- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2191件がヒットしています。check

Introduction
Currently, many organizations are moving from the proof-of-concept test stage to the actual use stage of systems that apply generative AI. This requires connection to existing enterprise systems, and it is extremely important that the system be easy to develop and flexible enough to accommodate system expansion.
It is generally said that systems with loose coupling and high cohesion are easy to understand and maintain. Cohesion is the degree to which things with the same role are gathered in the same place. Microservices have recently been attracting attention as a software implementation method that achieves loose coupling and high cohesion.
In this first article, we will explain the development of a Microservices based RAG system using NVIDIA NIM.
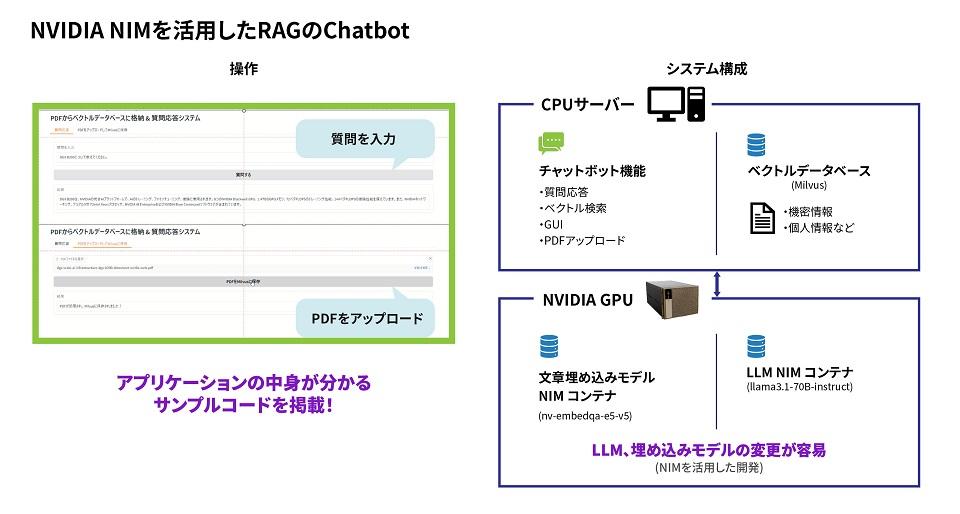
[RAG Chatbot Development Using NVIDIA NIM]
Episode 1: RAG system development using Microservices
Episode 2: What is the required software/hardware configuration for a RAG system?
Episode 3: RAG System Sample Code
What are Microservices
Microservices are small, independent pieces of Microservices that communicate with each other through APIs.
As you may already know, API stands for Application Programming Interface, and in the broad sense it is a specification for software components to exchange information with each other. The API used in Microservices has a more specific meaning and is defined on a communication protocol such as HTTP.
What is NVIDIA NIM?
The NVIDIA NIM introduced in this article is a collection of carefully crafted Microservices that make it easy to deploy generative AI models on-premise or in the cloud.
Each Microservices is provided as a container image, along with a Helm chart to automate their deployment. Microservices provided by NIM have a wide range of functions, but the RAG system introduced in this article uses Microservices for large-scale language models (LLMs) and text embedding models. These models use industry-standard APIs, so it is easy to migrate the LLM portion of existing systems that use OpenAI's ChatGPT as an LLM to NVIDIA NIM.
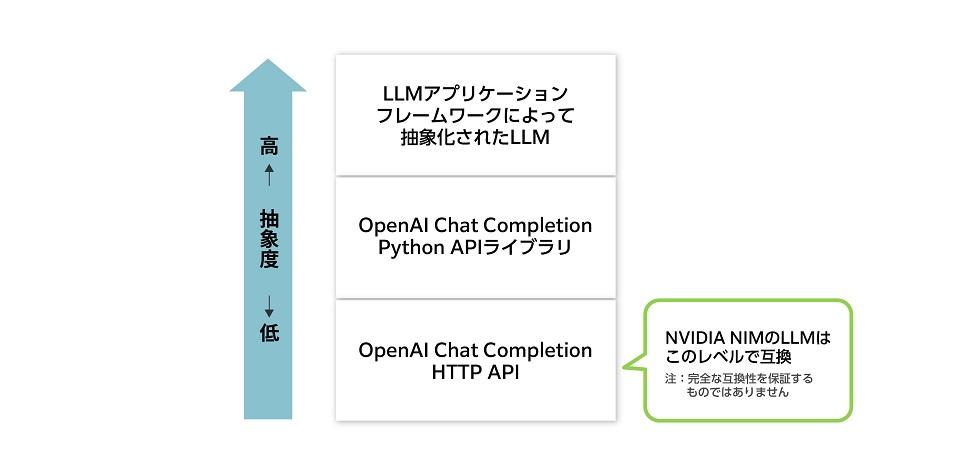
For example, a system that uses the Chat Completion API through the OpenAI Python API library can become compatible with NVIDIA NIM with just three lines of code changes:
import openai client = openai.OpenAI( base_url = "YOUR_LOCAL_ENDPOINT_URL", #<=たった3行の変更でNVIDIA NIMへ対応 api_key="YOUR_LOCAL_API_KEY" #<=たった3行の変更でNVIDIA NIMへ対応 ) chat_completion = client.chat.completions.create( model="model_name", #<=たった3行の変更でNVIDIA NIMへ対応 messages=[{"role" : "user" , "content" : "Write me a love song" }], temperature=0.7 )NVIDIA NIM also supports LLM application frameworks such as LangChain and LlamaIndex because NVIDIA NIM is compatible with the industry-standard OpenAI Chat Completion API at the HTTP API level, as shown in the figure below.
What is RAG?
This article will cover how to implement an LLM system using RAG using Microservices provided by NVIDIA NIM, but first let’s look at what RAG is.
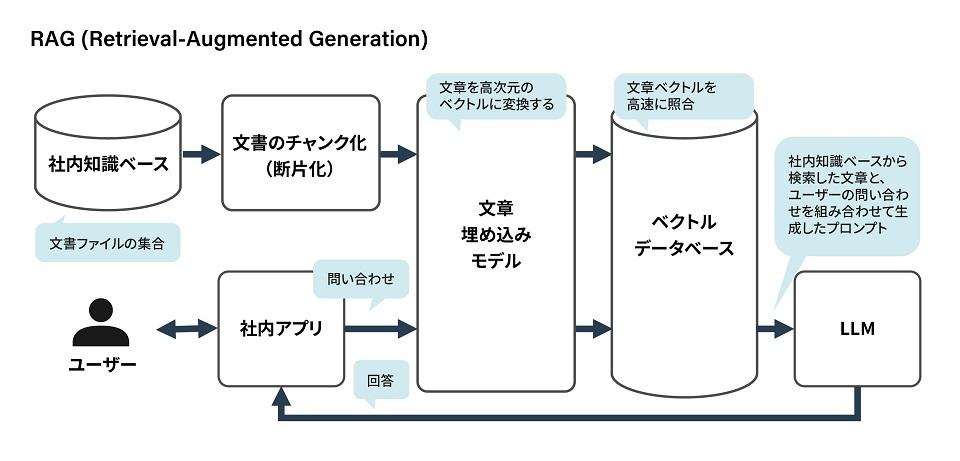
Naturally, an LLM does not have knowledge based on information newer than the information used to learn it. For example, an LLM that completed learning in December 2023 would know nothing about fashion trends in 2024. It may also generate inaccurate answers, a phenomenon known as hallucination. One of the techniques to counter inaccuracies is RAG (Retrieval-Augmented Generation).
In RAG, the LLM creates answers based on the contents of a knowledge base, such as documents stored within the company. Documents in the knowledge base are fragmented in advance, and each fragment is converted into an embedding vector value using a document embedding model. These embedding vector values and document fragments are stored as pairs in a vector database. The embedding vector values are floating-point arrays, with typical array sizes of 512 or 768. Each embedding vector value can be thought of as expressing the semantic features of each sentence fragment.
On the other hand, the question entered by the user is also converted into a single embedding vector value by the same document embedding model. The vector database is searched for the top N text fragments with embedding vector values that are highly similar to the embedding vector value of the question, and the question is input to the LLM together with the results to obtain the answer. This is the basic mechanism of RAG.
Construction of RAG system using NIM
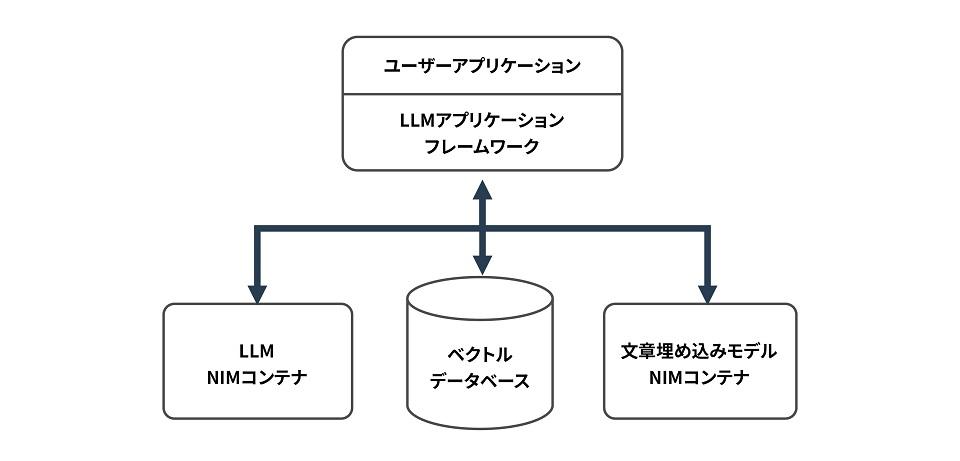
Now, let's consider the configuration when building a RAG Q&A system using NVIDIA NIM.
LLM and the sentence embedding model are included as container images in NVIDIA NIM, so containers can be started from those images. The vector database is not currently included in NVIDIA NIM, so it must be installed separately. By using an LLM application framework such as LangChain, not only LLM but also the sentence embedding model and vector database are abstracted, so that user applications do not need to interface with them directly, improving software development efficiency.
Next up: Deploying NVIDIA NIM and Vector Databases!
This article explained micro-based development and NVIDIA NIM.
Next time, we will explain the specific software and hardware required and how to deploy it.
If you are considering introducing AI, please contact us.
For the introduction of AI, we offer a wide range of services, including the selection and support of NVIDIA GPU cards and GPU workstations, as well as algorithms for face recognition, trajectory analysis, and skeletal detection, and learning environment construction services. Please feel free to contact us if you have any questions.

