
・ビジネスプロセスのデジタル化に興味がある方
・効率の良いプロセスの自動化を検討されている方
・バックエンド業務の工数を削減したい方
この記事を読み終えるのに必要な時間
5分
はじめに
DXという言葉がメディアでも多く取り上げられるようになり、日本の企業でも効率向上や業務のデジタル化の推進が進んでいます。
業務の自動化という点では、RPAやDPA、BPAという手法が検討されています。こうしたプロセスオートメーション分野では、日々研究が行われており、さまざまな事例が海外を含め多く取り入れられています。
そこで、今回はバックエンド業務の自動化にフォーカスし、特に「ビジネスプロセス」の改善に関する研究事例および活用事例を3つご紹介します。
バックエンド業務とは
バックエンド業務は「バックエンド」という言葉が後ろや隠れた後方を表すように、顧客がほとんど接触することのない舞台の裏で行われるオペレーション作業を指します。バックエンドの業務としては会計処理や組織内部のデータ処理、文書管理や処理、組織内部の作業最適化などがあげられ、企業でよく行われるビジネスに必要な業務です。
プロセス・マイニング
DXが推進されるようになり、業務プロセスの自動化または効率化に取り組む企業が増えました。それに伴い、業務効率の最適化がより容易になるさまざまな手法やツール、サービスが多く誕生しています。
「プロセス・マイニング」は業務の各工程から得られるデータを使い業務工程を可視化し、どのように改善できるか分析するバックエンド業務のひとつです。プロセス・マイニングを実施することで、業務のボトルネックや非効率な処理または作業を洗い出すことができ、作業工程の改善にとどまらず、結果的に企業のDX推進やKPI改善に繋がります。
また、プロセス・マイニングが注目され広まった理由として、組織のデジタル・ツイン(DTO: Digital Twin of an Organization)に対する興味関心の向上も挙げられます。プロセスの可視化が可能なプロセス・マイニングは、より柔軟かつ動的でレスポンシビリティの高いプロセスを作り出す組織のデジタル・ツイン実現の重要な要素となっています。
出典:Data-Enhanced Process Models in Process Mining
キャプション:Fig. 1. Main process mining steps [5]
https://arxiv.org/pdf/2107.00565.pdf
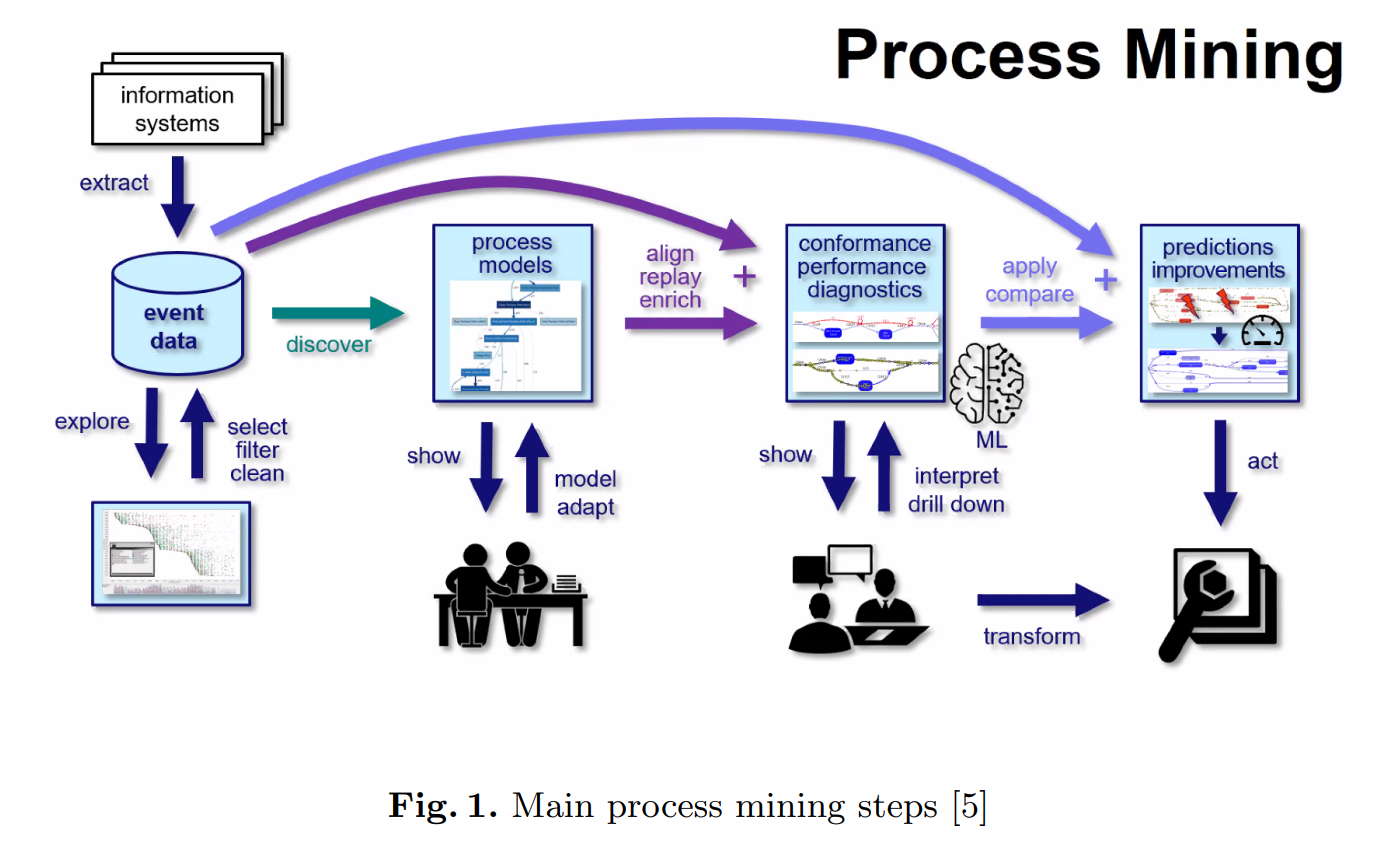
データから情報を取り出すマイニング処理は、プログラミングで独自に目的に合わせて作成されることが多いですが、プロセス・マイニングは機械学習でよく使用されるプログラミング言語「Python」で使用可能なライブラリとしてもリリースされています。
『PM4PY』はそのプロセス・マイニングに特化したライブラリの一つです。
このライブラリを使用することで、独自にそして一からプログラムを作成することなく、よりかんたんにプロセス・マイニングのプログラムを作成することが可能です。このようなライブラリが登場してからは、世界的にプロセス・マイニングの需要と人気が向上しています。
プロセス・マイニングは欧州では2010年代から急速に大手企業に広まっていますが、日本ではまだプロセス・マイニングの認知が低く、専門人材も少ないのが現状です。
しかし世界的な注目に合わせ日本でも認知度の向上や実践ノウハウの共有、専門人材の育成などを目的とした協会が設立されたりと、徐々にプロセス・マイニング普及の活動が進んでいます。
ビジネスプロセスのテキストデータを用いた予測監視
プロセス・マイニングはビジネスに関する知識・情報が蓄積された文書(テキストファイル)が活用されます。
例えば、業務を総合的に管理するERP(Enterprise Resource Planning)から得られるイベントログや、物流を統合的に管理するSCM(Supply Chain Management)から得られる物流データなど、多くの業務を記すデータがプロセス・マイニングの対象となります。
データ取得元のシステムによってフォーマットは異なるものの、多くのデータは取引ID・業務ID・タイムスタンプ・処理結果などを含む表として表すことができるテキストデータや、時系列で製造量や取引量などを示す数値をメインとするテキストデータであることが多いです。
そのため、これまでのプロセス・マイニングの手法は上述したような構造化された数値データやカテゴリデータを得意としており、電子メールや文書のような自然言語で作成されたデータが重要な情報を持っている場合に正確な予測を行うことに限界がありました。
つまり作業の各工程を数値や表(テーブルデータ)といった形のイベントログとして残している場合にはプロセス・マイニングが行えましたが、特にそういったログを残しておらず、文章でドキュメント化していた場合にはそのデータを活用することが難しい状況でした。
このような限界を克服するために、プロセス・マイニングの世界で権威のあるドイツのアーヘン工科大学PADS(Process and Data Science)研究グループの『Text-Aware Predictive Monitoring of Business Processes』という論文では、自然言語モデルと時系列データを扱える再帰型のモデルを組み合わせた新しい手法が提案されました。これまで自然言語処理とプロセス・マイニングの分野が交差された手法はめずらしく、かつ有用性が示されています。
実際に、実世界のプロセスデータ(イベントログなど)を使いこの手法を評価したところ、扱えるデータの幅が広がったことで、最先端のプロセス・マイニング手法よりも優れたパフォーマンスを示すことができたそうです。この手法を用いることで、特に日本ではまだプロセス・マイニングが一般化しておらず、企業でも業務のデータを適切な形で十分に取得できていない現状もあるかと思います。そういったケースで、この自然言語もプロセス・マイニングに活用できる手法の活用ができるのではないかと考えます。
出典:Text-Aware Predictive Monitoring of Business Processes
キャプション:Fig. 2: Overview of the text-aware process prediction model.
https://arxiv.org/pdf/2104.09962.pdf
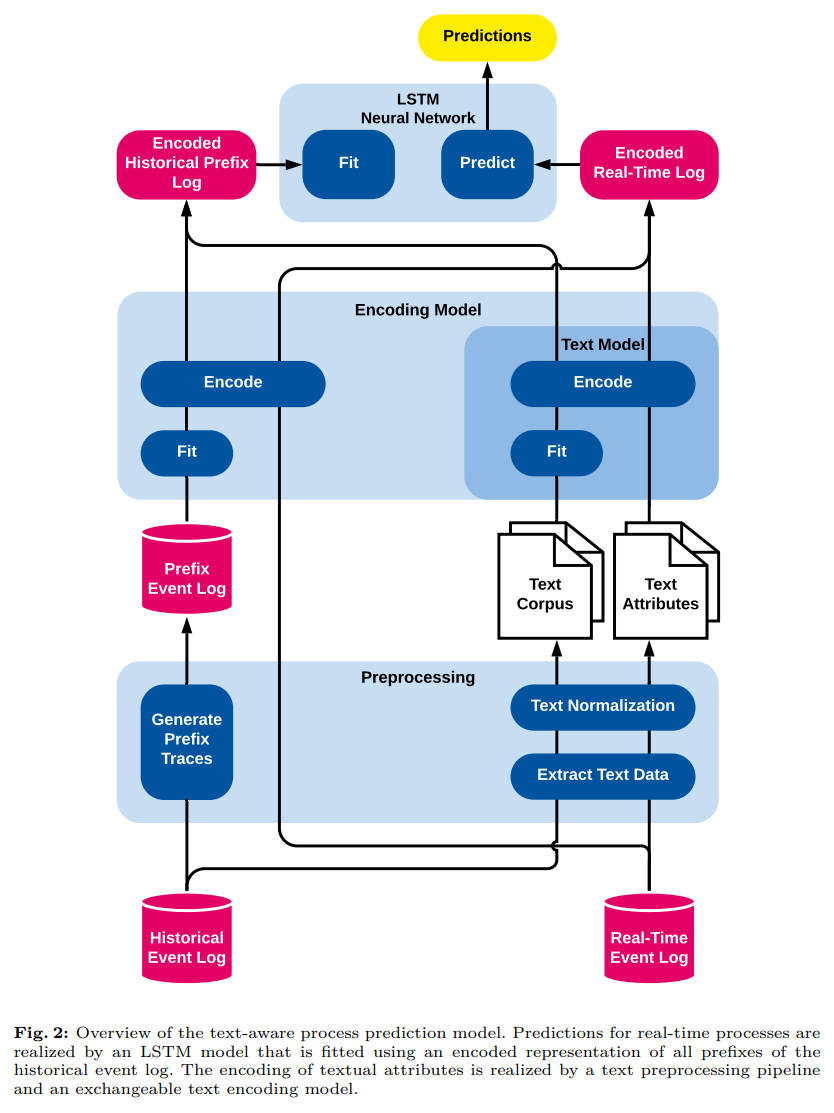
ビジネスプロセスの最適化
ビジネスプロセス管理(BPM:Business Process Management)という言葉は昨今よく耳にするようになり、BPMの一つの側面を担うプロセス・マイニングよりも一般的になっているかもしれません。
BPMとは、業務の現在の状況を把握、監視、実行、さらに改善を行うPDCAサイクルをまわすことで、企業戦略に基づく理想の業務プロセスへ近づけていくためのバックエンド業務です。
リモートワークが広まった今、働き方改革の中心的な要素となってきています。また、時代の進化にともなって、システム導入や作業の自動化によるアプリケーション利用が増え、人手外のイベントの量が増加し、BPMの対象となり得るデータも増加しています。このようなデータを活用することでBPMが容易になる一方、業務要件の変化や予測不可能な環境の要因がBPMに影響を及ぼすようにもなりました。
そこでBPMにもAIが活用されるようになり、AIの予測精度の向上からますますBPMの価値が高まり、BPM業界の需要は、2023年までに160億ドルに近づくと予想されています。これはより企業戦略を確実に実行するための最適な業務プロセスを導き出したいという需要がうかがえ、企業を支えるバックエンド業務として多くの企業でBPMが行われるようになる可能性があります。
深層強化学習を活用したAIによるリソース配分
組織の戦略的目標をサポートするために必要なリソース(資産)を割り当てて管理することは、重要なバックエンド業務のひとつです。企業は有形・無形資産を含む限られたリソースを最大限に活用し利益を最大化する必要があります。そのためリソースの分配作業はBPMの観点からも重要なプロセスといえます。BPMの注目や人気にともない、リソース分配の自動化や効率化がここ10年間でより注目されるようになり、その注目度は発表された科学論文の数にも反映されています。
AIの専門学部を持ちポーランドのAI研究の中核を担うワルシャワ工科大学より発表された『Deep Reinforcement Learning for Resource Allocation in Business Processes』では、ビジネスプロセスにおけるリソース配分を目的として、深層強化学習を二重に適用した手法を提案しています。
リソースの配分を目的とした自動化では、これまでルールベースのアルゴリズムやLSTMといった時系列に対応したAIモデル、そして近年は価値を最大化するような行動を学習できる強化学習モデルが活用されてきました。
深層強化学習はディープラーニングを活用し、価値を最大化するような意思決定を行うことが可能なモデルです。
そのため、リソース配分を行いたい特定のビジネスプロセスに関するタスクの一覧など、データを深層強化学習に使用することでその各タスクに対し、ビジネスプロセスの複数の適格性を考慮しながらリソースを割り当てるポリシーを作成することが可能となります。
この論文の手法の新規性は深層強化学習のネットワークを二重で適用したところにあり、これまでの手法と比較しても大幅な精度向上が可能となりました。
出典:Deep Reinforcement Learning for Resource Allocation in Business Processes
キャプション:Fig. 1: Training architecture diagram.
https://arxiv.org/pdf/2104.00541.pdf
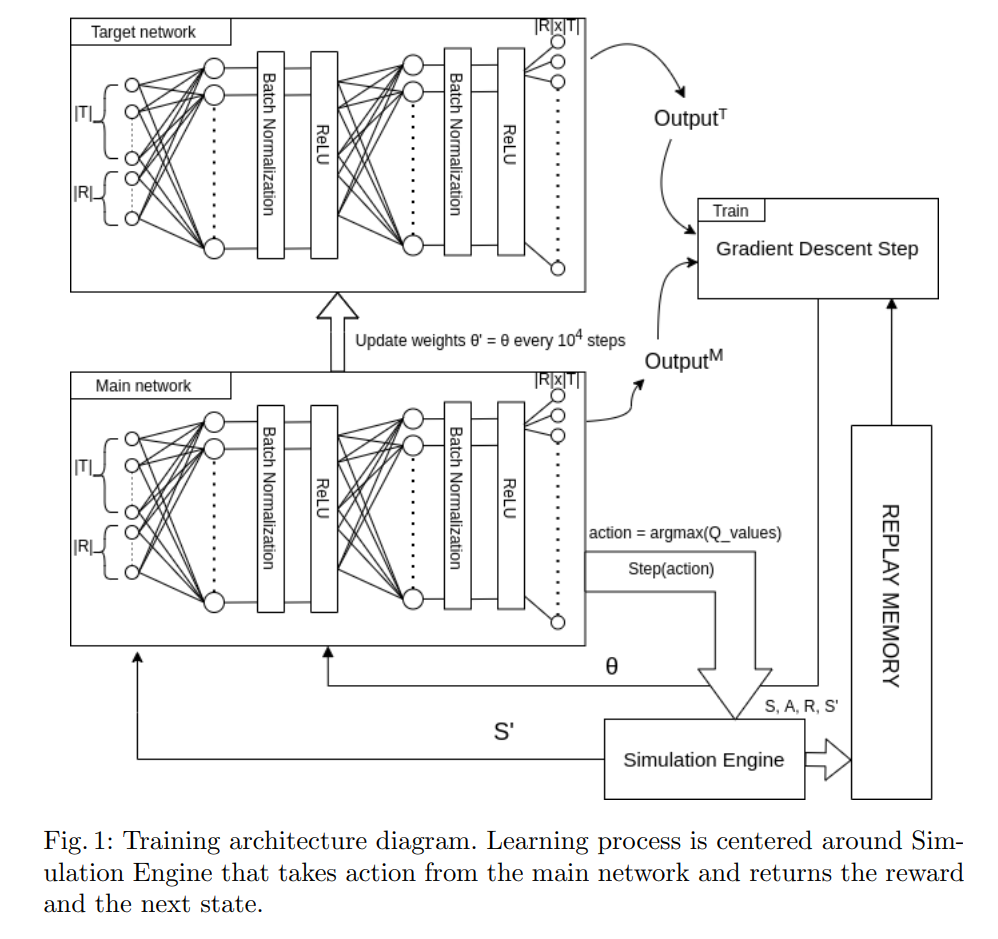
ビジネスプロセスの自動化
自動化のための会話型アシスタントフレームワーク
ビジネスプロセスの自動化(BPA)は数十億ドル規模の急成長を遂げている業界です。おかれた環境に合わせた行動選択が可能なシステムを自律型エージェントと呼びますが、この自律型エージェントの導入により、労働者が危険なタスクをすることを回避でき、より労働者の時間と頭脳の力を創造的で魅力的なタスクに使用することが可能となります。
ただし、このような自律型エージェントの展開を成功させるためには、ユーザーが自律型エージェントのパフォーマンスを監視し、実行を独自カスタマイズできることが不可欠となります。
IBMのAIの研究所が発表した『A Unified Conversational Assistant Framework for Business Process Automation』では、自律型エージェントに構成できるスキルの種類と、これらの自律型エージェントをどのように自動化するかを議論し、さらに自然言語によるデータ検索、ビジネスプロセスにおけるタスクの自律的な実行、アラート通知など、複数の機能をサポートする会話型アシスタントを開発するためのマルチエージェントフレームワークを紹介しています。自律型エージェントの普及が進むことで自動化できない、人の創造性や頭脳が必要なタスクにフォーカスできるようになるため、バックエンド業務でも、よりビジネスプロセスの最適化に繋がります。
BPAのための会話アシスタントのフレームワークは、図に示すように、スキル、エージェント、オーケストレーターの3つの主要コンポーネントで構成されています。
出典:A Unified Conversational Assistant Framework for Business Process Automation
キャプション:Figure 1:Multi-agent Orchestration Overview
https://arxiv.org/pdf/2001.03543.pdf
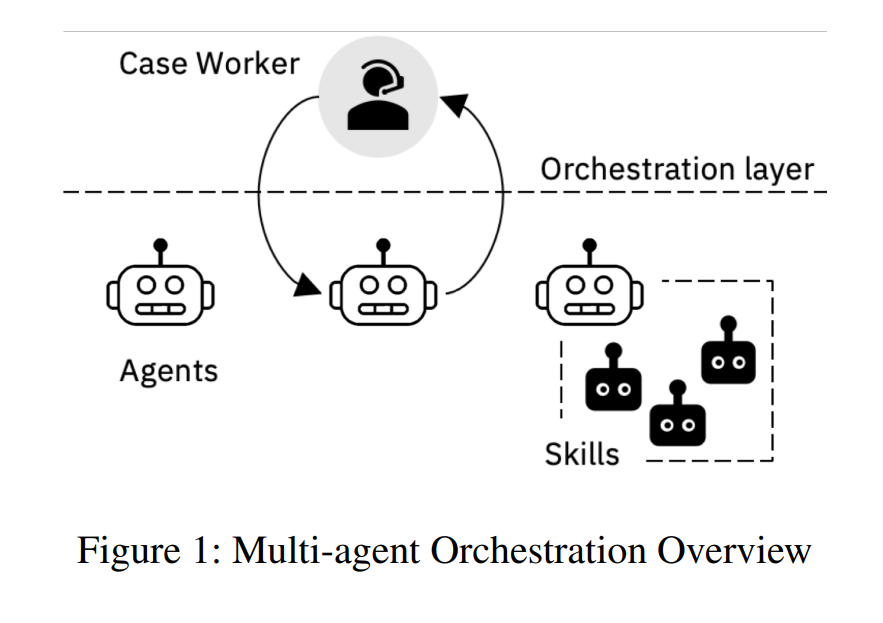
スキル(Skills)は、定義されたタスクを実行するもので、自律型エージェント(Agents)は、理解スキル、行動スキル、応答スキルの3つの主要なカテゴリに分類されるスキルで構成されたものです。
オーケストレーター(Orchestrator)は、自律型エージェント間の調整を行い、ユーザーにうまく応答するために、どの自律型エージェントが実行されなければならないかを決定します。
自律型エージェントがユーザーに応答する能力は、オーケストレーターの内部で回答のスコアを保持することで、より精度が高くパフォーマンスが高い自律行動を返却することが可能です。
スコアは「どれだけ自信があるか」を示しており、このスコアを元にオーケストレーターは1つまたは複数のエージェントを選択し、その応答を実行し、ユーザーに返します。
この提案を行ったIBMの『A Unified Conversational Assistant Framework for Business Process Automation』では、このようなフレームワークをベースに、出張旅費の事前申請・承認プロセスをSlack内で簡略化するアシスタントの実装例などが紹介されています。
この出張事前申請・承認についてはチャットボットを組み込んだビジネスプロセス管理ソフトウェアとして活用しています。申請者や承認者を判断し、それぞれに対応した申請・承認フェーズのうち今はどのプロセスかも判断し、申請・承認業務がシンプルになるようなサポートを実施しています。
まとめ
今回はバックエンド業務の自動化、特に「ビジネスプロセス」の改善に関する研究事例および活用事例を3つご紹介しました。
バックエンド業務はビジネスをおこなっていく際に絶対に必要となる業務ですが、多くの部分で自動化が可能な業務領域です。すべてを人間の代わりとなるのは難しいかもしれませんが、人間の知識や創造性をよりビジネスの根幹に活用することができるためのサポートが、このような研究をベースに進んでいることが伺えました。
今後はWeb3.0の加速や、メタバースの進化により、さらにビジネスプロセスの改善技術も進化すると考えられます。バックエンド業務がスマートになることで、ビジネスフローもスマートになっていき、より良い社会づくりに近づいていくことが望まれます。
|
■ 本ページでご紹介した内容・論文の出典元/References Marco Pegoraro, Merih Seran Uysal,David Benedikt Georgi, and Wil M.P. van der Aalst,Process and Data Science chair, RWTH Aachen University, Aachen, Germany,“Text-Aware Predictive Monitoring of Business Processes”,Fig. 2. : Overview of the text-aware process prediction model.,
Yara Rizk, Abhishek Bhandwalder, Scott Boag, Tathagata Chakraborti, Vatche Isahagian, Yasaman Khazaeni, Falk Pollock, Merve Unuvar, IBM Research AI ,“A Unified Conversational Assistant Framework for Business Process Automation ”,Figure 1: Multi-agent Orchestration Overview, |
関連記事

*テックブログAI女子部*
【教育×AI】教育に関わるさまざまな課題をAIで解決した例3選
*テックブログAI女子部*
【交通業界×AI】監視負荷の軽減!さまざまな自動監視AI事例

*テックブログAI女子部*
視線データ×AI活用!アイトラッキングが起こした3つの社会変化