- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration

What is Run:ai

Run:ai was founded in Israel in 2018 and has contributed to the world as an MLOps technology company that provides the foundation for AI infrastructure and aims to help organizations in all industries accelerate innovation in the AI era. In 2024, NVIDIA acquired Run:ai, and its adoption has expanded to various AI markets (healthcare, autonomous driving, defense, energy, and retail) from the past to the present.
*NVIDIA announced on May 17, 2024 that it had reached a definitive agreement to acquire Run:ai.
Source: https://blogs.nvidia.co.jp/2024/05/17/runai/
Challenges in corporate AI development
As an infrastructure for AI development, an increasing number of companies have prepared GPUs as computing resources and introduced Kubernetes, the de facto standard, as container orchestration for efficient container management. AI engineers involved in model development face the following challenges.
Infrastructure silos and underutilization of GPU resources
GPUs are dedicated to each department or individual, and computational resources cannot be shared, forcing inefficient work.
Delays in the AI development cycle
Different stages of AI development, such as model building, training, and production, require different GPU resources. it will cause delays.
Knowledge acquisition of Kubernetes
For developers who have no experience with container orchestration or Kubernetes, in order to proceed with the construction of an AI development environment, it takes time to acquire knowledge and construction know-how about many software including Kubernetes.
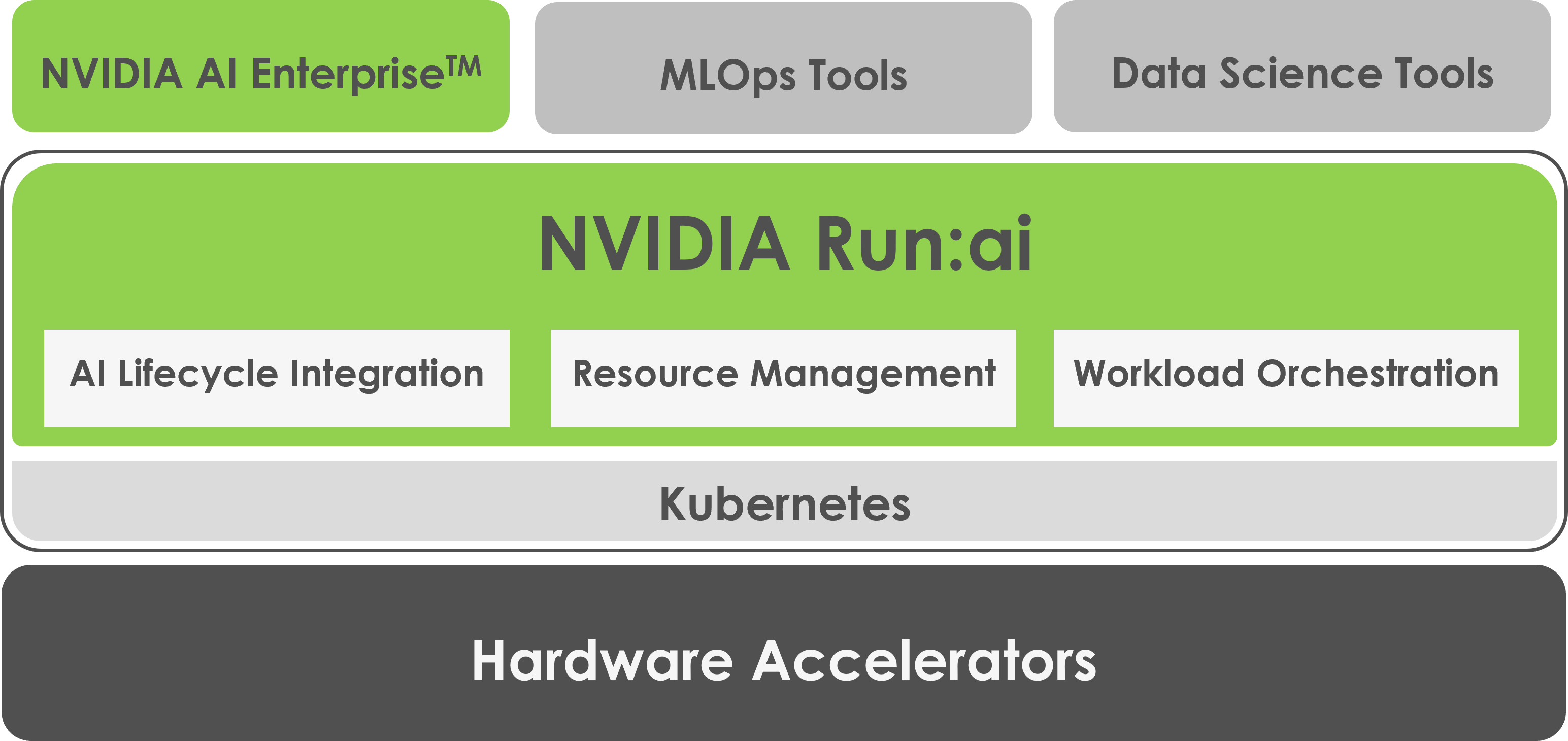
NVIDIA Run:ai is the solution
Run:ai, provided by NVIDIA, is a platform that enables dynamic and automatic sharing of GPU resources between teams and is provided as a Kubernetes plugin (software).
Full utilization of GPU resources across the organization
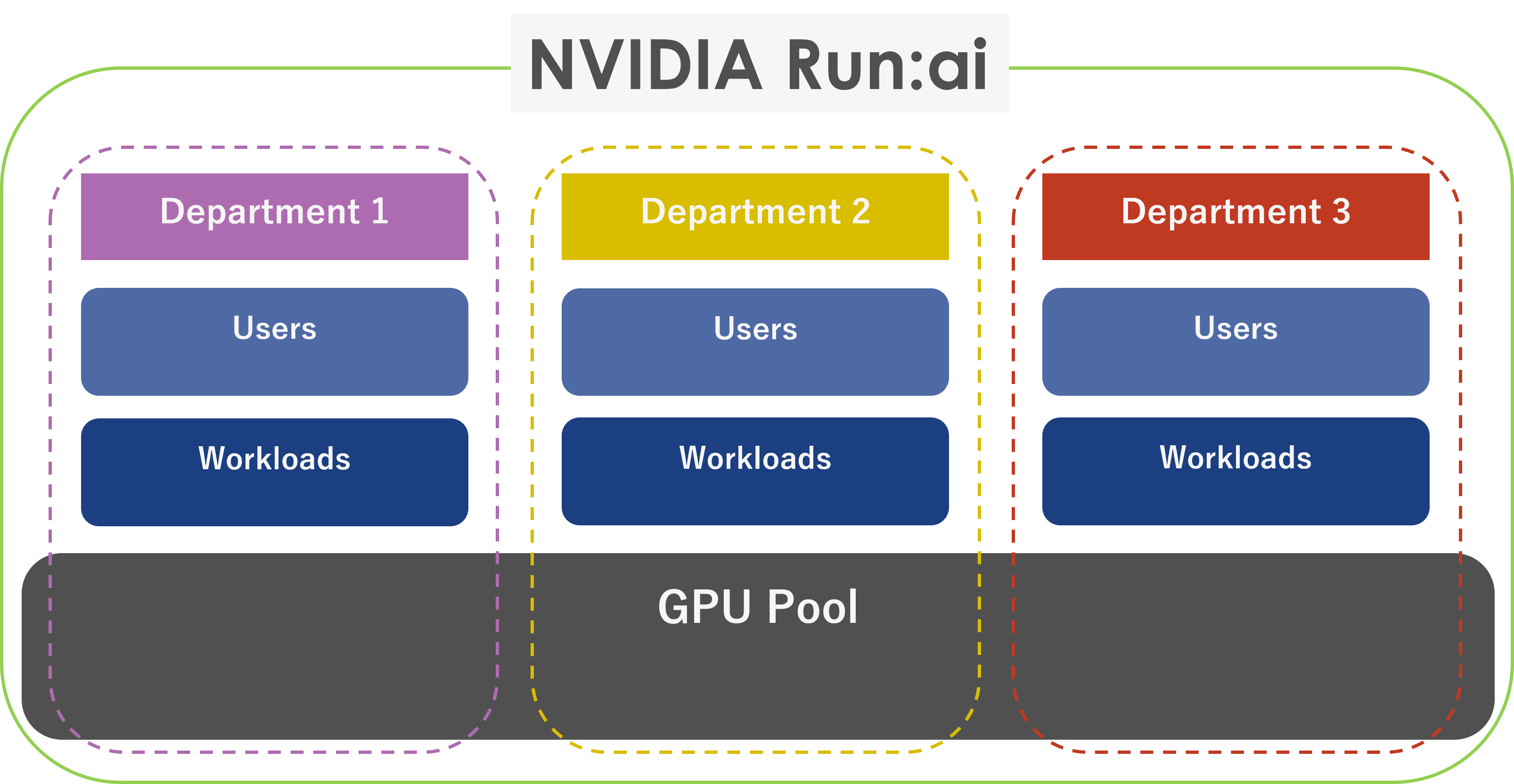
It creates a shared pool of multiple GPUs and provides an environment in which computational resources can be fully utilized across multiple organizations and projects. You can also deploy multiple containers and VMs on a single GPU, maximizing GPU utilization and dramatically impacting your company's ROI.
Fully automatic GPU resource allocation based on priority
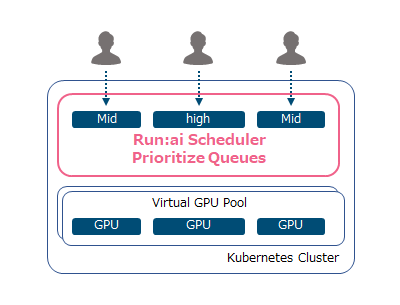
Always prioritize mission-critical workloads and automatically preempt other jobs to schedule GPU resources on the fly. In addition, computational resources can be efficiently operated by the team.
Add-on to your existing Kubernetes environment to add rich functionality
NVIDIA Run:ai's proprietary technology abstraction layer allows users to add features such as a scheduler and a centralized management user interface without requiring them to have knowledge of Kubernetes, allowing them to focus on their own AI development.
Click here for detailed information

For more information about Run:ai Atlas Platform, we have downloadable materials available.
Please use all means.
Detailed information on building a GPU cluster is available.
Basic reference materials for building GPU clusters,
"An Introduction to GPU Cluster Construction: Understanding Multi-Node GPU System Architecture for Generative AI/LLM"
We have prepared a website for you to use. Please feel free to use it. You can view the full text without entering any personal information.


Contact Us
Macnica provides MLOps solutions centered on NVIDIA products, and has many achievements in building AI infrastructure for companies.
If you are interested in AI development issues and the Run:ai Atlas Platform that solves them, please feel free to contact us.


AI TRY NOW PROGRAM
This is a support program that allows you to verify the latest AI solutions on the NVIDIA development environment before introducing them into your company.
You can gain a deeper understanding of software products, including NVIDIA AI Enterprise and NVIDIA Omniverse™, and investigate the feasibility of your implementation goals in advance.
Related product page




