- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2127件がヒットしています。check

Qualcomm AI Hubを活用したAIモデルのエッジデバイス実装
Qualcomm AI Hubは、エッジデバイス上でのビジョン、オーディオ、音声アプリケーション向けに、AIモデルの最適化・検証・デプロイを支援するプラットフォームです。
あらかじめ最適化されたAIモデルのライブラリーや、AI開発プロセスを効率化する各種ツールを提供しています。
Qualcomm AI Hubプラットフォームに関する概要を知りたい方はこちら
本記事では、AI Hubを使って物体検出でおなじみのYOLOモデルをQualcommデバイス向けに最適化し、最終的にオンデバイスでアプリケーションを動かすまでの一連のフローを解説します。
実装手順
検証環境(使用機材一覧)
■AIモデルのエクスポート
・PC: Ubuntu 22.04(WSL2も利用可)
■推論アプリケーション実行
・RB3 Gen2 Development Kit
・HDMIディスプレイ
・USB Type-Cケーブル
AI Hubでモデルを用意する
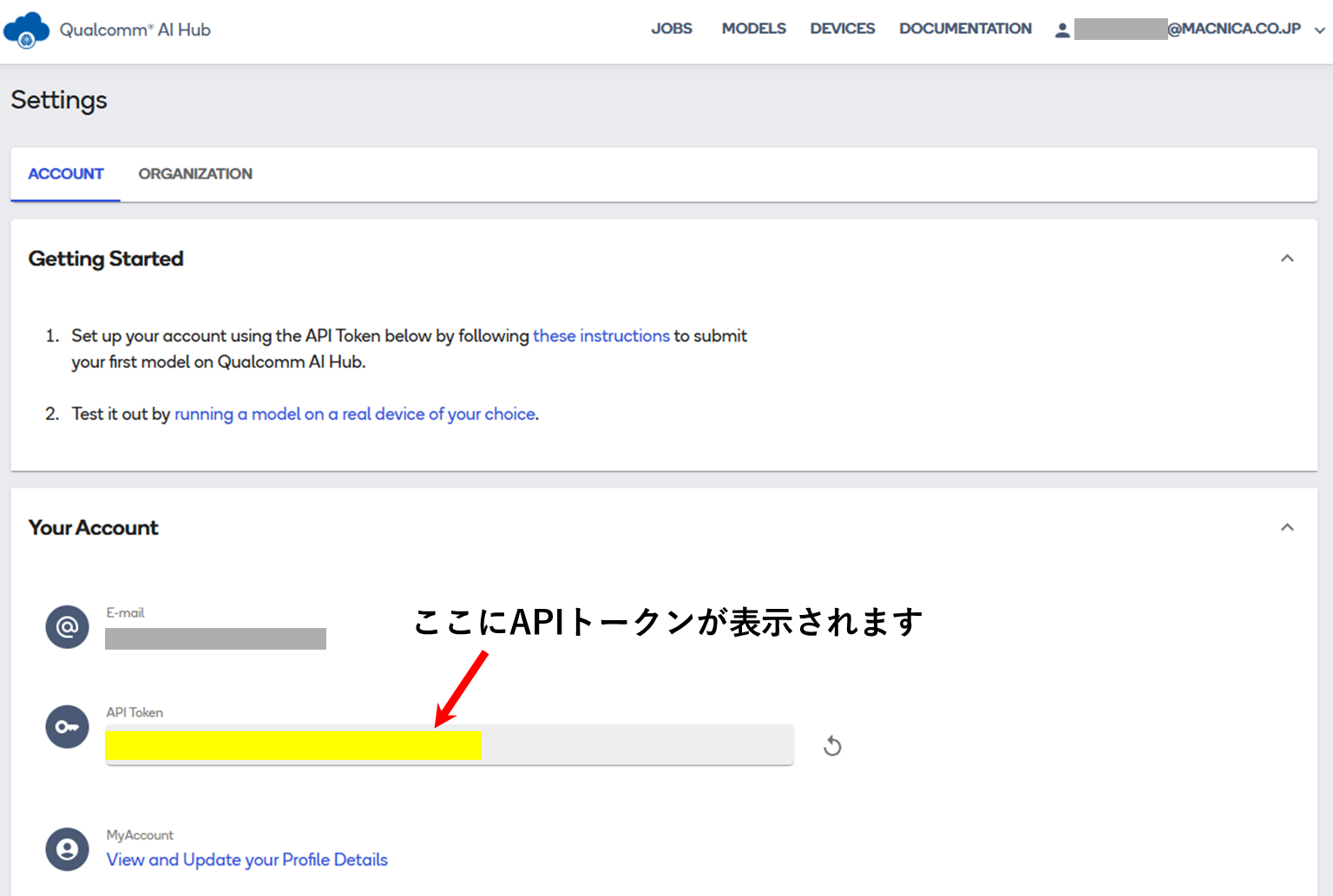
Qualcomm AI HubにサインインしAPIトークンを設定する
AI Hubのアカウント設定ページで自身のAPIトークンを取得します。このトークンは後のステップで使用します。
※Qualcomm ID(Webサイトと共通)をお持ちでない場合は、こちらのページから作成してください。
仮想環境を起動する
本例では、miniconda を使いqai_hubという名称で仮想環境を起動します。
$ mkdir -p ~/miniconda3
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
$ bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
$ rm ~/miniconda3/miniconda.sh
$ source ~/miniconda3/bin/activate
(base) test@SDTEST:~$ conda create python=3.10 -n qai_hub
(base) test@SDTEST:~$ conda activate qai_hub
(qai_hub) test@SDTEST:~$AI Hub の Python パッケージをインストールする
(qai_hub) test@SDTEST:~$ pip3 install qai-hubqai_hubのminiconda環境を起動したターミナルからAI HubのAPIトークンを設定します。
(qai_hub) test@SDTEST:~$ qai-hub configure --api_token <自身のAPIトークン>
APIトークンの設定が完了したら、Pythonを起動、下記のようにAI Hubに対応するデバイス一覧を取得するモジュールを実行し、出力としてデバイス一覧が表示されることを確認します。
(qai_hub) test@SDTEST:~$ python
Python 3.10.18 (main, Jun 5 2025, 13:14:17) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import qai_hub as hub
>>> hub.get_devices() # デバイス一覧が表示されますこれで AI Hub の事前設定は完了です。
YOLOv8-Detectionモデル用ライブラリーをインストールする
このコマンドを実行することで、設定したモデルに対して以降の処理を行う際に必要なPythonパッケージを自動でインストールします。
(qai_hub) test@SDTEST:~$ pip install "qai-hub-models[yolov8-det]"モデルをエクスポートする
今回の例では、
・量子化を w8a8
・ターゲットランタイムを TensorFlow Lite
・デバイスを RB3 Gen2 (Proxy)
とし、以下のコマンドでQualcomm AI Hubで用意されているモデルexportのモジュールを実行します。
(qai_hub) test@SDTEST:~$ python -m qai_hub_models.models.yolov8_det.export \
--quantize w8a8 \
--target-runtime=tflite \
--device "RB3 Gen 2 (Proxy)" \
--output-dir /home/test/aihub/exportモジュールの実行が成功すると指定したディレクトリにTensorFlow Lite形式(.tflite)のモデルが生成されます。
yolov8_det.tfliteというモデルが出力されますが、後のステップ簡略化のためファイル名はyolov8_det_quantized.tfliteに変更しておきます。
(qai_hub) test@SDTEST:~/aihub$ ls
yolov8_det.tflite
(qai_hub) test@SDTEST:~/aihub$ mv yolov8_det.tflite yolov8_det_quantized.tflite
(qai_hub) test@SDTEST:~/aihub$ ls
yolov8_det_quantized.tfliteexportモジュールの解説
exportモジュールは下記の 7 ステップ から構成されます。次の手順に進む前に、各ステップで行っている処理を詳しく解説します。
1. PyTorch モデルをTorchScriptに変換する
まずはPyTorchで定義された YOLOv8-Detectionモデルを、TorchScript形式にトレースします。
この処理により、Pythonのランタイム依存を切り離した中間表現が生成され、以降のエクスポートや最適化が安定して実行できるようになります。
2. ONNX形式への変換と量子化の実行
次に、先ほど作成したTorchScriptモデルを一度ONNXフォーマットに変換します。
その後、指定したビット幅(今回は w8a8)での量子化処理を行います。
量子化には、モデルの入出力特性に応じた校正用データを自動生成し、そのデータを使って重み・活性化を圧縮します。
3. ターゲットランタイム向けのコンパイル
量子化済み(またはそのままの)モデルを、TensorFlow Lite向けにビルドします。
この段階では、チャネルレイアウトの最適化や演算ユニット固有の高速化オプションなど、ターゲットランタイムに合わせた最適化パラメーターが自動で組み込まれます。
4. 実機(ホストデバイス)上でのプロファイリング
コンパイルしたモデルを実際のデバイス上で動作させ、レイテンシやスループットを測定します。
ウォームアップや複数反復の設定を行うことで、結果のばらつきを抑え、安定したパフォーマンス指標を取得します。
5. 実機上でのサンプル推論
続いて、用意したサンプル入力データをデバイス上で推論し、その出力結果を取得します。
同じ入力セットをホスト側(Python/PyTorch)でも実行して、出力の一致性や精度差異(IoU など)を比較・検証します。
6. モデルアセットのローカルダウンロード
正常にビルド・動作確認ができたら、TensorFlow Liteバイナリーや付随するメタデータファイル一式をローカル環境にダウンロードします。
これにより、後続のデプロイ工程に成果物をそのまま渡せるようになります。
7. プロファイル&推論結果のサマリ表示
最後に、取得したプロファイル指標と推論結果の比較データをターミナル上に出力します。
加えて、実機でのデモ実行を容易にするADBコマンドのワンライナーを自動生成し、次のステップへの移行をスムーズにします。
エッジデバイスでYOLOv8の物体検出アプリケーションを実行する
Qualcomm SoCには、tflite形式のモデルをQualcomm独自DSPコアのランタイムで実行する仕組みがあります。
そのため、AI Hubでエクスポートしたtfliteモデルを実機へ転送し、そのまま実行可能です。
本例では、Qualcomm QCS6490 SoC搭載のRB3 Gen2開発キットを使い、エッジデバイス上でYOLOv8-Detectionの物体検出アプリを実行します。
RB3 Gen2開発キットにはサンプルアプリが含まれたSDKが提供されています。
エクスポートモデル、ラベルファイル、設定用JSONを用意するだけで、デモアプリケーションをすぐに実行できます。
モデルの準備
前のステップでAI Hub経由でエクスポートしたYOLOv8のtfliteファイル(yolov8_det_quantized.tflite)をRB3 Gen2に転送します。
(PC) $ adb push [任意のパス]/yolov8_det_quantized.tflite /etc/modelsラベルの準備
ラベルファイルはQualcommが提供しているものを活用します。
RB3 Gen2をネットワークに接続し、curlコマンドで必要なファイルのダウンロードスクリプトを取得、実行します。
(インターネットに繋がっているPCで必要なファイルをダウンロードしてからRB3 Gen2に転送することも可能です。)
(PC) $ adb shell
(RB3Gen2) # cd tmp
(RB3Gen2) # curl -L -O https://raw.githubusercontent.com/quic/sample-apps-for-qualcomm-linux/refs/heads/main/download_artifacts.sh
(RB3Gen2) # chmod +x download_artifacts.sh
(RB3Gen2) # ./download_artifacts.sh -v GA1.4-rel -c QCS6490
以下に示すように、/etc/labelsディレクトリーにラベルファイルのセットがダウンロードされています。このデモではyolov8.labelsを使用します。
(RB3Gen2) # ls /etc/labels/
cityscapes_labels.txt imagenet_labels.txt
classification.labels monodepth.labels
coco_labels.txt posenet_mobilenet_v1.labels
deeplabv3_resnet50.labels voc_labels.txt
face_detection.labels yamnet.labels
face_landmark.labels yolonas.labels
face_recognition.labels yolov8.labels
hrnet_pose.labels yolox.labels
hrnetpose.labels動画ファイルの準備
このデモでは入力ソースとして動画ファイルを使用します。任意のmp4ファイルをRB3 Gen2の/etc/mediaに格納します。
今回は弊社で用意した動画ファイルを使用していますが、RB3 Gen2の/etc/mediaに入っているサンプル動画ファイルをご使用いただくこともできます。
使用する動画ファイルのパスに合わせて次のconfig_detection.jsonのfile-pathを修正してください。
JSONファイルの準備
設定用のJSONファイルはRB3 Gen2にデフォルトで入っている/etc/configs/config_detection.jsonを使います。
前述の通り、file-pathは任意のパスを指定します。また、このJSONファイルで先ほどのモデルやラベルファイルのパスも指定しています。
config_detection.jsonファイル例
{
"file-path": "/etc/media/video.mp4",
"ml-framework": "tflite",
"yolo-model-type": "yolov8",
"model": "/etc/models/yolov8_det_quantized.tflite",
"labels": "/etc/labels/yolov8.labels",
"constants": "YOLOv8,q-offsets=<21.0, 0.0, 0.0>,q-scales=<3.0546178817749023, 0.003793874057009816, 1.0>;",
"threshold": 40,
"runtime": "dsp"
}これでデモの準備は完了です。
サンプルアプリ実行
RB3 Gen2をHDMIケーブルでディスプレイに接続し、グレーの花模様の背景画面が表示されていることを確認します。
下記のコマンドでサンプルアプリ(gst-ai-object-detection)を実行します。
コマンド実行例
(RB3Gen2) # gst-ai-object-detection --config-file=/etc/configs/config_detection.json
入力した動画にYOLOv8の検出対象となる物体を囲むバウンディングボックスが描画された状態でディスプレイに表示されます。
以上のように簡単にYOLOモデルを用いた物体検出アプリケーションをエッジデバイスで実行することができました。
今回使用したgst-ai-object-detectionアプリケーションのソースコードはOSSとして公開していますので、用途に合わせてカスタムいただけます。
おわりに
本記事では、AI Hubを使ったモデル最適化から実機実行までの流れを紹介しました。
AI Hubには他にも多数の便利機能があります。ぜひ一度お試しいただき、Qualcomm SoC製品への組み込みにお役立てください。
お問い合わせ
本ページの内容に関するご質問や製品詳細情報をご希望の方はこちらからお問い合わせください。

