- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2189件がヒットしています。check

本連載を通してビデオ処理システムの各処理ステップで利用できるソフトウェアライブラリー(API)について解説させていただきました。高い処理性能を得るには、各処理ステップでどのAPIを選択するかは重要ですが、それらをどう組み合わせるかも非常に重要です。本連載最終回は、各APIを上手に組み合わせて、Jetson内部の計算リソースを最大活用するための指針について述べさせていただきます。
[Jetsonビデオ処理プログラミング]
第1話 NVIDIA提供 JetPackとSDKでできること
第2話 ビデオ入力(CSI接続のLibargus準拠カメラ)
第10話 計算リソースの最大活用
Jetson内部の計算リソース
まず、Jetson内部の計算リソースについておさらいをしましょう。
| 計算リソース | 用途 | アクセス可能なAPI | 備考 |
| GPU (CUDA Cores) |
|
|
|
| Deep Learning Accelerator (NVDLA) |
|
|
|
| Tensor Cores |
|
|
|
| Programmable Vision Accelerator (PVA) |
|
|
|
| NVIDIA Video Encoder Engine (NVENC) |
|
|
|
| NVIDIA Video Decoder Engine (NVDEC) |
|
|
|
| NVIDIA JPEG Engine (NVJPG) |
|
|
|
| Video Image Compositor (VIC) |
|
|
|
| Image Signal Processor (ISP) |
|
|
|
| CPU Complex |
|
あらゆるAPIを利用できるが、ビデオ系では以下のとおり。
|
|
| Audio Precessing Engine (APE) |
|
|
|
リソースを最大限に活用するための方針
上記の表で、Jetson内部には多数の計算リソースが存在することを再確認いただいたと思います。これらを最大限活用するための方針は当然ながら、すべてのリソースを休ませることなく同時に動作させることです。
注:厳密に考えると、リソースの同時動作に制約が存在する場合(データバスの競合など)もありますが、まずは単純に考えて、全リソースの同時動作を目指すこととします。
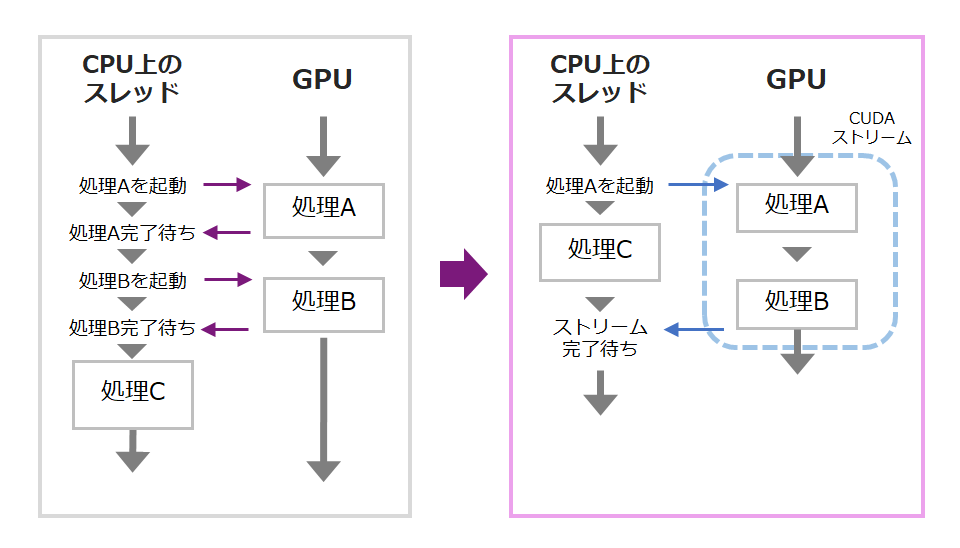
リソースが2個の場合で考えてみましょう。以下、左側の場合は、CPU上のアプリケーションスレッドがGPUに逐一、処理の開始を命じる必要があり、その間、まとまった処理が実行できません。非NULLのCUDAストリームを使うと、一つ一つのGPU処理で同期を取る必要がなくなり、GPU上で処理が進んでいる間にも、アプリケーションスレッドで別のデータに対する処理が可能となります。
CUDAストリームに類似の仕組みがVPIにも用意されています。
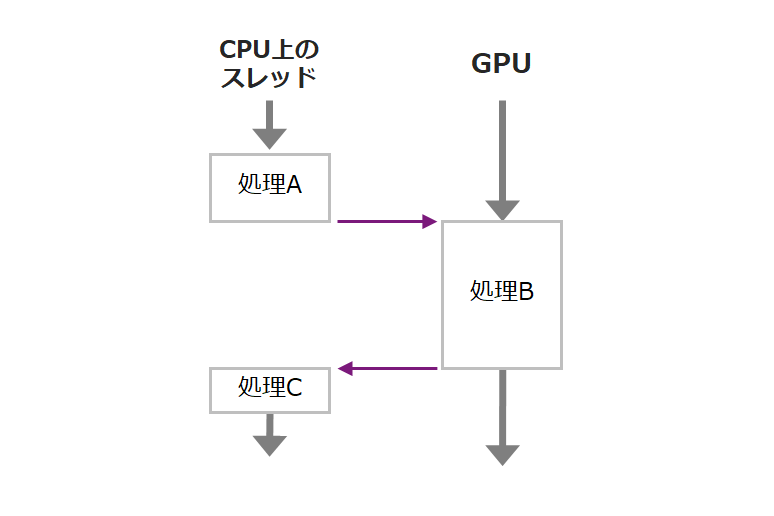
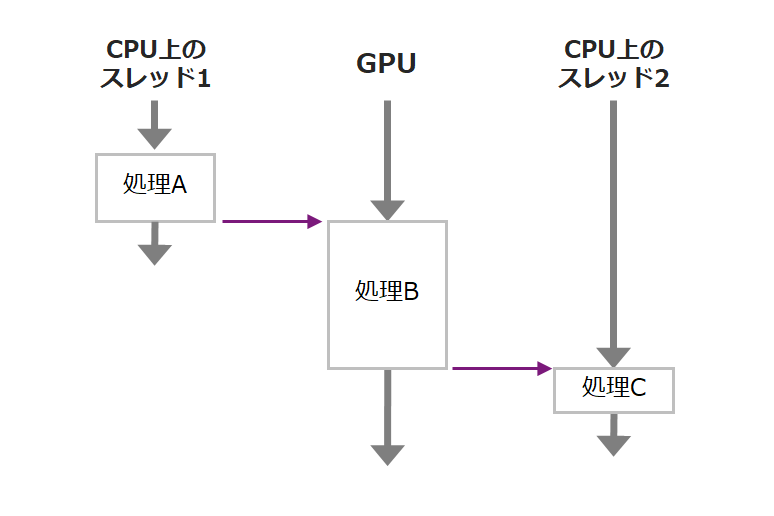
ところが、以下のように処理A,B,Cが同じデータを扱っていると、CUDAストリームやVPIストリームでは対処できません。JetsonのCPUはマルチコアですので、処理Cを別のCPUスレッドに移せば効率の良い処理ができる可能性があります。
ソフトウェアパイプライン
上記で提案させていただいた方法が上手く機能するのは、下図のように、パイプライン化できる処理です。仮に各ステップの処理がそれぞれ異なる計算リソースで実行できるとすると、流れ作業で、各リソースをなるべく休ませないで実行することができます。
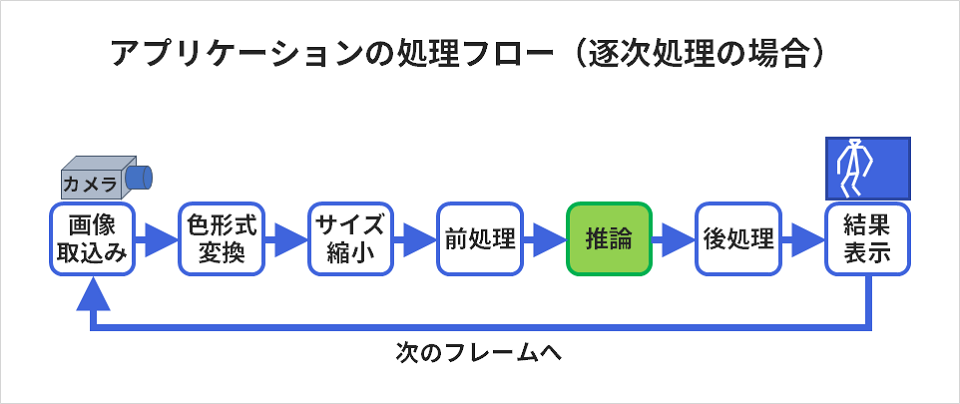
流れ作業の様子を表現したのが次の図です。
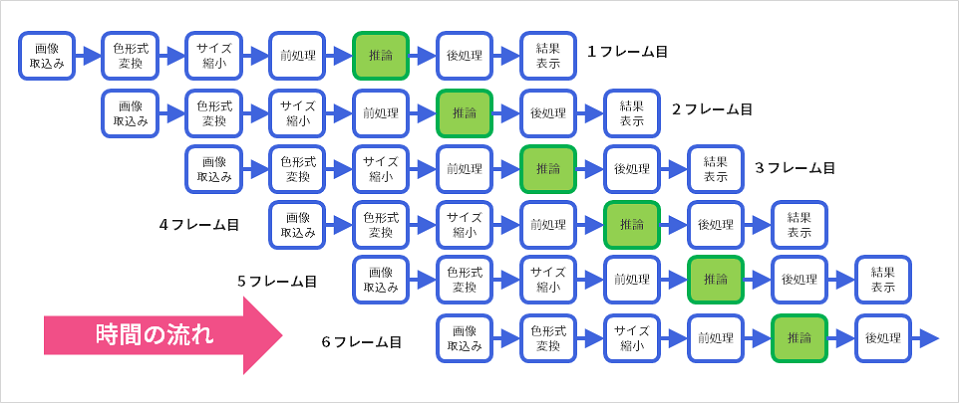
まとめ
最後に要点をまとめます。
・CUDA、VPIのストリーム機能やイベント機能は積極的に利用します。
・それでも、不十分な場合は、ソフトウェアパイプラインを設計、実装する。
このとき、マルチスレッドプログラミングは有効です。(POSIX Thread)
お困りのことがあれば、ぜひお問い合わせください
弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えております。お困りの際は、ぜひお問い合わせください。


![[AI画像解析アプリ開発に必要な知識] 第1話 NVIDIA DeepStream SDKとはのサムネイル画像](/business/semiconductor/articles/134117_thumb_r_21.png)