Splunk
スプランク
Splunk技術ブログ 第3弾 ~プレミアムサポート事例 インデクサーのキュー詰まり軽減編~

はじめに
こんにちは、マクニカ Splunk サポート担当です。
Splunk技術ブログ 第3弾 ~プレミアムサポート事例 インデクサーのキュー詰まり軽減編~では、インデクサーのキューが詰まっている時の対処方法について、実際のお問い合わせ事例をもとにご紹介します。
キューの詰まりとは?というところから解説をしておりますので、よろしければ参考にしてみてください。
※なお、本記事の内容はプレミアムサポート 利活用支援パッケージを購入いただいたお客様への支援事例となります。当該パッケージサービスに関しては以下をご確認ください。https://www.macnica.co.jp/business/security/manufacturers/splunk/premium_support.html
お客様のご要望
- インデクサーでキュー詰まりの傾向がみられるので解消したい
インデクサーのキューの詰まりとは?
インデクサーでは、一連のパイプライン処理によってデータの解析・加工・取り込み等が行われます。
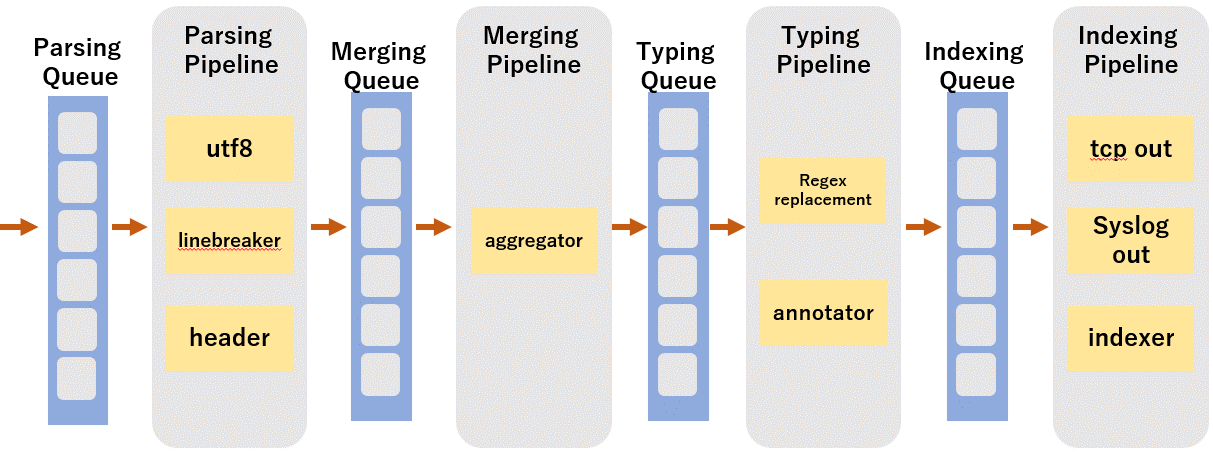
各パイプラインで行われる主な処理は以下の通りです。
Parsing Pipeline:データの文字コード変換やヘッダーの認識
Merging Pipeline:データのイベントへの変換やタイムスタンプの抽出
Typing Pipeline:正規表現を用いたイベントの加工処理
Indexing Pipeline:インデックスへのデータの書き込みや、他の転送先への転送処理
それぞれのパイプラインの前には、処理待ちのデータを滞留させるためのメモリ領域が用意されています。このメモリ領域のことをキューと言います。
つまり、キューが詰まっているということは、パイプラインのどこかで処理が滞ることにより、処理待ちデータ用のメモリ領域が逼迫している状態を指します。この状態が続くと、データ取り込み処理が遅延するなどの障害が発生する可能性があります。
したがってお客様は、今後のデータ取り込みに遅延が発生する可能性を考慮し、キュー詰まりの解消をご要望しています。
解決までの流れ
以下の流れで、お客様環境でのキュー詰まりの原因を調査し、解決策を提案します。
- お客様のインデクサーの状態把握
- 原因箇所の調査
- 対処策の立案・提案
- 対処策の実装
それぞれの項目について、順番にご説明します。
①お客様のインデクサーの状態把握
キューの状態は、Splunkの内部ログであるmetrics.logに出力されます。
お客様のインデクサーに出力されたmetrics.logについて、Splunkで解析を行うことにより、キューの状態を確認できます。
調査したところ、お客様のインデクサーのキューは以下の状態でした。
- Indexing Queueでは詰まりが発生していない。
- 取り込みデータ量が多い時に、Typing Queue以前のキューが詰まる傾向がみられる。
- 取り込みデータの量は、時間によってムラがある。
お客様の環境で発生している上記の事象を踏まえたうえで、原因となる箇所の特定、対処策の立案を行っていきます。
②原因箇所の調査
1.Typing Pipelineの処理が滞っている
まず、①で把握したお客様のキューの状況より、Indexing Queueでは詰まりが発生していませんでした。Typing Queue以前のキューが詰まり気味となっていることから、Typing Pipelineでの処理が滞っていると考えられます。
Typing Pipelineで行われている主な処理は、正規表現を用いたイベントの加工処理です。したがって、正規表現処理の中に、負荷の高い表現が含まれている可能性があります。
どの正規表現処理に負荷がかかっているかも、Splunkの内部ログであるmetrics.logを解析することで、確認することができます。
metrics.logには、ホスト、ソース、ソースタイプ、インデックス単位で、イベント分割処理や正規表現処理などのイベントの処理にかかったCPU使用時間が記録されています。
正規表現処理は、ホスト、ソース、ソースタイプ毎に設定が行われるため、どの正規表現CPU使用時間がかかっているかを調査することが可能です。
お客様のmetrics.logを解析した結果、あるソースタイプに対して設定していた正規表現処理について、CPU使用時間が長いことが分かりました。
2.取り込むデータの量が多い
①で把握したお客様のキューの状況より、キュー詰まりは慢性的には発生しておらず、データの取り込み量が多い時間帯に発生することが分かりました。
したがって、データの取り込み量が多くなる時間帯は、取り込み量に対して、インデクサーの処理能力が追い付いていない可能性があります。
③対処策の立案・提案
②にて調査した結果より、2つの対処策を考えました。1つ目は、インデクサーにかかる処理の負荷を低減させる、2つ目は、インデクサーの処理能力を向上させる対処策です。それぞれについて、以下にご説明します。
1.インデクサーにかかる処理の負荷を低減させる
- 正規表現処理の変更
調査結果より、処理に時間のかかる正規表現処理が行われていることが分かっています。
したがって、該当する正規表現を変更することで、事象が解消される可能性があります。 - データ取り込み量の低減あるいは平滑化
調査結果より、データ取り込み量が多い時にキュー詰まりが発生しています。また、お客様の環境では、データの取り込み量に時間によってムラがあることが分かっています。したがって、データの取り込み量を減らす、あるいは時間による取り込み量のムラをなくして平滑化することで、データの取り込み量が多くなることを防ぎ、事象が解消される可能性があります。 - ヘビーフォワーダーの導入
お客様の環境では、フォワーダーにユニバーサルフォワーダーを使用していました。ユニバーサルフォワーダーでは、データの解析処理が行われないため、パイプラインの一連の処理はすべてインデクサーで行われます。一方、ヘビーフォワーダーでは、データの解析処理が行われるため、ヘビーフォワーダーで取り込んだデータについては、インデクサーで解析処理を行う必要がありません。したがって、ヘビーフォワーダーを導入することで、インデクサーにかかる負荷を低減し、事象が解消される可能性があります。
2.インデクサーの処理能力を向上させる
- パイプラインの増設
インデクサーの処理能力を向上させることで、パイプライン処理が滞ることがなくなり、事象が解消される可能性があります。インデクサーでは、取り込み処理能力を向上させるために、パイプラインを増設することが可能です。デフォルトでは、パイプラインは1本であり、データ取り込み処理は1本のパイプラインで行われます。パイプラインを2本に増設することで、2本のパイプラインで並列してデータ取り込み処理を行うことが可能となり、処理能力が向上します。
パイプラインを増設する方法については、弊社サポートサイトのFAQ記事内にも掲載しているため、よろしければ併せて確認してみてください。 - インデクサーのパイプラインを増加することで取り込み処理速度を向上させる方法
https://support.mnc.macnica.co.jp/hc/ja/articles/11058470373529
※弊社保守ユーザ様のみアクセスが可能です。
上記の対処策について、お客様に提案を行います。
その際、お客様環境の具体的な要件等をお伺いしながら、実施可能な対処策を上記の中から検討します。
④対処策の実装
③の対処策についてお客様に提案をおこない、お客様にて運用面との兼ね合いなどでの検討をおこない、まずはパイプラインの増設を行い、様子を見ることとなりました。
そのため、パイプラインの増設手順までご案内し、無事お客様の環境で対処策が実装され、効果が確認できたところで、本サポートはクローズとなりました。
おわりに
最後までお読みいただきありがとうございます。
いかがでしたでしょうか。本記事がみなさまのご参考となれば幸いでございます。
本サポートでは、結果として、お客様から満足の評価をいただくことが出来ました。
その際、プレミアムサポートならではの、お客様の環境に寄り添った対処策の提案について特に価値を感じていただいていたようでした。
本記事をご覧いただき、弊社のプレミアムサポートにご興味を持っていただけますと幸いです。
お問い合わせ・資料請求
株式会社マクニカ Splunk 担当
- TEL:045-476-2010
- E-mail:splunk-sales@macnica.co.jp
平日 9:00~17:00




