- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration

A milestone in AI infrastructure
NVIDIA DGX™ B300

The NVIDIA DGX™ B300 helps you innovate and optimize your business. The latest addition to NVIDIA's legendary DGX system and the foundation of the NVIDIA DGX SuperPOD™, the DGX B300 is powered by the groundbreaking NVIDIA B300 Tensor Core GPU, accelerating the use of AI. Designed to maximize AI throughput, it provides enterprises with a highly sophisticated, systemized, and scalable platform to help them achieve breakthroughs in natural language processing, recommendation systems, data analytics, and more. Available on-premise or with a variety of access and deployment options, the NVIDIA DGX B300 delivers the performance enterprises need to solve their biggest challenges with AI.
Detailed information on the NVIDIA DGX B300 is available.
Reference material explaining the NVIDIA DGX B300 from a network perspective,
We have prepared a book entitled "A Detailed Analysis of the NVIDIA DGX™ B300 from a Network Perspective: The Role of NVIDIA ConnectX®-8 in Maximizing the Use of GPUs." Please make use of it.
You can view the full text without entering any personal information.


NVIDIA DGX™ B200

The NVIDIA DGX™ B200 is the latest generation of AI platform designed to accelerate enterprise AI innovation and strengthen competitiveness. Based on NVIDIA's innovative Blackwell architecture, the DGX B200 is a core component of the NVIDIA DGX SuperPOD™ and is optimized for large-scale generative AI and deep learning workloads. It delivers unparalleled AI computing performance, enabling enterprises to achieve unprecedented results in advanced use cases such as natural language processing, image recognition, and recommendations. The NVIDIA DGX B200 is suitable for on-premises deployment, and its high-density and efficient design allows you to quickly scale out AI projects and solve the complex challenges your organization faces with the power of AI.
NVIDIA DGX™ H200

The NVIDIA DGX™ H200 helps you innovate and optimize your business. The latest addition to NVIDIA's legendary DGX system and the foundation of the NVIDIA DGX SuperPOD™, the DGX H200 is powered by the groundbreaking NVIDIA H200 Tensor Core GPU and accelerates the use of AI. Designed to maximize AI throughput, it provides enterprises with a highly sophisticated, systemized, and scalable platform to help them achieve breakthroughs in natural language processing, recommendation systems, data analytics, and more. Available on-premise or with a variety of access and deployment options, the NVIDIA DGX H200 delivers the performance enterprises need to solve their biggest challenges with AI.
Product spec
|
NVIDIA DGX™ B300 |
NVIDIA DGX™ B200 |
NVIDIA DGX™ H200 |
|
|
GPUs |
8x NVIDIA Blackwell Ultra GPUs |
8x NVIDIA Blackwell GPUs |
8x NVIDIA H200 Tensor Core GPUs |
|
TFLOPS |
144 PFLOPS FP4 inference |
72 petaFLOPS FP8 training and 144 petaFLOPS FP4 inference |
32 petaFLOPS FP8 |
|
GPU memory |
2.3TB |
1,440GB |
1,128GB |
|
storage |
Storage OS: 2x 1.9TB NVMe M.2 |
OS: 2x 1.9TB NVMe M.2 |
OS: 2x 1.92TB NVMe M.2 |
|
network |
8x OSFP ports serving 8x NVIDIA ConnectX-8 VPI |
4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 VPI |
4x OSFP ports serving 8x single-port NVIDIA |
NVIDIA DGX Spark™
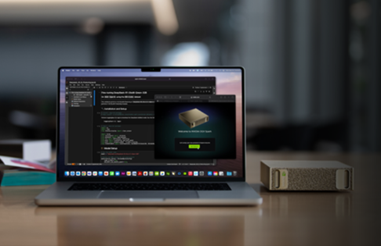
Powered by the NVIDIA GB10 Grace Blackwell Superchip, NVIDIA DGX Spark™ delivers petaFLOP1 of AI performance in a power-efficient, compact form factor. With the NVIDIA AI software stack and 128GB of pre-installed memory, developers can locally access up to 200 billion parameters and prototype, fine-tune, and infer the latest generation of reasoning AI models from DeepSeek, Meta, NVIDIA, Google, Qwen, and others.
Case study
Other GPU Servers
We also carry Supermicro GPU servers. Please contact us for more details.
|
item |
NVIDIA HGX H100/H200 Server |
NVIDIA H100 Server (Scalable ①) |
NVIDIA H100 Server (Scalable ②) |
Water-cooled Server |
|
SYS |
SYS-821GE-TNHR |
SYS-741GE-TNRT |
SYS-521GE-TNRT |
SYS-421GE-TNHR2-LCC |
|
CPU |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processorsSupports Intel Xeon CPU Max Series with high bandwidth memory (HBM) |
|
Memory |
Slot Count: 32 DIMM slotsMax Memory (1DPC): Up to 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 8TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 16 DIMM slotsMax Memory (1DPC): Up to 2TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 4TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 32 DIMM slotsMax Memory (1DPC): Up to 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 8TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 32 DIMM slotsMax Memory (1DPC): 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): 8TB 4400MT/s ECC DDR5 RDIMM |
|
form |
8U Rackmount type |
Tower Rackmount type |
5U Rackmount type |
4U Rackmount type |
|
GPU Model |
NVIDIA SXM: HGX H100 8-GPU (80GB), HGX H200 8-GPU (141GB) |
NVIDIA PCIe: H100 NVL, H100, |
NVIDIA PCIe: H100 NVL, H100 |
NVIDIA SXM: HGX H100 8-GPU (80GB), HGX H200 8-GPU (141GB) |
|
Cooling Method |
Air Cooling |
Air Cooling |
Air Cooling |
Water Cooling |
|
Image |
 |
 |
 |
 |
Detailed information on building a GPU cluster is available.
Basic reference materials for building GPU clusters,
"An Introduction to GPU Cluster Construction: Understanding Multi-Node GPU System Architecture for Generative AI/LLM"
We have them available, so please make use of them.
You can also view the full text here without entering any personal information.


Quote / Inquiry


Getting started with NVFP4 inference on NVIDIA DGX™ B200
As large-scale language models (LLMs) become larger and applications using them become more complex, reducing the amount of calculations and shortening inference times is an important issue.
The latest NVIDIA Blackwell generation GPUs, including the NVIDIA® DGX™ B200, now support 4-bit floating-point (FP4) data, which is expected to reduce the amount of calculation and shorten inference times.
The following article, spanning five parts, explains how to quantize LLM into a format called NVFP4, which is newly supported by Blackwell-generation GPUs, and then deploy it to NVIDIA® NIM™, NVIDIA's inference Microservices, for inference, as well as how to perform inference using the NVIDIA TensorRT™-LLM Python API.
Chapter 4: Benchmarking NVFP4 and FP8 Chapter 5: Deploying Llama-3.1-405B-Instruct
We will provide this information to those who fill out the form at the end of Episode 3. You will be redirected to a simple form entry screen, and after completing the form, we will send you a URL by email.



AI TRY NOW PROGRAM
This is a support program that allows you to verify the latest AI solutions on an NVIDIA environment before introducing them into your company.
You can verify the benefits of implementing software products provided by NVIDIA, including NVIDIA AI Enterprise and NVIDIA Omniverse, as well as the AI learning environments and tools that we can provide, and the feasibility of applications before purchasing.
Related product page




