- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2183件がヒットしています。check

はじめに
苦労して開発したディープニューラルネットワークモデルを使って推論処理をおこなってみたら、予想外に処理時間を要して期待外れだった経験がおありかもしれません。ディープニューラルネットワークの学習に用いるディープラーニングフレームワークは、本来学習用なので推論に使用するとオーバーヘッドが大きく、期待通りの性能が出ないことがあります。その対策として学習済みディープニューラルネットワークモデルを、“推論専用ライブラリー向けにモデルを変換する”と、推論を高速化できます。
本連載では全5話に渡って、推論時間を大幅に短縮できるツールNVIDIA TensorRT(以下、TensorRTとする)の使い方と、その拡張方法について解説します。第1話である本記事ではTensorRTを利用した推論アプリケーション開発の概要について説明します。
[ディープラーニング推論の高速化術]
第1話 NVIDIA TensorRTの概要
第2話 NVIDIA TensorRTの使い方 ONNX編
第3話 NVIDIA TensorRTの使い方 Torch-TensorRT編
第4話 NVIDIA TensorRTの使い方 TensorRT API編
第5話 NVIDIA TensorRTカスタムレイヤーの作り方
TensorRTとは?使うメリットは?
TensorRTとは、NVIDIA社がNVIDIA製GPU製品向けに提供している、ディープラーニング推論を高速に実行するためのソフトウェア開発キット(SDK)です。TensorRTは推論専用のSDKであるため、学習済みモデルの最適化にフォーカスをしています。ディープラーニングフレームワークで学習したモデルに対し、推論を実行する上で最適な形へ変換させること、言い換えるとTensorRT化することにより、推論時間を大幅に短縮できるというメリットがあります。
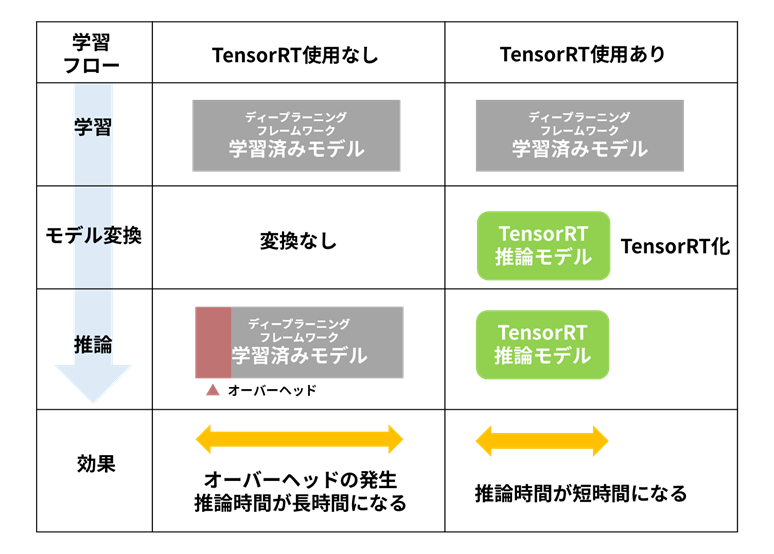
TensorRTの役割はディープラーニングフレームワークで学習したディープニューラルネットワークによる推論を高速に実行することです。TensorRTは推論専用のSDKであるため、学習済みモデルは別途用意する必要があります。
ディープニューラルネットワークの学習には、TensorFlowやPyTorchなどのディープラーニングフレームワークを利用することが多く、TensorRTはこれらディープラーニングフレームワークと相補的な役割を演じます。
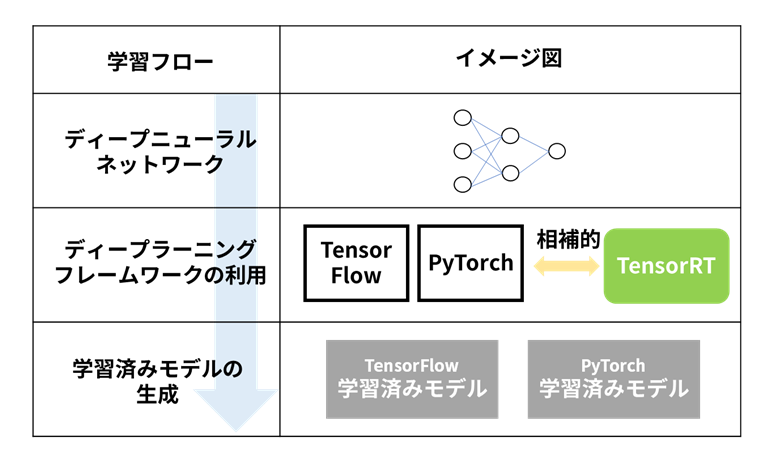
なお、TensorRTによる高速化は、ディープラーニングフレームワークのオーバーヘッド削減だけではありません。TensorRTにより、DLA(Deep Learning Accelerator)などのハードウェアアクセラレーターを効率的に使用することができるという利点もあります。どの処理をDLAに任せるかはTensorRTが自動的に判断しますので、ユーザーがDLAの使い方を理解する必要はありません。
TensorRTの利用方法
TensorRTは大別すると以下の2つの方法で利用できます。
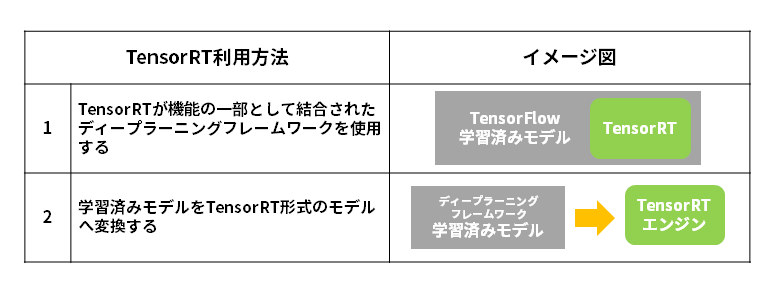
1. TensorRTが機能の一部として結合されたディープラーニングフレームワークを使用する
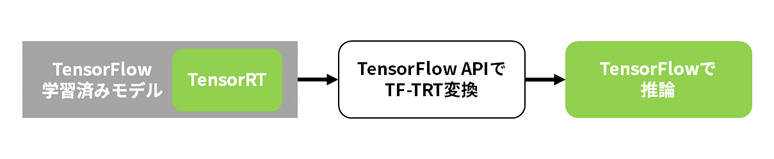
TensorFlowおよびPyTorchには、その機能の一部としてTensorRTが統合されています。TensorFlowの場合はTF-TRTと呼ばれ、PyTorchの場合はTorch-TensorRTと呼ばれます。
この機能により、ディープラーニングフレームワークからシームレスに呼び出されたTensorRTによって、高速化が発揮されます。
2. 学習済みモデルをTensorRT形式のモデル(TensorRTエンジン)へ変換する
TensorRTエンジンへ変換可能な学習済みモデルの形式は、Caffe、TensorFlow、ONNXの3通りです。ほとんどのディープラーニングフレームワークでONNX形式のサポートが進んでいますので、TensorRTは既に存在するあらゆる学習済みモデルを使って高速推論を実行できることになります。
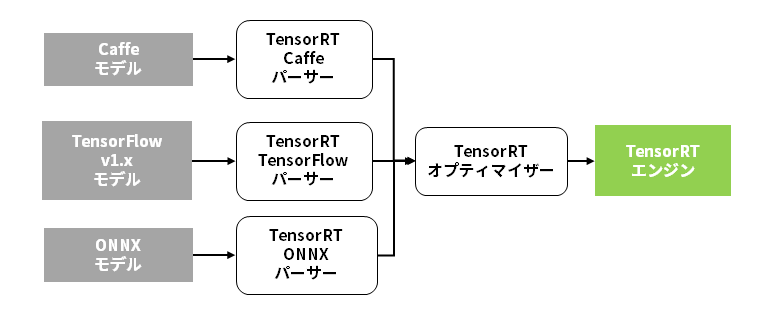
TensorRTエンジンへのモデル変換と、TensorRTによる推論処理は、ディープラーニングフレームワークなしにおこなうことができます。なお、TensorRTエンジンの形式は、GPUアーキテクチャー、TensorRTバージョン毎に異なります。TensorRTエンジンへのモデル変換は、それぞれの環境毎におこなう必要があります。
言い換えますと、異なるGPU機種間でTensorRTエンジンの互換性はありません。また、同じGPU機種であっても、異なるTensorRTバージョン間で、TensorRTエンジンの互換性はありませんので、ご注意ください。
TensorRTによる推論時間のスピードアップ効果
実際にTensorRTによって推論時間はどのくらい高速化されるのでしょうか?
使用するディープニューラルネットワークの構成や規模などにより、一概に示すことは難しいのですが、TensorRTを利用した時の推論時間を、代表的なディープニューラルネットワークについて計測した結果が、以下のページに示されております。
https://developer.nvidia.com/deep-learning-performance-training-inference#deeplearningperformance_inference
第2話以降で、学習済みモデルをTensorRTに変換して推論する方法を徹底解説!
本記事では、ディープラーニング推論を高速化するNVIDIA TensorRTについて、使用するメリットや利用方法についてご紹介しましたが、いかがでしたでしょうか。
次回は実際にTensorRTに変換する方法について解説します。2話以降の理解を深めていただくうえで、動画もご用意しています。下記ボタンをクリックすると簡単なフォーム入力画面へと遷移します。入力完了後に2話以降の記事と動画のURLがメールで通知されます。
AI導入をご検討の方は、ぜひお問い合わせください
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際は、ぜひお問い合わせください。
※サンプルプログラム、ソースコード上の細かなお問い合わせは、お受け致しかねます。あらかじめご了承ください。


関連記事
