- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

Run:ai とは

Run:ai は、2018年イスラエルで設立され、AIインフラの基盤を提供し、あらゆる業界の組織がAI時代のイノベーションを加速することを目的とするMLOpsのテクノロジーカンパニーとして世の中に貢献してきました。 2024年にNVIDIA社 がRun:aiを買収し、過去から現在に至るまでさまざまなAI市場(ヘルスケア、自動運転、防衛、エネルギー、リテール)に採用が広がっています。
※NVIDIA 社は、2024年5月17日にRun:aiの買収に関する最終合意に達したと発表しました。
引用元:https://blogs.nvidia.co.jp/2024/05/17/runai/
企業のAI開発における課題
AI開発のためのインフラとして、計算リソースにはGPUを準備し、効率的にコンテナ管理をするコンテナオーケストレーションとして、デファクトスタンダードであるKubernetesを導入する企業が増えました。モデル開発に携わるAIエンジニアは、下記のような課題を抱えています。
インフラがサイロ化し、GPUリソースを活用できていない
各部門もしくは個人専用のGPUとなっており、計算リソースの共有ができておらず、非効率な作業が強いられています。
AI開発サイクルにおける遅延の発生
モデル構築、トレーニング、本番稼働など、AI開発の各段階で必要とするGPUリソースは異なるが、優先順位設定ができない場合、一部の部門やクリティカルでないジョブがGPUリソースを独占してしまい、深刻な遅延を引き起こしてしまいます。
Kubernetesの知識習得
コンテナオーケストレーションやKubernetesに触れた経験のない開発者にとって、AI開発環境の構築を進めるためには、Kubernetesを含む多くのソフトウェアについて時間をかけて知識や構築ノウハウを習得しています。
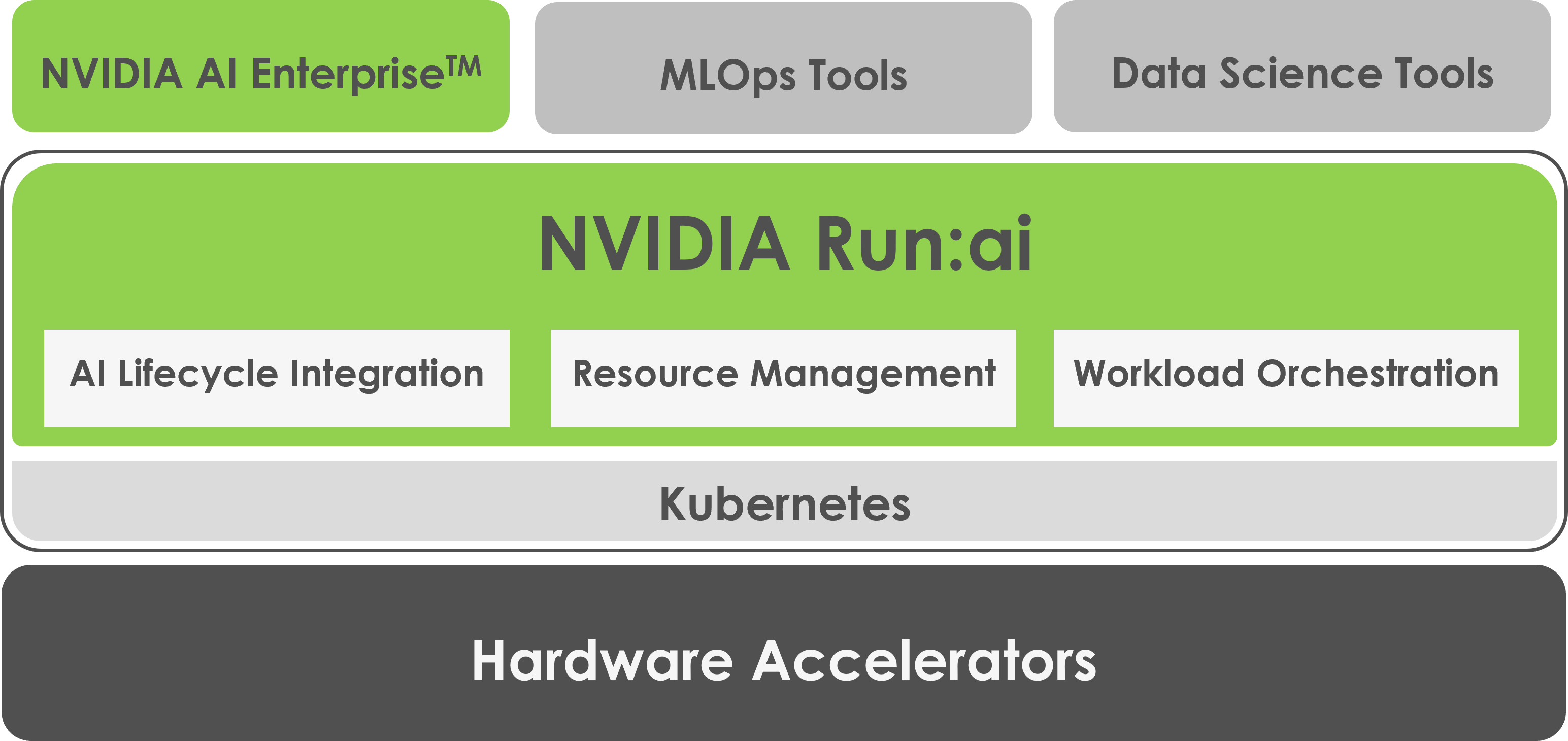
NVIDIA Run:ai が解決
NVIDIA社が提供するRun:aiは、 GPUリソースの動的かつ自動的なチーム間共有を実現するプラットフォームで、Kubernetesのプラグイン(ソフトウェア)として提供されます。
組織で横断したGPUリソースのフル活用
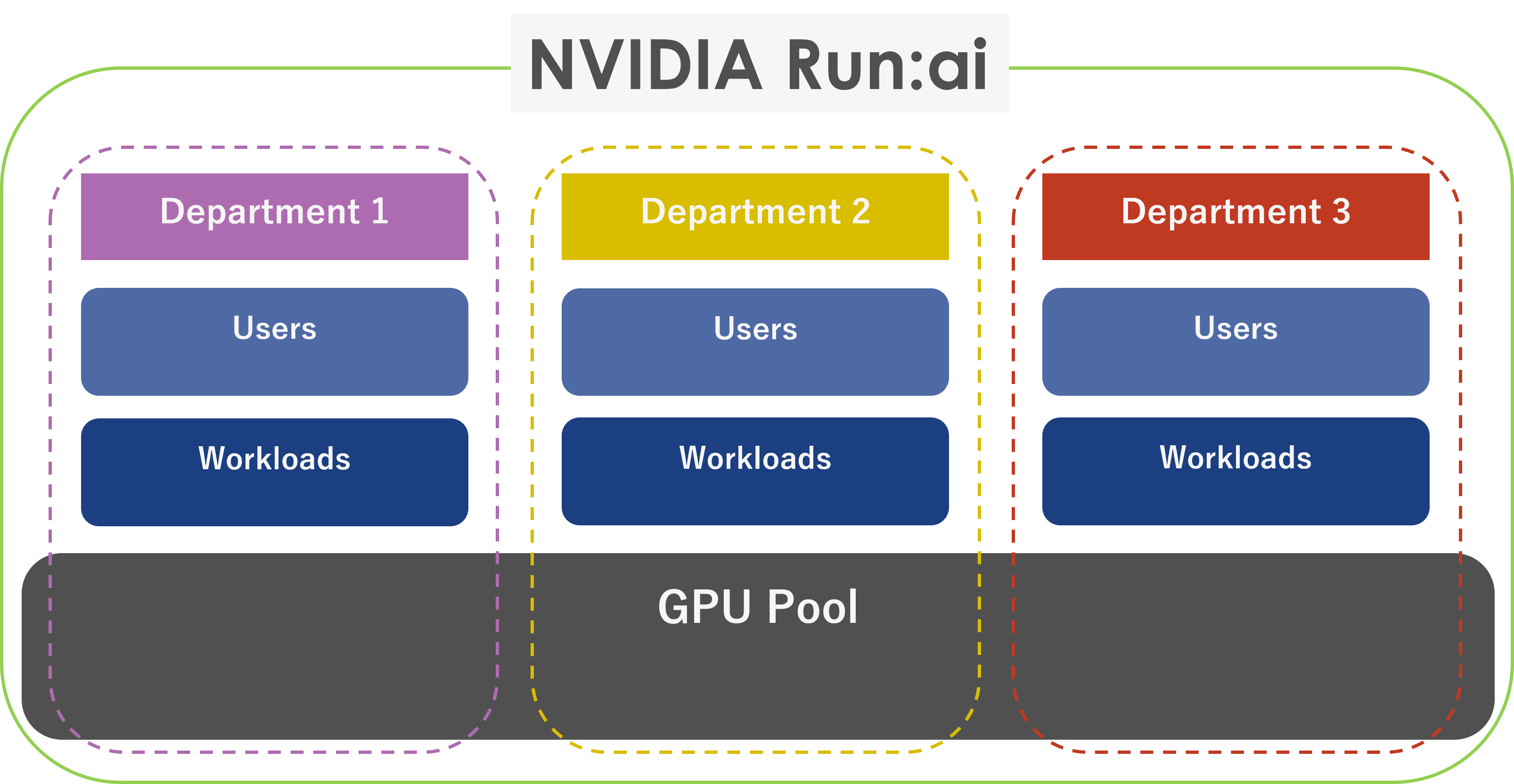
複数のGPUを共有プール化し、複数の組織、プロジェクトを横断して、計算リソースをフルに活用できる環境を提供します。また単一のGPU上で複数のコンテナやVMを実装可能で、GPU使用率を最大化し企業のROIへ劇的な影響を与えることができます。
優先順位にあわせた完全自動のGPUリソース割り当て
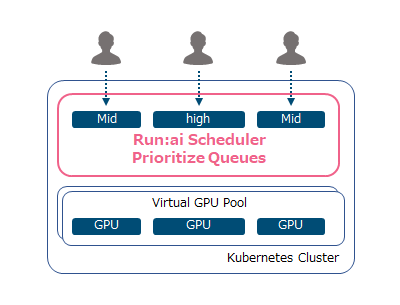
ミッションクリティカルなワークロードを常に最優先し、他のジョブを自動的に先取りして即座にGPUリソースをスケジューリング可能です。また計算リソースをチームで効率的に運用することができます。
既存のKubernetes環境にアドオンして、豊富な機能を追加
NVIDIA Run:aiの独自テクノロジーによる抽象化レイヤーにより、ユーザー側でKubernetesの知識を必要とすることなく、スケジューラーや一元管理ユーザーインターフェイスなどの機能を追加することができ、ユーザーは自身のAI開発に専念することができます。
詳細資料はこちら

Run:ai Atlas Platformの詳細について、ダウンロード資料をご用意しております。
ぜひご活用ください。
GPUクラスター構築についての詳細資料をご用意しております
GPUクラスター構築に関する基礎的な参考資料、
「超入門 GPUクラスター構築 ~生成AI/LLM向けマルチノードGPUシステムアーキテクチャーを理解する~」を
ご用意しております。ぜひご活用ください。個人情報の入力無しで全文をご覧いただけます。


お問い合わせはこちら
マクニカではNVIDIA製品を中心としたMLOpsソリューションを提供し、企業のAI基盤構築にて多くの実績がございます。
AI開発における課題とそれらを解決するRun:ai Atlas Platform にご興味をお持ちの方は、ぜひお気軽にお問合せください。


AI TRY NOW PROGRAM とは
NVIDIA開発環境上で最新のAIソリューションを自社への導入前に検証できるサポートプログラムです。
NVIDIA AI Enterprise、NVIDIA Omniverse™をはじめとするソフトウェア製品の理解を深めて、導入目的の実現性を事前に調査可能です。
関連製品ページ




