- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

AIインフラの金字塔
NVIDIA DGX™ B300

NVIDIA DGX™ B300はビジネスのイノベーションと最適化を支援します。NVIDIAの伝説的なDGXシステムの最新モデルであり、NVIDIA DGX SuperPOD™の基盤である DGX B300は、画期的なNVIDIA B300 TensorコアGPUを搭載し、AIの活用を推し進めます。AIスループットを最大化するように設計されており、高度に洗練され、システム化された拡張可能なプラットフォームを企業に提供し、自然言語処理、リコメンデーション システム、データ分析などにおいて、飛躍的な進歩を達成できるように支援します。NVIDIA DGX B300は、オンプレミスに導入できるほか、さまざまなアクセスと展開の選択肢があり、企業の大規模な課題を AIで解決するために必要なパフォーマンスを実現します。
NVIDIA DGX B300の詳細資料をご用意しております
NVIDIA DGX B300をネットワーク目線で解説した参考資料、
「ネットワーク視点のNVIDIA DGX™ B300大解剖 ~GPUを最大限活かすNVIDIA ConnectX®-8の役割~」をご用意しております。ぜひご活用ください。
個人情報入力無しで全文をご覧いただけます。


NVIDIA DGX™ B200

NVIDIA DGX™ B200 は、企業のAIイノベーションを加速し、競争力を強化するために設計された最新世代のAIプラットフォームです。NVIDIAの革新的なBlackwellアーキテクチャを採用したDGX B200は、NVIDIA DGX SuperPOD™ のコアコンポーネントとして、大規模な生成AIやディープラーニングのワークロードに最適化されています。比類ないAI演算性能を提供し、自然言語処理、画像認識、レコメンデーションなどの先進的なユースケースにおいて、企業がかつてない成果を上げることを可能にします。NVIDIA DGX B200はオンプレミスでの導入に適しており、高密度かつ効率的な設計により、AIプロジェクトを迅速にスケールアウトし、組織が直面する複雑な課題をAIの力で解決へと導きます。
NVIDIA DGX™ H200

NVIDIA DGX™ H200はビジネスのイノベーションと最適化を支援します。NVIDIAの伝説的なDGXシステムの最新モデルであり、NVIDIA DGX SuperPOD™の基盤である DGX H200は、画期的なNVIDIA H200 TensorコアGPUを搭載し、AIの活用を推し進めます。AIスループットを最大化するように設計されており、高度に洗練され、システム化された拡張可能なプラットフォームを企業に提供し、自然言語処理、リコメンデーション システム、データ分析などにおいて、飛躍的な進歩を達成できるように支援します。NVIDIA DGX H200は、オンプレミスに導入できるほか、さまざまなアクセスと展開の選択肢があり、企業の大規模な課題を AIで解決するために必要なパフォーマンスを実現します。
製品スペック
|
NVIDIA DGX™ B300 |
NVIDIA DGX™ B200 |
NVIDIA DGX™ H200 |
|
|
GPUs |
8x NVIDIA Blackwell Ultra GPUs |
8x NVIDIA Blackwell GPUs |
8x NVIDIA H200 Tensor Core GPUs |
|
TFLOPS |
144 PFLOPS FP4 inference |
72 petaFLOPS FP8 training and 144 petaFLOPS FP4 inference |
32 petaFLOPS FP8 |
|
GPUメモリー |
2.3TB |
1,440GB |
1,128GB |
|
ストレージ |
Storage OS: 2x 1.9TB NVMe M.2 |
OS: 2x 1.9TB NVMe M.2 |
OS: 2x 1.92TB NVMe M.2 |
|
ネットワーク |
8x OSFP ports serving 8x NVIDIA ConnectX-8 VPI |
4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 VPI |
4x OSFP ports serving 8x single-port NVIDIA |
NVIDIA DGX Spark™
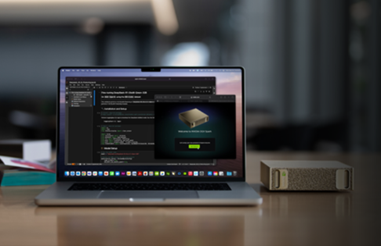
NVIDIA GB10 Grace Blackwell Superchipを搭載した NVIDIA DGX Spark™は、電力効率に優れたコンパクトなフォームファクターで、petaFLOP1のAIパフォーマンスを実現します。 NVIDIA AI ソフトウェアスタックと128GBのメモリーがプリインストールされているため、開発者は最大 2,000億パラメーターをローカルで利用でき、DeepSeek、Meta、NVIDIA、Google、Qwen などが提供する最新世代のリーズニング AI モデルのプロトタイプ作成、ファインチューニング、推論が可能です。
導入事例
その他のGPUサーバー
Supermicro社GPUサーバーも取り扱っており、詳細をご希望の方はお問い合わせください。
|
項目 |
NVIDIA HGX H100/H200サーバー |
NVIDIA H100サーバー(拡張性有①) |
NVIDIA H100サーバー(拡張性有②) |
水冷サーバー |
|
SYS |
SYS-821GE-TNHR |
SYS-741GE-TNRT |
SYS-521GE-TNRT |
SYS-421GE-TNHR2-LCC |
|
CPU |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processors |
Dual Socket E (LGA-4677)5th Gen Intel® Xeon® / 4th Gen Intel® Xeon® Scalable processorsSupports Intel Xeon CPU Max Series with high bandwidth memory (HBM) |
|
Memory |
Slot Count: 32 DIMM slotsMax Memory (1DPC): Up to 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 8TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 16 DIMM slotsMax Memory (1DPC): Up to 2TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 4TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 32 DIMM slotsMax Memory (1DPC): Up to 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): Up to 8TB 4400MT/s ECC DDR5 RDIMM |
Slot Count: 32 DIMM slotsMax Memory (1DPC): 4TB 5600MT/s ECC DDR5 RDIMMMax Memory (2DPC): 8TB 4400MT/s ECC DDR5 RDIMM |
|
形態 |
8U Rackmount型 |
Tower Rackmount型 |
5U Rackmount型 |
4U Rackmount型 |
|
GPUモデル |
NVIDIA SXM: HGX H100 8-GPU (80GB), HGX H200 8-GPU (141GB) |
NVIDIA PCIe: H100 NVL, H100, |
NVIDIA PCIe: H100 NVL, H100 |
NVIDIA SXM: HGX H100 8-GPU (80GB), HGX H200 8-GPU (141GB) |
|
冷却方法 |
空冷 |
空冷 |
空冷 |
水冷 |
|
Image |
 |
 |
 |
 |
GPUクラスター構築についての詳細資料をご用意しております
GPUクラスター構築に関する基礎的な参考資料、
「超入門 GPUクラスター構築 ~生成AI/LLM向けマルチノードGPUシステムアーキテクチャーを理解する~」を
ご用意しております。ぜひご活用ください。
こちらも個人情報の入力無しで全文をご覧いただけます。


お見積もり / お問い合わせ


NVIDIA DGX™ B200で始めるNVFP4推論
大規模言語モデル(LLM)が大型化し、それらを活用したアプリケーションが複雑化する中で、計算量の削減や推論時間の短縮は重要な課題です。
NVIDIA® DGX™ B200をはじめとする最新のNVIDIA Blackwell世代GPUでは新たに4ビット浮動小数点(FP4)型が新たにサポートされ、計算量の削減や推論時間の短縮が期待できます。
以下の記事では、全5話に渡ってBlackwell世代のGPUから新たに対応したNVFP4と呼ばれる形式にLLMを量子化し、NVIDIA社の推論用マイクロサービスであるNVIDIA® NIM™へデプロイし推論する方法やNVIDIA TensorRT™-LLM Python APIを用いて推論する方法に関して解説します。
《第4話 NVFP4とFP8のベンチマーク測定》 《第5話 Llama-3.1-405B-Instructのデプロイ》は、
3話末尾に設置しているフォームにご入力いただいた方にご案内しております。簡単なフォーム入力画面へ遷移し、入力完了後にURLをメールでお知らせいたします。



AI TRY NOW PROGRAM とは
NVIDIA環境上で最新のAIソリューションを自社への導入前に検証できるサポートプログラムです。
NVIDIA AI Enterprise、NVIDIA OmniverseをはじめとするNVIDIA社提供のソフトウェア製品や弊社が提供可能なAIの学習向け環境・ツールの導入効果やアプリケーションの実現性をご購入前に検証可能です。
関連製品ページ




