- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration

Issues with using generative AI
Unable to provide answers specific to your company’s business
The learning data for LLMs (Large Scale Language Models) is mainly created from public documents on the Internet. For this reason, while general-purpose LLMs have general knowledge, they lack specialized knowledge specific to specific companies or domains, making it difficult to understand vocabulary and context specific to industries or individual companies. To solve this, it is necessary to build custom models or use a mechanism called RAG (Retrieval-Augmented Generation) to supplement the knowledge that the base model does not have.
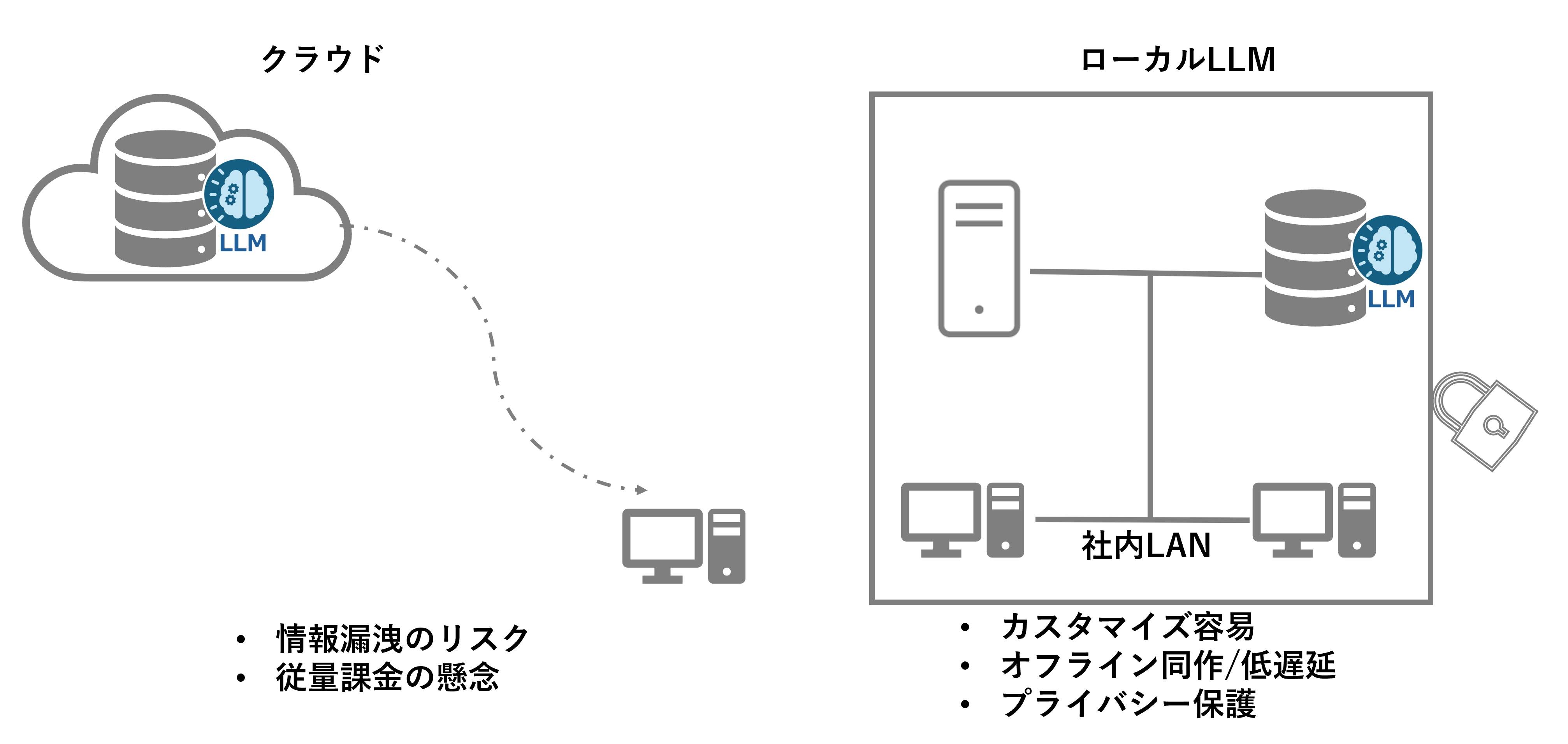
I don't want to put confidential information on the cloud.
In a cloud environment, data is stored on an external server, so there is a risk of confidential information such as in-house know-how and customer information being leaked. In addition, although the security measures provided by cloud service providers (CSPs) are generally high, the ultimate responsibility for data management lies with the company, so caution is required, especially for highly confidential information. For these reasons, many companies tend to avoid uploading confidential information to the cloud and choose to process it in an on-premise environment.
What is a Local LLM?
A local LLM (Local Large Language Model) refers to a large-scale language model that a company or organization builds and operates in its own on-premises environment.
If you would like to learn more about local LLMs, please see this article.
Benefits of a Local LLM
1. Security and Privacy
Local LLM processes data in-house, eliminating the need to transmit confidential or personal information externally and reducing the risk of data leakage.
2. Customizability
You can freely customize the model to fit your company's specific business needs, allowing it to learn industry-specific knowledge and terminology.
3. Performance
The lack of network latency enables real-time inference and the ability to process large amounts of data quickly.
4. Cost Management
Although the initial investment may be high, in the long run it is easier to estimate costs and allows for more stable operation than pay-as-you-go cloud services.
As such, Local LLMs are a very useful option, especially for companies that place a premium on security and customizability.
Hurdles to introducing local LLM
Building a GPU environment (infrastructure)
To operate local LLM effectively, a high-performance GPU environment is required. There are several barriers to building such a system.

Choosing the best hardware
In order to select the optimal GPU resources for what you want to achieve, you need knowledge of generative AI models and an environment to actually try them out in. Also, since GPU infrastructure is expensive, if you cannot select the optimal hardware, it may end up being a waste of investment.

Infrastructure environment construction and maintenance
Building an infrastructure environment requires specialized knowledge of servers, networks, and the software implemented on them. Even after the GPU environment is built, personnel who can handle hardware maintenance, upgrades, and troubleshooting are required. This can lead to increased operational costs and human resources.

Scalability Constraints
Compared to cloud environments, it can be difficult to expand resources in on-premise GPU environments. The inability to flexibly scale up and down in response to fluctuations in demand can be a barrier to adoption.
Building a local LLM (software)
There are also several challenges in building software to utilize local LLMs.

Technical Expertise
Building a local LLM requires a deep understanding of machine learning and natural language processing. In addition, it is necessary to make full use of advanced technologies such as model fine-tuning, Retrieval-Augmented Generation (RAG), and AI agents, so it is important to secure personnel with specialized skills.

Development Time
Customizations and integrations to meet your needs can require lengthy development times, making rapid deployment difficult, especially if they require an iterative trial and error process.

Choosing the right tools
There are many tools and libraries required to implement a local LLM, so it is important to choose the tool that best suits your company's purposes.
As described above, the introduction of local LLM involves cost and technical challenges in both infrastructure and software construction, and companies need to carefully consider the matter.
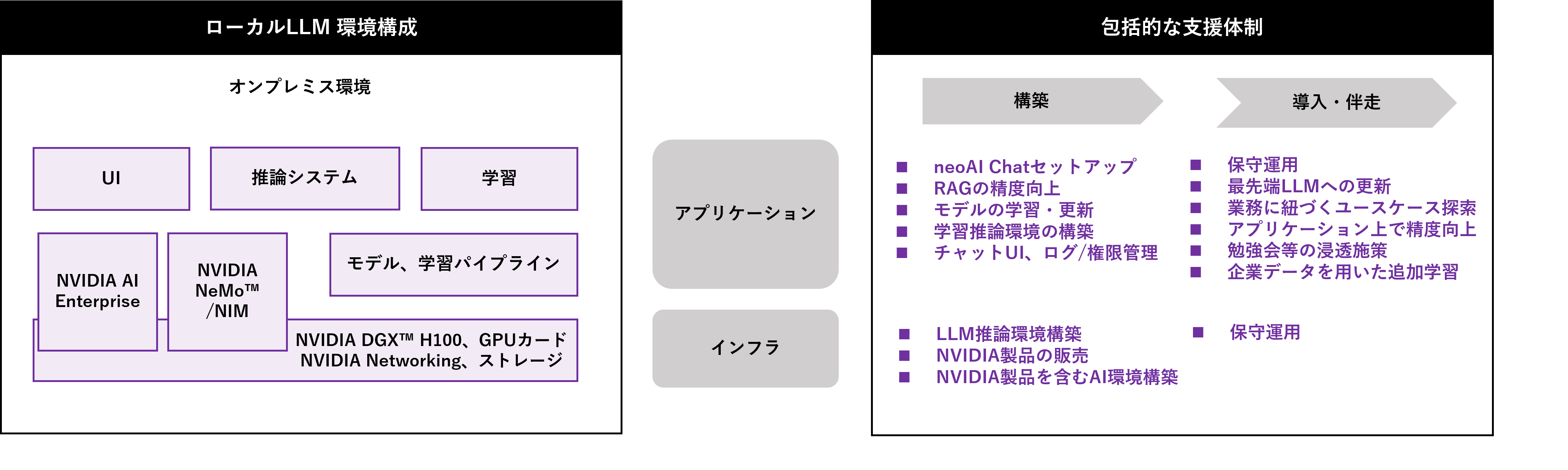
Local LLM Construction Support Service Contents
When utilizing local LLM, there are cases where you want to accumulate development know-how in-house and cases where you want to introduce application packages.
Macnica is a domestic distributor of NVIDIA products, with expertise in building AI infrastructure and a wealth of experience and know-how in using generative AI. We have established a comprehensive support system to handle both, and will provide end-to-end support for companies using generative AI, from construction to implementation and accompanying support.
When building a local LLM infrastructure, we can support you with everything from proposing and introducing the optimal hardware to suit your challenges and costs, to building the environment and maintaining it.
We also offer tools for managing and operating infrastructure, allowing us to provide an environment that can be maintained by infrastructure administrators without any special knowledge, that allows efficient use of GPUs, and that can be used by a greater number of users.
To build RAGs and AI agents, we will use various tools such as NVIDIA NeMo™, software that accelerates generative AI development, NVIDIA NIM™, software that accelerates deployment, and NVIDIA AI Enterprise, an enterprise AI platform that provides paid software support and is essential when using NVIDIA NIM, to build a local LLM on the NVIDIA AI infrastructure solution.
Even after implementation, we will provide ongoing, detailed support, such as improving accuracy and expanding functions in response to each company's unique challenges. Through this solution, we will accelerate the digital transformation of Japanese companies and strongly promote the practical application of generative AI and improved corporate competitiveness.
We provide hardware and software in one stop to meet your needs.
menu
・ Automated RAG accuracy evaluation
A service that accompanies the automation of RAG accuracy evaluation within one month
・AI agent construction support
A service that accompanies you over a two-month period, from the basics of AI agents to implementation tailored to your use case.
Learn about the benefits of building a local LLM in our webinar!

Related product page





Click here for inquiries

