- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2189件がヒットしています。check

[Trying out AI persona marketing with NVIDIA DGX Spark]
Episode 1: Overview of the Demo
Episode 2: Selection of the Subjects to be Investigated
Episode 3: Question Generation
Episode 4: Generating and Collecting Responses
Episode 5: Visualizing the Survey Results
Episode 6 Summary
What is persona marketing?
A persona is a fictional character created in user-centered design and marketing to represent a typical user of a website, brand, or product. (Source:Wikipedia: Persona(User Experience))
The practice of using thesepersonas to improve the accuracy of marketing activities is called persona marketing. In recent years, with the development of large-scale language models (LLMs),there has been an increase in attempts to incorporate LLMs into persona marketing to improve efficiency. An LLM that fully embodies the defined persona is called an "AI persona" or "digital persona," and the following use cases are conceivable.
- Conduct a survey using AI personas.
- We develop product plans while engaging in repeated discussions with AI personas.
The purpose of this demonstration
The purpose of the AI persona marketing demo presented in this article is as follows:
-This section demonstrates the process by which LLMs respond to a questionnaire survey, based on personas extracted from Nemotron-Personas-Japan (*1), a synthetic dataset of personas reflecting Japanese demographics, occupations, and lifestyles.
- The creation of survey questions and answer choices will also be entrusted to the LLM, demonstrating that it works.
- This demonstrates that all of the above processes can be performed on NVIDIA DGX Spark™.
*1: Fujita, A., Gong, V., Ogushi, M., Yamamoto, K., Suhara, Y., Corneil, D., & Meyer, Y. (2025). Nemotron-Personas-Japan: Synthetic Personas Aligned to Real-World Distributions. https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
The subject matter of this demo (it is hypothetical; no real-world project exists)
In order to plan a new gummy candy product, we plan to conduct a survey of target consumers (*2) to obtain hints for deciding on the following matters.
- Flavor
- Package design
- Talent to be featured in the commercial
We will use LLM for the following process.
- Create a questionnaire
- Survey responses
The demo program was implemented in Python and tested on a Jupyter notebook.
*2: In this demo, an LLM (Limited Liability Manager) is given persona data and answers a questionnaire on behalf of the consumer.
Notes
- We do not guarantee that the methods used in this demonstration will be effective in actual marketing activities.
- We do not believe that surveys targeting LLMs (Language-Based Learning) can completely replace surveys targeting humans;we consider them merely supplementary tools.
- In this demo,we prioritized ease of use andusedthe Nemotron-Personas-Japan dataset as persona data. However,the original purpose of the Nemotron-Personas-Japan dataset is to serve as a seed when users generate their own synthetic data.
Reference: Synthetic data generation using NVIDIA NeMo Data Designer with Nemotron-Personas-Japan
processing pipeline
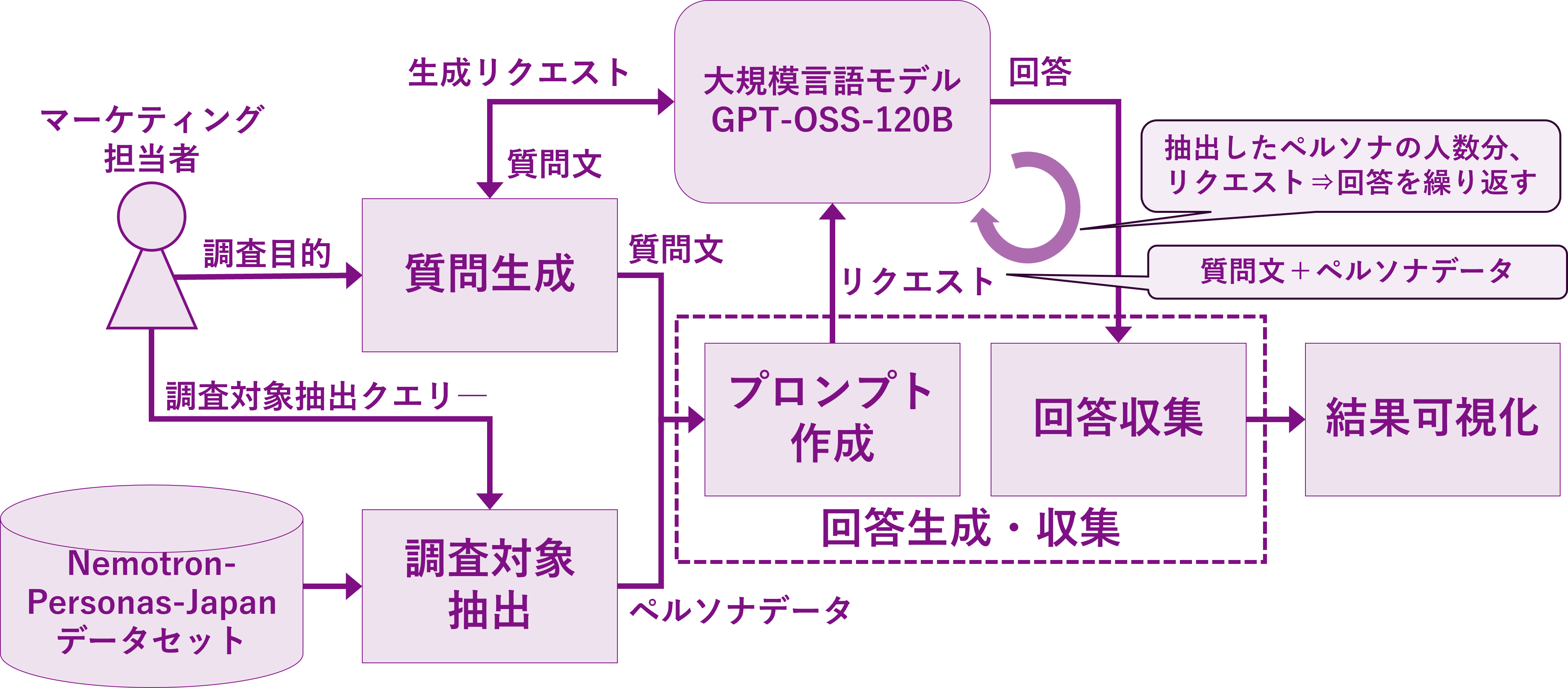
The processing pipeline for this demo is as follows:
1. Selection of survey subjects
- Load the Nemotron-Personas-Japan dataset into a cuDF dataframe and extract the target subjects based on specified conditions.
2. Question generation
- Provide the LLM with a prompt specifying the research objectives and the number of questions, and obtain a set of questions and answer choices from the LLM.
3. Response generation and collection
- Create prompts from persona data and questions, and get answers from LLMs who are fully embodying the persona.
- Repeat the above process for each persona extracted.
4.Result visualization
- Summarize the results and display them in a graph.
Dataset
We used the Nemotron-Personas-Japan dataset, publicly available from NVIDIA, as persona data.
The features of the Nemotron-Personas-Japan dataset are as follows:
Features of the dataset
- An open-source dataset of synthetically generated personas based on real-world demographics, geographical distribution, and personality trait distribution, with the aim of capturing the diversity and richness of the Japanese population.
Dataset contents
- 1 million records recorded in Japanese (6 personas per record → 6 million personas in total)
- 22 fields: 6 persona fields and 16 context fields based on official demographic and labor statistics.
- Approximately 1.4 billion tokens (of which approximately 850 million are Persona-related tokens)
- Comprehensive data spanning demographics, geography, personality traits, and other axes.
- Approximately 950,000 unique names
- Over 1,500 occupational categories reflecting Japan's workforce
- Diverse persona types including professionals, sports, arts, travel, and cooking.
- Natural language persona attributes such as cultural background, skills and expertise, goals and aspirations, hobbies and interests.
hardware
This demo runs the entire processing pipeline, including LLM, locally on the NVIDIA DGX Spark (*3).
The features of NVIDIA DGX Spark are as follows:
- Equipped with NVIDIA GB10 Grace Blackwell Superchip
- Compact form factor with excellent power efficiency
- AI performance of 1 PFLOP (FP4)
- 128GB LPDDR5x integrated system memory
- Run LLM locally
*3: Includes systems equipped with the NVIDIA GB10 Grace Blackwell Superchip, sold by NVIDIA partners.
Summary of this episode
This concludes our overview of the AI persona marketing demo built on NVIDIA DGX Spark. In the next installment, we will explain how to obtain the Nemotron-Personas-Japan dataset and extract the target audience for your research.
Contact Us

