- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2189件がヒットしています。check

今回はJetson上にディープラーニング推論を実装する方法について説明いたします。これに関しては、ぜひともTensorRTをご使用いただきたいのですが、その他の選択肢も以下の表にまとめてみました。
[Jetsonビデオ処理プログラミング]
第1話 NVIDIA提供 JetPackとSDKでできること
第2話 ビデオ入力(CSI接続のLibargus準拠カメラ)
第9話 ディープラーニング推論
| API | プログラミング言語 | コメント |
| NVIDIA TensorRT |
・C++ ・Python |
・JetsonおよびNVIDIA社GPUカード向け高速推論エンジン ・ディープラーニングフレームワークで学習したモデルをTensorRT形式へ変換して使用 ・DLAなどのアクセラレーターにも対応 |
| NVIDIA cuDNN |
・C |
・ディープニューラルネットワークを処理するCUDAライブラリー ・ほとんどのディープラーニングフレームワークは、それらの内部からこのライブラリー呼び出しているが、ユーザーアプリケーションから直接、cuDNN APIを呼び出して利用することも可能。 |
| TensorFlow |
・Python |
・主に学習用であるが、推論用に利用することも可能。 |
| PyTorch |
・Python |
・主に学習用であるが、推論用に利用することも可能。 |
TensorRTの利用
TensorRTを使うためには、学習済みモデルをTensorRT形式(TensorRTシリアライズドエンジンまたはTensorRTプランファイルと呼ばれます)へ変換する必要があります。

TensorRT形式へ変換可能なモデル形式は複数存在しますが、学習済みモデルの共通形式であるONNXをサポートしていますので、このONNX形式を介して変換をおこなうことが一般的です。
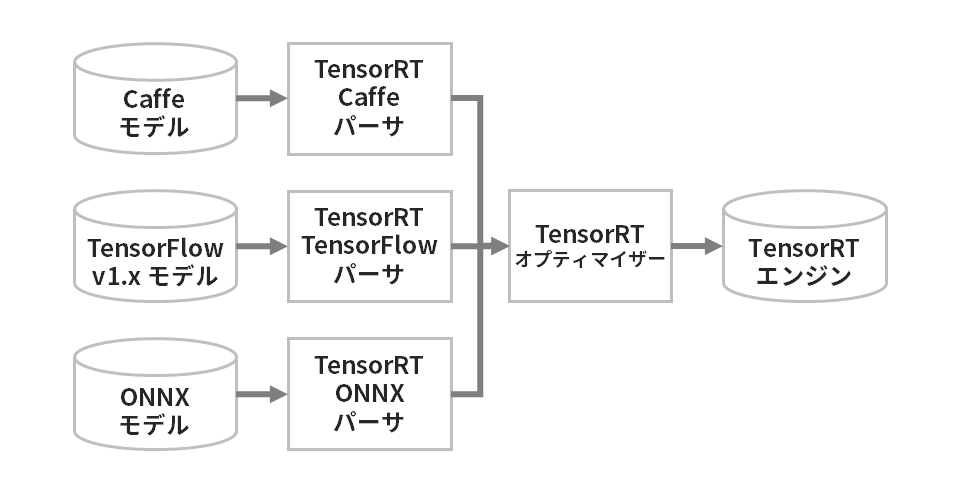
TensorRTの利用方法に関する詳細を5話連載の記事およびサンプルコードでご用意しています。ぜひご覧ください。
ディープラーニング推論の高速化術
第1話 NVIDIA TensorRTの概要
第2話 NVIDIA TensorRTの使い方 ONNX編
第3話 NVIDIA TensorRTの使い方 torch2trt編
第4話 NVIDIA TensorRTの使い方 TensorRT API編
第5話 NVIDIA TensorRTカスタムレイヤーの作り方
cuDNNの利用
cuDNN APIを利用することで、ニューラルネットワークをユーザーが詳細に定義できます。ただし、学習済みの重み値やバイアス値もユーザーがcuDNNのAPIを利用して設定する必要がありますので、プログラミング工数は大きくなります。特殊な処理層をユーザーが定義したい場合などに限ってcuDNNを直接利用すべきで、通常は先に紹介いたしましたTensorRTを利用すべきと考えます。
cuDNNサンプルプログラム
cuDNN 8.xの場合、Jetson上の以下のディレクトリーにサンプルプログラムが存在します。
/usr/src/cudnn_samples_v8
| サンプル | 内容 |
| conv_sample | 畳み込み層処理関数使用例 |
| mnistCUDNN | cuDNNを利用したMNIST |
| multiHeadAttention | Multi-head attention APIの使用例 |
| RNN | 再起型ニューラルネットワークの処理例 |
| RNN_v8.0 | 再起型ニューラルネットワークの処理例 |
TensorFlowの利用
Jetson内蔵GPUが有効になったTensorFlowはNVIDIA社からリリースされています。
Installing TensorFlow For Jetson Platform
Dockerコンテナによる実行も可能です。
NVIDIA NGC Catalog > Containers > NVIDIA L4T TensorFlow(JetPack 5以前)
NVIDIA NGC Catalog > Containers > TensorFlow(JetPack 6以降、タグ末尾「-igpu」がJetson向け)
PyTorchの利用
Jetson内蔵GPUが有効になったPyTorchはNVIDIA社からリリースされています。
Installing PyTorch for Jetson Platform
Dockerコンテナによる実行も可能です。
NVIDIA NGC Catalog > Containers > NVIDIA L4T PyTorch(JetPack 5以前)
NVIDIA NGC Catalog > Containers > PyTorch(JetPack 6以降、タグ末尾「-igpu」がJetson向け)
次回で完結!計算リソースの最大活用について解説します!
連載記事「Jetsonビデオ処理プログラミング」の第9話、ディープラーニング推論についてご紹介しましたがいかがでしたでしょうか。
次回は最終話となり、計算リソースの最大活用についてご紹介します。
お困りのことがあれば、ぜひお問い合わせください
弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えております。お困りの際は、ぜひお問い合わせください。


![[AI画像解析アプリ開発に必要な知識] 第1話 NVIDIA DeepStream SDKとはのサムネイル画像](/business/semiconductor/articles/134117_thumb_r_20.png)