01 初版
- 内容
-
Search Appの視覚エフェクトにてグラフを表示する際、以下のような場合があります。
- 値が「NULL」であるものも結果の一つとして集計され表示される
- 表示する項目が多い場合、「OTHER」にまとめられ、表示される
 (図1)表示されるグラフに「NULL」や「OTHER」が含まれている状態
(図1)表示されるグラフに「NULL」や「OTHER」が含まれている状態上記のような場合、サーチクエリ内のtimechartコマンドに以下のようなオプションを利用する事で「NULL」の項目を非表示にし、かつ、「OTHER」に含まれてる全ての項目を凡例に表示することが可能です。
- usenull オプション
サーチ結果の値が「NULL」になっている項目についてはグラフの表示から除外します。「NULL」の項目を非表示にする場合は usenull=false をサーチ文に利用します。 - useother オプション
表示する項目が多い場合にまとめられた項目を「OTHER」として表示します。サーチ文に useother=false を利用した場合、まとめられた「OTHER」の項目は非表示となります。 - limit オプション
グラフ上に表示される項目の数に制限を設けるオプションです。limit = N をサーチ文に含めることでグラフ上に N個の項目を表示する事が出来ます。サーチ結果に含まれる全項目のグラフに表示する場合、 limit = 0 をサーチ文に利用します。
上記オプションを利用し、サーチ文を実行した場合、以下のように「NULL」を非表示にしたうえで「OTHER」に丸められていた全ての項目をグラフ上に表示する事が可能となります。
【サーチ文 実行例】
<検索対象> | timechart span=1month sum(value) by extracted_host usenull=false useother=false (図2)上記オプションを利用し「NULL」を表示せず、「OTHER」に含まれた全項目を表示した状態
(図2)上記オプションを利用し「NULL」を表示せず、「OTHER」に含まれた全項目を表示した状態以上
検索結果上で特定キーワードを目立たせる方法
- 公開日
- 2017-06-05
- 最終更新日
- 2023-04-06
- バージョン
-
Splunk Enterprise 9.0.4
- 概要
- 検索結果上で特定キーワードを目立たせる方法を紹介します。
- 内容
-
キーワード検索について
Splunkではキーワード検索を実施すると、イベント上の該当キーワードがハイライトされます。
しかしながら、該当キーワードを含まない検索を実行した時には、ハイライトがされないためイベントのどこにキーワードが出力されているのかを探す必要があります。
highlightコマンドと呼ばれるコマンドを実行することで、任意のキーワードをハイライトさせることが出来るためイベント上から特定キーワードが出力されている箇所を目視で探すことが容易になります。
highlightコマンドついて
highlightコマンドは引数に取ったキーワードをハイライトすることが出来ます。
使用方法は以下になります。
<検索文> | highlight <キーワード>例えば、以下のように検索を実行することでerrorというキーワードを目立たせることが出来ます。
<検索文> | highlight error
以上
ログ取り込み時にマスキングする方法
- 公開日
- 2016-10-11
- 最終更新日
- 2023-09-13
- バージョン
- Splunk Enterprise 9.1.0
- 概要
- ログ取り込み時にマスキングする方法
- 内容
-
ログデータを取り込む際にtransforms.confでマスクをかけて、個人情報などを匿名化することが出来ます。
特定の文字列をマスキングする場合、REGEX※1でマスキング対象の前後を挟むような形で正規表現を指定し、FORMAT※2でマスクキングの出力形式を指定します。その後DEST_KEYで_rawを指定して、データの上書きを行います。
※1.REGEXとはログデータにかける正規表現を指定します。
※2.FORMATとは追加したい任意のフィールド名または値を含むイベントの出力形式を指定します。
※3.DEST_KEYとはFORMATの結果を反映させる対象を指定します。
<データ例>
"2006-09-21, 02:57:11.58", 122, 11, "Path=/LoginUser Query=CrmId=ClientABC&ContentItemId=TotalAccess&SessionId=3A1785URH117BEA&Ticket=646A1DA4STF896EE&SessionTime=25368&ReturnUrl=http://www.clientabc.com, Method=GET,IP=209.51.249.195,Content=", ""<設定例>
--------------------
props.conf
--------------------
[対象ソースタイプ名]
TRANSFORMS-anonymize = anonymizer
--------------------
transforms.conf
--------------------
[anonymizer]
REGEX = (?m)^(.*)SessionId=\w+(\w{4}[&"].*)$
FORMAT = $1SessionId=##$2
DEST_KEY = _raw<マスク結果>
...SessionId=3A1785URH117BEA...
↓
...SessionId=##7BEA...Splunkの正規表現はPerl正規表現を利用しています。
Splunkで利用できる正規表現につきましては、以下のドキュメントをご参考ください。
※(?m)は複数行モードで正規表現を実行します。
※(.*)は任意の文字の繰り返しにマッチします。
※設定例の正規表現ではログデータの行頭から"SessionId="までと"SessionId="後の&の前4文字以降にマッチします。
以上
アンチウイルス製品のスキャン除外対象のプロセスとディレクトリについて
- 公開日
- 2016.11.14
- 最終更新日
- 2024-03-04
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- アンチウイルス製品のスキャン除外対象のプロセスとディレクトリについて説明します。
- 内容
-
アンチウィルス製品をインストールしたホストにてSplunkを実行する場合、すべてのSplunkプロセスとSplunkインストールディレクトリをスキャン除外対象とすることを強く推奨いたします。
スキャン除外対象のプロセスとディレクトリについて、以下に記載いたします。
除外対象プロセス
-------------
Unix/Linux
-------------
bloom
btool
btprobe
bzip2
cherryd
classify
exporttool
locktest
locktool
node
python*
splunk
splunkd
splunkmon
tsidxprobe
tsidxprobe_plo
walklex
-------------
Windows
-------------
splunk-admon.exe
splunk-compresstool.exe
splunk-MonitorNoHandle.exe
splunk-netmon.exe
splunk-optimize-lex.exe
splunk-optimize.exe
splunk-perfmon.exe
splunk-regmon.exe
splunk-winevtlog.exe
splunk-winhostinfo.exe
splunk-winprintmon.exe
splunk-wmi.exe
splunk.exe
splunkd.exe除外対象ディレクトリ
- Splunk Enterpriseの場合
- $SPLUNK_HOME配下の全てのディレクトリ
- $SPLUNK_DB配下の全てのディレクトリ
※indexes.confファイルにて、インデックス単位で保存先ディレクトリを設定している場合は、そのディレクトリも除外対象としてください。
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下の通りです。
<Linux>
/opt/splunk<Windows>
C:\Program Files\Splunk※$SPLUNK_DBはSplunkのインデックスデータ格納先ディレクトリを指しており、デフォルトでは以下の通りです。
<Linux>
/opt/splunk/var/lib/splunk<Windows>
C:\Program Files\Splunk\var\lib\splunk- Splunk universal forwarderの場合
- $SPLUNK_HOME配下の全てのディレクトリ
- /Applications/splunkforwarder配下のディレクトリ(OS Xの場合)
※$SPLUNK_HOMEはSplunkのインストールディレクトリを指しており、デフォルトでは以下の通りです。
<Linux>
/opt/splunkforwarder<Windows>
C:\Program Files\SplunkUniversalForwarder以上
過去のWindowsイベントログを取り込まない方法
- 公開日
- 2017-09-01
- 最終更新日
- 2023-07-28
- バージョン
- Splunk Enterprise 9.0.4
Splunk UniversalForwarder 9.0.4
- 概要
- 過去のWindowsイベントログを取り込まない方法
- 内容
-
Windowsイベントログ取り込み時のデフォルトの動作
Windowsイベントログはinputs.confに[WinEventLog://<name>]の設定を追加することで取得することができます。
例:
アプリケーションログの場合
[WinEventLog://Application]
disabled = 0Windowsイベントログを取り込む場合、Splunkは過去のイベントログから順次読み込みを開始します。
※1年前のWindowsイベントログがあれば、1年前のものから読み込みを開始します。
「current_only」パラメーターの仕様とデータ取り込み状況の管理方法
inputs.confには、「current_only」というパラメーターがあります。デフォルトでは0(無効)と設定されていますが、こちらを1(有効)にすることにより「Splunkが起動している間に生成されたWindowsイベントログのみ」取得します。
例えば、「current_only = 1」の設定をしてWindowsイベントログの取り込みを 7/1 12:00 に開始したとします。
この場合、 7/1 12:00以降でSpklukサービスが起動している間に出力されたWindowsイベントログが取り込みの対象となります。
※7/1 12:00 より前に出力されていた過去のWindowsイベントログは取り込みの対象となりません。
また、Windowsイベントログを取り込む場合、[monitor://<path>]などのデータ取り込みとは別に、[WinEventLog://<name>] 固有で取り込み状況を管理しており、Splunkは取り込み済みイベントログより過去のイベントログを取り込み対象から除外する仕様となっています。
※[WinEventLog://<name>] ではレコードナンバーで取り込み状況を管理しています。
過去のWindowsイベントログを取り込まない方法
上述した仕様を利用して、取り込み設定を追加した後に出力されたWindowsイベントログのみを取得するように動作させることが可能です。
【操作手順】- Windowsイベントログ出力元のSplunkサーバーにて以下のような設定を追記します。
例:初回取り込み時
$SPLUNK_HOME/etc/<任意のapp>/local/inputs.conf
[WinEventLog://<name>]
index = test
...(省略)
current_only = 1※Windowsイベントログの場合、Splunkが自動でソースタイプを認識する為、「sourcetype = 」の設定は不要です。
※デフォルトインストールの場合
$SPLUNK_HOME(Linux) : /opt/splunk
$SPLUNK_HOME(Windows) : C:\Program Files\splunk- Splunkサービスの再起動をします。
$SPLUNK_HOME/bin/splunk restart- Windowsイベントログが取り込まれたことをサーチから確認します。
ここでWindowsイベントログを取り込むことで、Splunkは取り込み済みのイベントログより過去のWindowsイベントログを、取り込み対象から除外させます。
- 上記1.で追加した設定例から「current_only = 1」の設定を除外します。
例:current_onlyの除外
$SPLUNK_HOME/etc/<任意のapp>/local/inputs.conf
[WinEventLog://<name>]
index = test
...(省略)- Splunkサービスの再起動をします。
注意事項
a. 必ず上記3.の手順の際に、Windowsイベントログが取り込まれたことを確認してください。
b. 上記4.の手順で、「current_only = 1」の設定を除外しなかった場合、Splunkが停止している間に出力されたWindowsイベントログが取り込まれなくなります。
c. 上記4.5.の手順の際に、Windowsイベントログの取りこぼしが発生する可能性があります。
d. current_only はWindowsイベントログの取り込み設定([WinEventLog://<name>])にのみ有効なパラメータです。
以上
ダッシュボードからPDFを出力する時に使用するフォントを日本語に変更する方法
- 公開日
- 2015.10.09
- 最終更新日
- 2024.01.18
- バージョン
- Splunk Enterprise 9.1.2
- 概要
- ダッシュボードからPDFを出力する時に使用するフォントを日本語に変更する方法
- 参考情報
- 内容
-
Splunkでは、デフォルトの設定にて、ダッシュボードからPDFを出力する時に使用するフォントの優先度が日本語よりも中国語の方が高くなっています。
日本語のフォントでPDFを出力する為には、以下の設定を記載します。
設定手順
- $SPLUNK_HOME/etc/system/local 配下の、alert_actions.confをファイルを開きます。
(存在しない場合には新規作成します。) - 作成したalert_actions.conf ファイルに以下を記載します。
[email]
reportCIDFontList = jp gb cns kor - Splunkを再起動します。
$SPLUNK_HOME/bin/splunk restart
※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下の通りです。
Linux :
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarderWindows :
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder以上
- $SPLUNK_HOME/etc/system/local 配下の、alert_actions.confをファイルを開きます。
ユニバーサルフォワーダーでadminユーザーの初期パスワードを変更する方法
- 公開日
- 2015-10-22
- 最終更新日
- 2015-10-22
- バージョン
- Splunk Enterprise 6.3
- 概要
- ユニバーサルフォワーダーでadminユーザーの初期パスワードを変更する方法
- 内容
-
ユニバーサルフォワーダーでは、SplunkのWeb画面上からパスワードの変更ができません。
ユニバーサルフォワーダーでadminユーザーの初期パスワードを変更する場合は、コマンドを実行して変更します。
手順
下記のコマンドを実行します。
$SPLUNK_HOME/bin/splunk edit user
-username ユーザー名 -password 新パスワード -auth ユーザー名:旧パスワード※$SPLUNK_HOMEはSplunkのインストールディレクトリです。
デフォルトインストールの場合のパス情報
Linux:/opt/splunkforwarder
Windows:C:\"Program Files"\SplunkUniversalForwarderコマンドの例
- Linuxの場合
/opt/splunkforwarder/bin/splunk edit user
-username admin -password macnica -auth admin:changeme- Windowsの場合
C:\"Program Files"\SplunkUniversalForwarder\bin\splunk.exe edit
user -username admin -password macnica -auth admin:changeme以上
データ保存先フォルダパスの変更方法
- 公開日
- 2016-02-29
- 最終更新日
- 2016-07-07
- バージョン
- Splunk Enterprise 6.3.2
- 概要
- Splunkのインデックスデータの保存先ディレクトリを変更する手順について
- 内容
-
Splunkのインデックスデータ保存先の変更手順は以下となります。
本番環境に実施する前に一度検証環境にて動作を確認されることを推奨します。なお、クラスター構成の場合はこの限りではございませんので、ご注意ください。
Linux環境の場合
- 保存先のファイルシステム上に、rawデータの合計サイズの1.2倍以上の十分な空き容量があることを確認します。
- 必要に応じて、インデックスデータ保存先にディレクトリを作成し、Splunkの起動ユーザーに対してアクセス権があることを確認します。
例:
mkdir /home/splunkdata
chown -R splunk:splunk /home/splunkdata
chmod +rw -R /home/splunkdata- Splunkを停止します。
例:
/opt/splunk/bin/splunk stop※$SPLUNK_HOMEはSplunkのインストールディレクトリです。デフォルトインストールの場合: /opt/splunk
- 2.で作成したディレクトリ配下へデータを移動します。
例:
mv /opt/splunk/var/lib/splunk/* /home/splunkdata/- 環境変数をクリアします。
例:
unset SPLUNK_DB- $SPLUNK_HOME\etc\splunk-launch.confを編集して新たなデータ保存先を指定します。
例:
vi /opt/splunk/etc/splunk-launch.confSPLUNK_DB = /home/splunkdataを追記します。
※必要に応じてsplunk-launch.confは予めバックアップを取得してください。
- Splunkを起動します。
例:
/opt/splunk/bin/splunk start>- Webブラウザ経由でSplunkへアクセスし、作業前に取り込んだデータが検索できるとともに、新たなデータも取り込まれていることを確認します。
Windows環境の場合
- 変更したいドライブもしくはディレクトリに十分な空き容量があることを確認します。
※ネットワークドライブを保存先に使用することは、非推奨かつサポートしておりませんのでご注意ください。
- 必要に応じて、インデックスデータ保存先にディレクトリを作成し、Splunkの起動ユーザーに対してアクセス権があることを確認します。
例:
C:\Program Files\Splunk> D:D:\> mkdir \new\path\for\indexD:\> cacls D:\new\path\for\index /T /E /G:F - Splunkを停止します。
例:
C:\"Program Files"\Splunk/bin/splunk stop※$SPLUNK_HOMEはSplunkのインストールディレクトリです。デフォルトインストールの場合: C:\"Program Files"\Splunk
※コントロールパネルからサービスを停止することも可能です
- 2.で作成したディレクトリ配下へインデックスデータをコピーします。
例:
xcopy "C:\Program Files\Splunk\var\lib\splunk\*.*" D:\new\path\for\index /s /e /v /o /k※$SPLUNK_HOMEはSplunkのインストールディレクトリです。デフォルトインストールの場合: C:\"Program Files"\Splunk
※コントロールパネルからサービスを停止することも可能です
- 環境変数をクリアします。
例:
set SPLUNK_DB=- $SPLUNK_HOME\etc\splunk-launch.confを編集して新たなデータ保存先を指定します。
例:ファイル内に以下を追記します。
SPLUNK_DB=D:\new\path\for\index※必要に応じてsplunk-launch.confは予めバックアップを取得してください。
- Splunkを起動します。
例:ファイル内に以下を追記します。
C:\"Program Files"\Splunk/bin/splunk start- Webブラウザ経由でSplunkへアクセスし、作業前に取り込んだデータが検索できるとともに、新たなデータも取り込まれていることを確認します。
以上
特定のイベントを取り込まない方法
- 公開日
- 2018-06-18
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.1.0
- 概要
- ログデータを取り込む際、transforms.confの設定(REGEX、FORMAT、DEST_KEY)を使用することで、特定のログデータをフィルタリングをすることができます。ヘッダー行や特定の文字列を含むイベントを除外して取り込む際にご利用ください。
- 内容
-
特定のイベントを正規表現によりフィルタリングを行い取り込せないようにする手順
【手順】
- transforms.confに除外対象とするイベントを正規表現で指定します。
/opt/splunk/etc/system/local/transforms.conf が存在しない場合は新規作成します。
[null1]※ REGEX = <正規表現A>※ DEST_KEY = queue FORMAT = nullQueue [null2]※ REGEX = <正規表現B>※ DEST_KEY = queue FORMAT = nullQueue設定例:msg=aaa、もしくはmsg=bbbという文字列が含まれるイベントを除外して取り込む場合
[null1] REGEX =msg\=aaa DEST_KEY = queue FORMAT = nullQueue [null2] REGEX =msg\=bbb DEST_KEY = queue FORMAT = nullQueue;補足
- 必ずUTF-8で保存してください。
- transforms.confにおいて、「DEST_KEY」,「FORMAT」の部分は変更不要です。
- 正規表現A、及び正規表現Bには除外したい文字列にマッチするような正規表現を記載する必要がございます。
※印の部分(スタンザ名、正規表現)は御社環境に合わせた設定をお願い致します。
- props.confで、ログのソースタイプの既存行の下に取り込み設定を追記します。
[<ソースタイプ名>]TRANSFORMS-null=null1,null2
設定例:ソースタイプtestに対する設定
[test] TRANSFORMS-null=null1,null2補足
- 上記はソースタイプに対する設定となりますがソースタイプの他に、ホスト、ソースに対して適用することも可能です。
- 設定値の記載方法TRANSFORMS-<一意のクラス名>=<transforms.confにおいて使用したスタンザ名>
- ここではクラス名をnullとし、transforms.confの設定にてnull1, null2を使用しているためイコールの右側にカンマで区切って設定しています
- Splunkを再起動します。
【注意事項】
- 設定はインデックスサーバー(もしくはヘビーフォワーダー)上で行います。(ユニバーサルフォワーダー上では設定できません)
- 設定を行った後に取り込まれるイベントのみが対象となります。すでに取り込まれたイベントは削除されません。
以上
CSVデータのフィールド抽出方法
- 公開日
- 2018-06-18
- 最終更新日
- 2023-11-27
- バージョン
- Splunk Enterprise 9.0.4
- 概要
- CSVファイルを取り込みフィールドを抽出する方法
- 参考情報
- 内容
-
CSVファイルを取り込みフィールド抽出する方法は下記3通りの方法があります。
- サーチ時にフィールド抽出する方法
- データ取り込み時にフィールド抽出する方法
2-1.Splunk Webを使ってフィールド抽出する方法
2-2.設定ファイルへ記述してフィールド抽出する方法
- サーチ時にフィールド抽出する方法
サーチ時にフィールド抽出するには、以下のように設定ファイルに記載をします。
【概要】
- props.confおよびtransforms.confにフィールド抽出する設定を記載します。※詳細は後述
- 手順1で作成したソースタイプをinputs.confへ記載します。※詳細は後述
- 手順2でinputs.confを変更した場合、そのサーバーのSplunkサービスを再起動し、設定を有効にします。
===
$SPLUNK_HOME/bin/splunk restart
===※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
Linux :
Splunk Enterprise : /opt/splunk
Universal Forwarder : /opt/splunkforwarder
Windows :
Splunk Enterprise : C:\Program Files\Splunk
Universal Forwarder : C:\Program Files\SplunkUniversalForwarder上記の手順1、2の設定方法として2通りの方法をご紹介します。
方法1:データ取り込み後に区切り文字(カンマ)で抽出する方法
単純に区切り文字(CSVではカンマ)で区切ることのできるデータの場合、transforms.confの設定にて区切り文字(DELIMS)とフィールド名(FIELDS)を定義してフィールド抽出を行います。
<用途>
方法1ではカラム数が追加になった場合でも対応可能です。(推奨)
カラムが追加された場合、自動的に追加された部分のフィールド抽出はされません。追加した設定をすることで追加されたカラムもフィールド抽出が可能です。<データ例>
2015/01/01 00:00:00,aaaa,bbbb,ccc,ddd
2015/01/01 00:00:01,111,2222,333,ddd<設定例>
props.conf
配置場所:検索を行うSplunkサーバー
設定例:[testcsv]
KV_MODE = none
REPORT-testHeader = test_headertransforms.conf
配置場所:検索を行うSplunkサーバー
設定例:[test_header]
DELIMS = ","
FIELDS = "header_field1", "header_field2", "header_field3", "header_field4", "header_field5"inputs.conf (任意:既に設定している場合はスキップしてください)
配置場所:データ入力をするSplunkサーバーもしくはフォワーダー
設定例:[monitor:///opt/test/data/test1.csv]
sourcetype=testcsv※DELIMSにて区切り文字を指定します。
※FIELDSで各フィールドを定義します。
※フィールド文字には英数字およびアンダースコアを使用してください。
※props.confおよびtransforms.confの設定変更後、Splunkサービスの再起動は不要です。inputs.confの設定変更後はSplunkサービスの再起動が必要です。
※データ内にCSVのエスケープ文字(\\ あるいは ") が含まれる場合、方法1ではフィールド抽出ができません。この場合には方法2を使用します。方法2:データ取り込み後に正規表現を使用してフィールド抽出する方法
transforms.confの設定にて正規表現(REGEX)を使用してフィールド抽出を行います。
<用途>
方法2ではカラム数が追加になった場合は対応できません。方法1では対応できない抽出の場合のみ推奨しています。(カラムが追加されたことにより指定した正規表現に合致しなくなった場合、既存部分と追加された部分どちらもフィールド抽出されなくなります)
<データ例>
2015/01/01 00:00:00,aaaa,bbbb,ccc,ddd
2015/01/01 00:00:01,111,2222,333,ddd<設定例>
props.conf
配置場所:データ入力設定をしたSplunkサーバーもしくはフォワーダー
設定例:[testcsv]
INDEXED_EXTRACTIONS=csv
FIELD_NAMES="header_field1", "header_field2", "header_field3", "header_field4", "header_field5"inputs.conf
配置場所:データ入力設定をしたSplunkサーバーもしくはフォワーダー
設定例:[monitor:///opt/test/data/test2.csv]
sourcetype=testcsvfields.conf
配置場所:検索を行うSplunkサーバー
設定例:[sourcetype::testcsv::*]
INDEXED=True※header_field1はフィールド名です。(<>内にフィールド名を指定します。)
※props.confおよびtransforms.confの設定変更後、Splunkサービスの再起動は不要です。inputs.confの設定変更後はSplunkサービスの再起動が必要です。
※正規表現はあくまで一例です。実際の正規表現はお客様にて作成いただきますようお願いいたします。2. データ取り込み時にフィールド抽出する方法
データ取り込み時にフィールド抽出するには、Splunk Webから設定する方法と設定ファイルへ記述して設定する方法の2種類がございます。
2-1. Splunk Webを使ってフィールド抽出する方法
CSVファイルにヘッダーがある場合、ヘッダーがない場合それぞれの方法を記載します。※この方法を利用して設定ができるのは、以下の環境に限られます。下記以外の環境は「2-2. 設定ファイルへ記載してフィールド抽出する方法」をご利用ください。
スタンドアロン環境
Splunk Webを有効にしているヘビーフォワーダーCSVファイルにヘッダーがある場合
- SplunkWebにログインします。
- 設定>データの追加をクリックします。
- データの追加画面で「アップロード」を選択します。
- ソースの選択画面でCSVファイルをドラッグ・アンド・ドロップします。
- 「次へ」ボタンをクリックします。
- ソースタイプの設定画面にてソースタイプボタンをクリックし、Structured>csvを選択します。
(ソースタイプが「csv」になっている場合はそのままにします) - 表示されるイベント値がフィールドごと分けられていることを確認します。
- (任意)その他の設定を行います。
- 「名前を付けて保存」ボタンをクリックします。
- ソースタイプ名や保存先App等を設定して「保存」ボタンをクリックします。
- 「次へ」ボタンをクリックします。
- ホストとインデックスを指定し「確認」ボタンをクリックします。
2-2. 設定ファイルへ記載してフィールド抽出する方法
CSVファイルにヘッダーがある場合、ヘッダーがない場合それぞれの方法を記載します。CSVファイルにヘッダーがある場合
CSVファイルの取り込み時にヘッダー行からフィールド情報を抽出します。
<データ例>
field1,field2,field3,field4,field5
2015/01/01 00:00:00,aaaa,bbbb,ccc,ddd
2015/01/01 00:00:01,111,2222,333,ddd※1行目がヘッダー行になります。
<設定例>
props.conf
配置場所:データ入力設定をしたSplunkサーバーもしくはフォワーダー
設定例:[testcsv]
INDEXED_EXTRACTIONS=csvinputs.conf
配置場所:データ入力設定をしたSplunkサーバーもしくはフォワーダー
設定例:[monitor:///opt/test/data/test2.csv]
sourcetype=testcsvfields.conf
配置場所:検索を行うSplunkサーバー
設定例:[sourcetype::testcsv::*]
INDEXED=True※props.confおよびinputs.confの設定変更後はSplunkサービスの再起動が必要です。
※fields.confの設定変更後は以下のURLへアクセスし、[refresh]ボタンを押して設定を適用します。http://<SplunkサーバーのIPアドレス>:8000/debug/refresh
CSVファイルにヘッダーがない場合
CSVファイルの取り込み時に、ヘッダーフィールドを指定します。
<データ例>
2015/01/01 00:00:00,aaaa,bbbb,ccc,ddd
2015/01/01 00:00:01,111,2222,333,ddd<設定例>
props.conf
配置場所:検索を行うSplunkサーバー
設定例:[testcsv]
REPORT-testHeader=test_headertransforms.conf
配置場所:検索を行うSplunkサーバー
設定例:[test_header]
REGEX = ^(?<header_field1>[^,]+),(?<header_field2>[^,]+),(?<header_field3>[^,]+),(?<header_field4>[^,]+),(?<header_field5>[^,]+)inputs.conf(任意:既に設定している場合はスキップしてください)
配置場所:データ入力設定をしたSplunkサーバーもしくはフォワーダー
設定例:[monitor:///opt/test/data/test2.csv]
sourcetype=testcsv※props.confおよびinputs.confの設定変更後はSplunkサービスの再起動が必要です。
※fields.confの設定変更後は以下のURLへアクセスし、[refresh]ボタンを押して設定を適用します。http://<SplunkサーバーのIPアドレス>:8000/debug/refresh
補足情報
Splunkは先頭の256バイトで取り込み対象のファイルを識別します。
CSVファイルのヘッダー部分など先頭の256バイトに同じデータがある場合、ファイルの中身が異なっていても、先頭の256バイトで既存と同一ファイルとみなして取り込みをしません。
ファイルの先頭に同じデータ(ヘッダー)があっても別ファイルと認識し、新規ファイルを取り込ませる場合、inputs.confファイルに以下を設定します。
<設定例>
[monitor:///tmp]
crcSalt = <SOURCE>※[monitor:///tmp]のパス情報(/tmp)は環境に応じて読み替えを行ってください。
以上
ユーザーやロール単位で同時サーチ実行数を制限する方法
- 公開日
- 2018-06-18
- 最終更新日
- 2024-01-11
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- 各ユーザーやロール単位で同時サーチ実行数を制限する
- 参考情報
- 内容
-
Splunk側の設定において、各ユーザーの同時サーチジョブ数、同時リアルタイム検索数の上限および各ロールの同時サーチジョブ数、同時リアルタイム検索の合計数の上限を制限することが可能です。
設定方法
- Splunk Webにてadmin権限をもつユーザーにてログインし、「設定」>「ロール」より、設定を行いたいロール名をクリックし、「5.リソース」タブより以下の値を変更します。
- ロールレベルの同時サーチジョブ数限度
- ロールレベルの同時リアルタイムサーチジョブ数限度
- ユーザーレベルの同時サーチジョブ数限度
- ユーザーレベルの同時リアルタイムサーチジョブ数限度
- ロールレベルでのジョブ数限度の設定を有効にするために設定ファイルに以下を追記します。
$SPLUNK_HOME/etc/system/local/limits.conf
[search]enable_cumulative_quota = true※$SPLUNK_HOMEはインストールディレクトリです。デフォルトでは以下です。
Linux : /opt/splunk
Windows : C:\Program Files\Splunk- 上記2.の設定を反映させるために、Splunkサービスを再起動します。
以上
SplunkWebを日本語で表示する方法
- 公開日
- 2018-06-18
- 最終更新日
- 2023-12-05
- バージョン
- Splunk Enterprise 9.0.3
- 概要
- SplunkWebを日本語で表示する方法を紹介します
- 参考情報
- 内容
-
SplunkWebを日本語で表示する方法を含め、表示言語の変更方法をご案内します。
SplunkWebで表示言語を指定する方法
表示言語については、アクセスするURLで指定できます。
一度指定した表示言語は、セッションが有効な間はそのまま維持されます。SplunkWebのURLは以下の形式となっておりますので、<表示言語>に表示する言語を指定することができます。
http://<IPアドレスまたはサーバー名>:<ポート>/<表示言語>/ . . .
以下の例は、英語と日本語のログイン画面のURLです。
・英語
http://<IPアドレスまたはサーバー名>:8000/en-US/account/login・日本語
http://<IPアドレスまたはサーバー名>:8000/ja-JP/account/login利用可能な言語指定
Splunkでは、以下の言語指定をデフォルトで利用可能です。
- de-DE(ドイツ語/ドイツ)
- en-GB(英語/イギリス)
- en-US(英語/アメリカ)
- fr-FR(フランス語/フランス)
- it-IT(イタリア語/イタリア)
- ja-JP(日本語/日本)
- ko-KR(韓国語/韓国)
- zh-CN(中国語/中国)
- zh-TW(中国語/台湾)
言語および地域(ロケール)を追加する場合は以下のドキュメントを参照ください。
https://docs.splunk.com/Documentation/Splunk/9.0.3/AdvancedDev/TranslateSplunk
以上
株式会社マクニカ Splunk 担当
- TEL:045-476-2010
- E-mail:splunk-sales@macnica.co.jp
平日 9:00~17:00




