Splunk
スプランク
Observability(オブザーバビリティ)とは何か?知っておきたい新しいIT運用の考え方

はじめに
システムのクラウド移行が進む昨今、「Observability(オブザーバビリティ)」という単語を耳にする機会が増えてきているのではないでしょうか。ObservabilityはObserve(観察する)とAbility(能力)を組み合わせた意味の単語で、分散型ITシステムのパフォーマンス向上の文脈でよく使用されるものです。日本語では「可観測性」と訳され、運用における新しい概念として注目されています。
本記事では、Observabilityについて従来のモニタリングとの違いを交えて解説します。
目次
Observability(オブザーバビリティ)とは
Observabilityとは、『どんなアーキテクチャで構成されるITシステム/サービスにおいても、いつでも状態を把握できるための仕組み』のことを指します。
クラウドやコンテナの活用が進むにつれてシステムが複雑になり、単一のログやメトリクスだけではシステム全体を把握することが困難になります。そこでObservabilityの概念に即して、システムの動作や内部状態を理解することで、システムの異常な挙動を特定し、デバッグや障害復旧など、迅速に対処することができます。また、Observabilityは、システムの設計や改善にも役立ち、システムのパフォーマンスやボトルネックを把握することで、改善のための施策を打つことができます。
オープンソースやクラウドネイティブ技術を活用するための推奨プロセスを描いた『Cloud Native Trail Map』※1では、Observabilityは10ステップのうち4番目に記載されています。特にDevOpsエンジニアやSRE、ITサービス担当者、またクラウド推進や開発基盤担当の方々にとって、クラウド推進におけるコンテナ活用や自動化等と並び、Observabilityは取り組むべき事項の一つと言えます。
※1 Cloud Native Trail Map, CNCF(Cloud Native Computing Foundation)
Observabilityが求められる背景
Observability技術が登場した背景には、新たなITサービス基盤として登場したクラウドネイティブ技術特有のマイクロサービスアーキテクチャの存在があります。
ITサービスの巨大化、高度化により、開発サイクルも更なる効率化が求められ、従来のモノリシックなアーキテクチャから、構成要素を柔軟に変更できるマイクロサービスアーキテクチャ(クラウド技術等)が利用され始めています。これらの技術を活用することで、基盤のリソースを気にすることなく開発に集中でき、開発サイクルの速度を各段に高めることができるため、 ITサービスを展開する企業を中心に技術の活用が進んでいます。
しかし、動的なマイクロサービスアーキテクチャでは、構成要素が非常に複雑かつ自動で変化することでアーキテクチャが論理的に抽象化さるため、従来の単一ログや、メトリクス監視ではシステムの状況を把握することは不可能です。
そこで、動的な環境においても監視を実現させるObservabilityの仕組みがクラウドネイティブ技術の中で非常に重要な技術の1つとして注目されているのです。
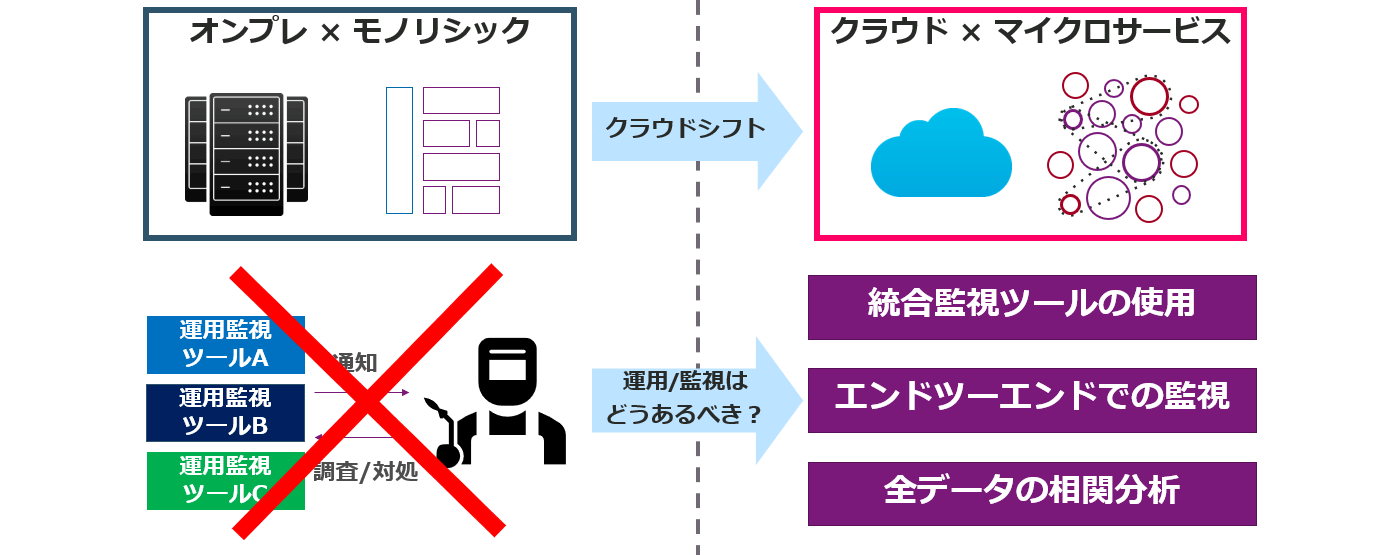
モニタリングとの違い
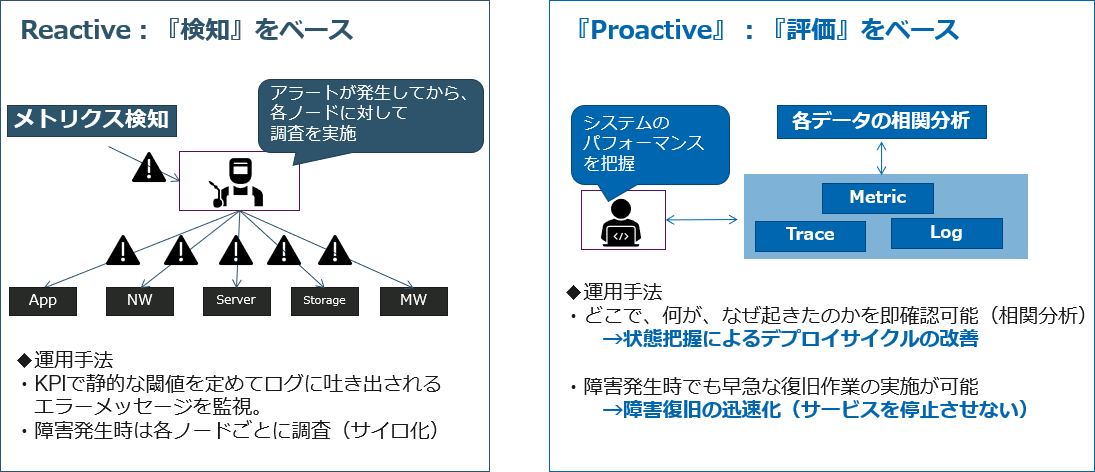
従来の「モニタリング」は、アラートをキックにシステムを調査するリアクティブな対応だとすると、Observabilityはシステムの健全性から内部の状況を把握するプロアクティブな対応となります。ただし、全てにおいてがObservability効果的というわけではなく、双方の違いや求められる背景を理解する必要があります。
ReactiveとProactiveの違いについて
Observabilityの仕組みを実現させるには?
この仕組みを実現させるためには、単一的なメトリクス監視ではなく、『メトリクス』『トレース』『ログ』の3つのデータを相関分析させることが基本的な考え方となります。
- メトリクス
メトリクスは、システムのパフォーマンスを測定するための数値データを提供するための手段です。メトリクスには、CPU使用率、メモリ使用量、ネットワークトラフィックなどが含まれます。メトリクスは、システムのパフォーマンスを定量的に把握することができます。 - トレース
トレースは、システム内の特定のトランザクションの経路や時間を追跡するために使用されます。トレースは、複数のシステム間でのトランザクションの流れを追跡することができ、システムの問題を特定するために重要な情報を提供します。トレースは、分散システムのデバッグや障害復旧に役立ちます。 - ログ
ログは、システム内で発生したイベントやエラーを記録するための手段です。ログは、システムの動作や内部状態を把握するために重要な情報を提供します。ログには、タイムスタンプ、ログの種類、詳細な情報などが含まれます。
これら3つのデータを用いて、ITシステム/サービスの状態を以下のように把握します。
- メトリクス(使用率やトラフィック等のシステムパフォーマンスの数値データ)
→数値データの閾値からイベントを検知 - トレース(トランザクションの経路や時間を追跡させるデータ)
→イベントの流れを追跡させることで問題の特定/対処 - ログ(イベントやエラーを記録したデータ)
→実際の履歴から根本原因の調査
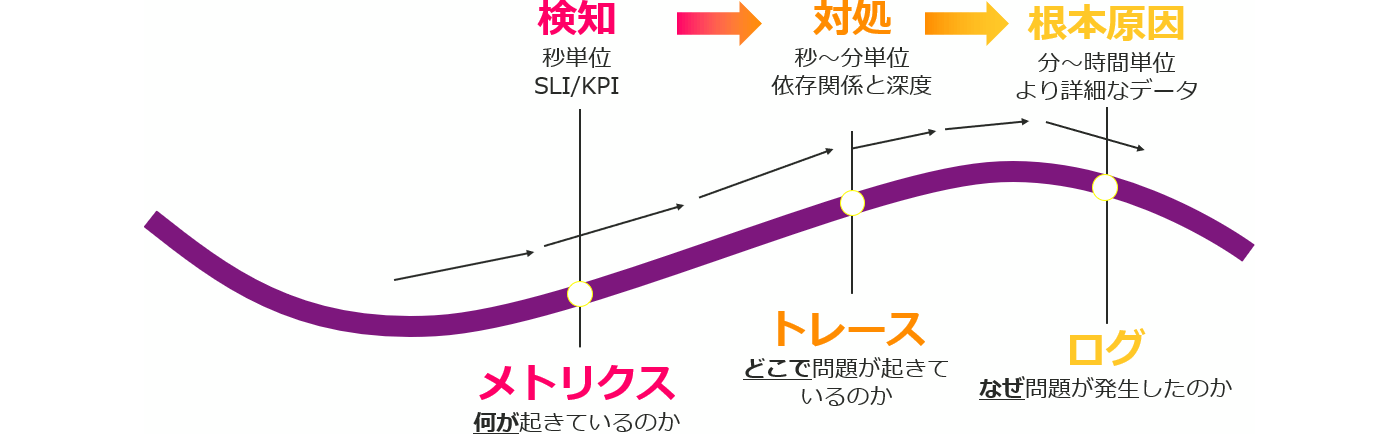
それぞれのポイントを相関分析させることで、どんなイベントが発生しても検知、対処、根本原因調査によって情報をくみ取り、安定したシステム運用につなげることが可能になります。
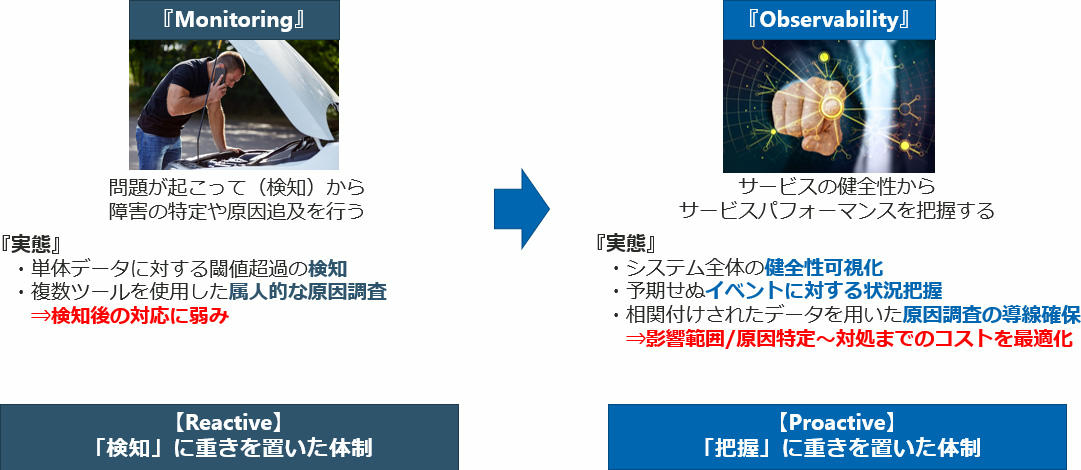
また、ITサービスを利用するユーザー目線では「利便性や快適性」が求められ、サービスレベルの要求度はますます高まっています。高いレベルでお客様に満足いただけるITサービスを維持し続けるためには、運用面でも単一ログの可視化や検知だけではなく、イベントの詳細把握やインシデントに対する迅速な対処が求められるため、Observabilityの確立は開発環境の高度化(クラウド推進)とサービスレベルの向上の双方を実現させるために必要不可欠であり当たり前になっていく仕組みであると言えます。
Observabilityの概要について理解したうえで、最適な運用方法をぜひ見つけていただければと思います。
株式会社マクニカ ネットワークス カンパニー
Sales&Marketing
安藤 諒
2021年より IT Operation/Cloud Solutionに関する分野を専門に、お客様のプロジェクト支援、マーケティング活動、DXに伴うシステムの運用効率化/高度化に関する啓蒙活動に従事。
お問い合わせ・資料請求
株式会社マクニカ Splunk 担当
- TEL:045-476-2010
- E-mail:splunk-sales@macnica.co.jp
平日 9:00~17:00




