- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2183件がヒットしています。check

Contents of this time
Advances in generative AI are accelerating the efficiency of corporate operations and the sophistication of services. One area that is attracting attention is the construction of "local LLMs (large-scale language models)." This three-part series is aimed at novice engineers and provides a systematic explanation of local LLMs, from the basics to use cases, providing the knowledge needed to take the first step in building one.
In this first article, we will introduce the basics of local LLMs and a complete guide to how to utilize them.
[Introduction to Local LLM]
Part 1: A complete guide to the basics and application of local LLMs
Why a Local LLM Now?
There are three main reasons why local LLMs are in demand.
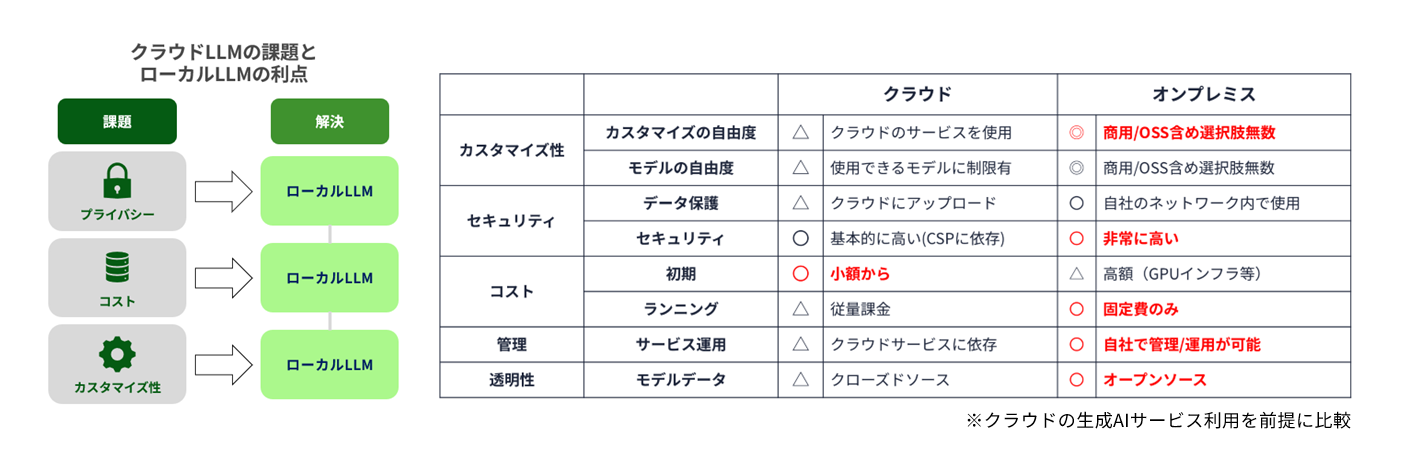
The first is ensuring privacy. Cloud-based LLM requires the transmission of confidential and personal information from within the company to external parties, which carries the risk of information leaks. In particular, in industries such as finance, medicine, and manufacturing, much of the data cannot be uploaded to the cloud, and local processing is essential.
The second is cost optimization. Cloud LLM generally operates on a pay-as-you-go basis, and costs rise proportionally as usage increases. Local LLM requires an initial investment, but it can reduce costs in the long term.
The third advantage is customizability. While it can be difficult to fine-tune the model's behavior in cloud LLM, in a local environment, you can use open weight models to perform your own fine-tuning and RAG (Search Augmentation Generation).
However, building a local LLM requires a high-performance GPU and specialized knowledge, and there are limits to what can be achieved with OSS alone. Therefore, NVIDIA 's hardware and Macnica 's technical support will play an important role in realizing a practical and stable local LLM.
LLM Basics: What you need to know before building a local
LLMs (large-scale language models) are AI models that learn from large amounts of text data and generate natural, human-like sentences. Representative examples include ChatGPT, Llama, Mistral, DeepSeek, and Claude, and are used for a variety of purposes, including question answering, summarization, translation, and code generation.

There are two types of LLM: cloud-based and local-based, each with its own advantages and challenges. Cloud-based LLMs are easy to implement and scalable, but have limitations in terms of privacy, cost, and customizability. Local-based LLMs, on the other hand, offer greater flexibility and security, but require specialized knowledge and high-performance hardware to build and operate.
Additionally, there is an LLM called an Open Weightmodel. This is an LLM in which the neural network weight data is publicly available, allowing for retraining and fine-tuning. Representative open weight LLMs include Meta 's Llama, Google 's Gemma, and Mistral AI 's Mistral, and are generally made public on Hugging Face Hub. On the other hand, OpenAI 's commercially available model is a closed model (as of August 2025), and fine-tuning is only possible through OpenAI 's tools, with the details of the processing not being made public.
It's also important to understand basic terminology. A "token" is the unit of string that the model processes, and "model size" refers to the number of parameters used in training. For example, Llama 8B has 8 billion parameters, 70B has 70 billion parameters, and 405B has 405 billion parameters. The larger the size, the higher the accuracy, but the more GPU memory is required.
From a technical perspective, providing LLM as a service requires an "inference server." This is a system that responds to user input in real time, and GPU performance is directly linked to response speed. The larger the model size, the more VRAM is required. For example, Llama 3.1-8B requires approximately 16GB of VRAM, 70B requires approximately 141GB, and 405B requires as much as 812GB of VRAM, making multiple GPUs and distributed processing essential.
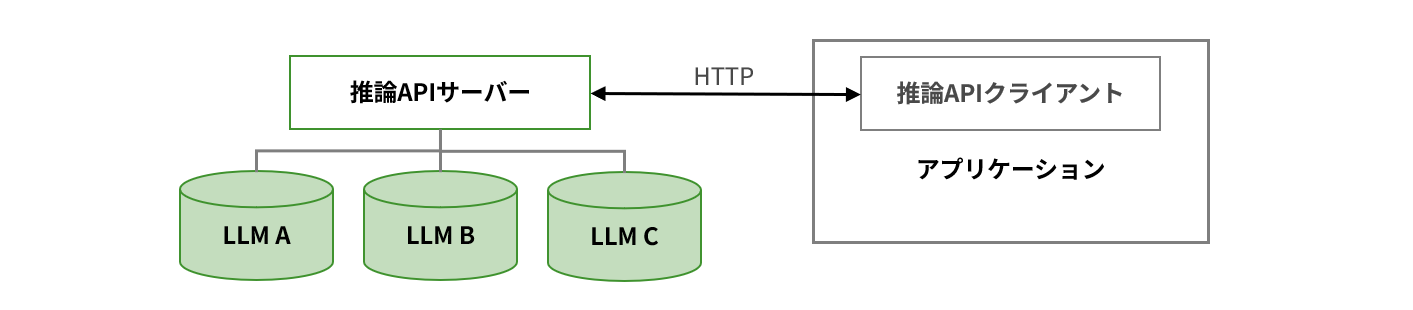
*Communication format generally conforms to the OpenAI Chat Completions API.
*The performance of the inference server affects the request-to-response delay and request throughput.
See the table below for an example of GPU requirements by model.
| scale | model | Number of parameters | Precision | Amount of memory required |
| Small | meta-llama/Llama-3.1-8B-Instruct | 8.03Billion(8.03 billion) | BF16 | 16.06GB(8.03x2) |
| During ~ | meta-llama/Llama-3.1-70B-Instruct | 70.6 Billion (70.6 billion) | BF16 | 141.2GB(70.6x2) |
| Big | meta-llama/Llama-3.1-405B-Instruct | 406 Billion (406 billion) | BF16 | 812GB(406 x2) |
*Other working memory is also required in VRAM.
*For medium-sized LLMs, they will need to be loaded across multiple GPU cards.
*This is a prerequisite for building an inference server using RAG, etc. A high-performance GPU environment is required for learning.
Understanding these technical requirements clarifies the difficulty of building a local LLM and the support required. Macnica provides technical support to overcome these challenges.
Local LLM use cases: Examples of practical use in the field
Local LLM can be used to support a variety of business operations at companies. Here, we will introduce actual use cases to give you a concrete idea of the possibilities of Local LLM.
First, there's the internal chatbot. By utilizing LLM, which has learned company regulations, work manuals, FAQs, etc., it's possible to build an AI assistant that can immediately respond to inquiries from employees. This reduces the burden on the general affairs, human resources, and IT departments and improves work efficiency.
Next is document search and summarization. By searching and summarizing the vast amount of documents, minutes, and technical documents stored within a company in natural language, information utilization can be dramatically improved. In particular, by utilizing RAG (Search Augmentation and Generation), accurate answers can be generated based on specific documents.
LLM is also effective for code completion and review support. By suggesting the next step in code written by engineers and pointing out potential bugs, it is expected to improve development speed and quality. Building a model that is specialized for your company's coding standards will enable even more practical support.
Local LLM is also useful for security and compliance purposes, strengthening risk management by automatically detecting confidential and personal information in internal documents and pointing out expressions that pose a risk of violating laws and regulations.
To realize these use cases, specialized knowledge and experience are required in areas such as model selection, GPU configuration, and inference environment design. Macnica offers everything from optimal configuration proposals using NVIDIA GPUs to installation and operation support. If you are considering implementing local LLM, please feel free to contact us.
Next time, we will explain the overall system required to build a local LLM!
In this article, we have introduced the basics of local LLMs and a complete guide to how to utilize them.
Next time, we will look at the overall system required to build a local LLM,We will provide a detailed explanation of the support information provided by Macnica from a practical perspective.
For quotes/inquiries click here

