- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2183件がヒットしています。check

CNN architecture that caused a breakthrough in improving the accuracy of AI image recognition
machine learning/In the field of deep learning, technology related to image recognition has been researched and developed for many years. Especially since the 2010s, remarkable progress has been made, and convolutional neural networks(Convolutional Neural Network; CNN) andA new architecture called ``synthesis'' has been proposed and the recognition accuracy has improved at an astonishing rate. The architecture of CNN is widely applied to image recognition systems currently in practical use.
In the field of image recognition, there is an error rate in a competition for image classification accuracy, such as ILSVRC, as an indicator of performance.CNNBefore it came out, even the top 5 teams had an error rate of over 26%, and the performance was not at a practical level. But at ILSVRC in 2012AlexNet, which is based on CNN, achieved a significant improvement in accuracy, triggering the CNN boom.Year after year, the record continued to be broken, and after a few years the error rate reached less than 3%. The classification of the image dataset given as a task in this competition is extremely difficult, and even when viewed by the human eye,Four%It is said that the error rate will be about3%It turns out that less than is an amazing record. Based on CNN, epoch-making architectures have been proposed one after another from various research institutes and companies.on this pageModel based on CNNAmong them, we will introduce a famous architecture that has achieved particularly outstanding error rate improvement.
LeNet-5
LeNet is the first CNN architecture, and is the basic structure of CNN that has been widely applied in the field of AI image recognition in recent years.
It is an architecture originally conceived and researched to solve the problem of identifying handwritten digits used in postal codes. It is trained on the MNIST dataset, and we vary the weights and hyperparameters to find the parameters that minimize the loss function. The input size of LeNet is 32 x 32 pixels, which is larger than the original image. This is because the outside of the image is padded, and if the original image size is passed through the convolution layer1The purpose is to prevent the image size from becoming too small from the first layer, making it difficult to capture the features of the numbers in subsequent layers. This process makes it possible to capture fine features from the image.
LeNetは畳み込み層、サブサンプリング層、全結合層から構成されています。
・Convolution layer(Convolutions)⇒ Convolution operation is performed and features are extracted from the image.
・Subsampling layer ⇒ Apply the activation function to the input from the convolution layer, and perform pooling processing on the obtained output.
・Full connection⇒ Connect each neuron in one layer with each neuron in another layer.

AlexNet
In our research on the LeNet architecture, we found that increasing the depth of the network improves accuracy. AlexNet is an architecture based on the knowledge obtained in LeNetand consists of 5 convolutional layers and 3 fully connected layers. In 2012,AlexNetachievedan overwhelmingfirstplace score inan image recognition competition called ILSVRC, sparking the 3rdAIboom.ILSVRCis a competition that competes for the lowest error rate in image recognition, but AlexNet's result is 15.3%, which is clearly lower than 26.2% for non-CNN. It was a model that utilized deep learning technology, which had not been used before, and this triggered deep learning to attract attention at once.
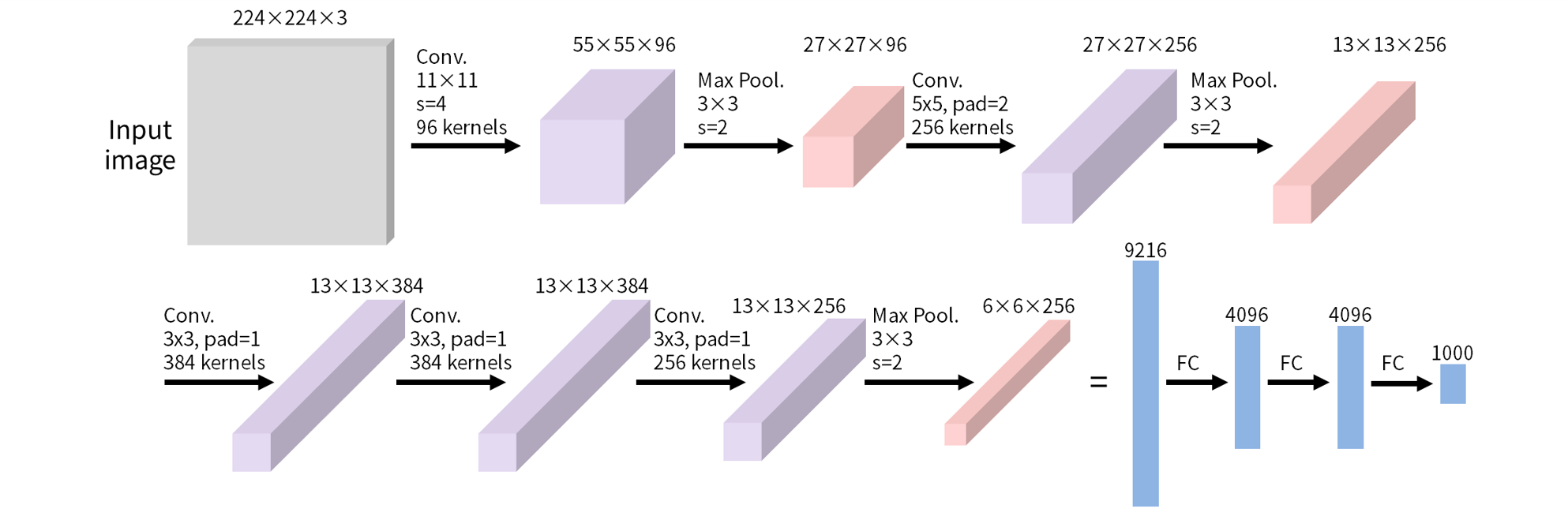
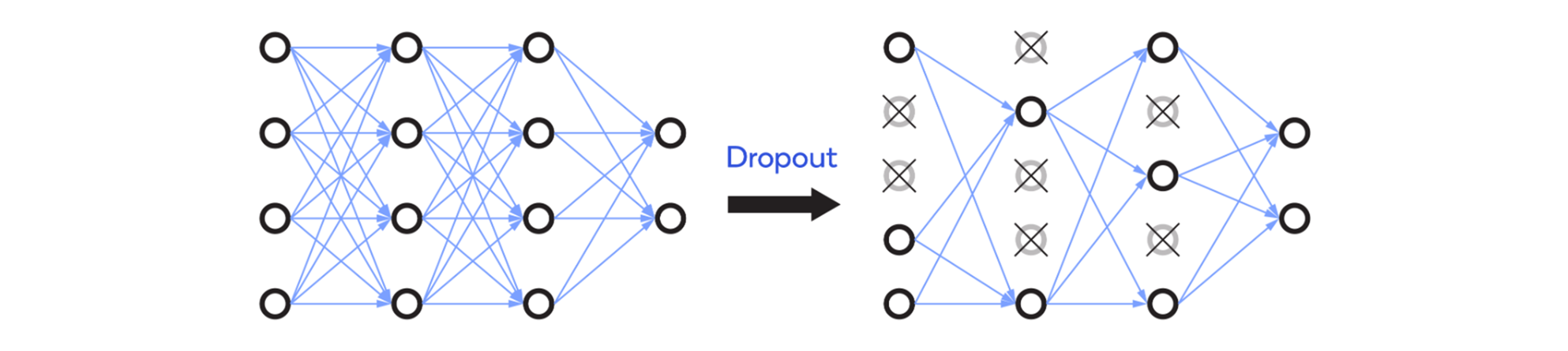
AlexNet uses ReL as the activation functionU(Rectified Linear Unit) is used. ReLUis used instead of the traditional sigmoid and tanh functions to introduce nonlinearity into the network. ReLUCompared to conventional activation functions, is more responsive to positive values and less responsive to negative values, so not all neurons are always activated. Also, ReLUrequires less computation time than sigmoid or tanh. Also, ReLUAnother advantage of is the ability to drop inactive neurons as shown below, allowing the developer to set the rate at which inactive neurons are dropped out. Dropout helps avoid overfitting of AlexNet.
VGG-Net
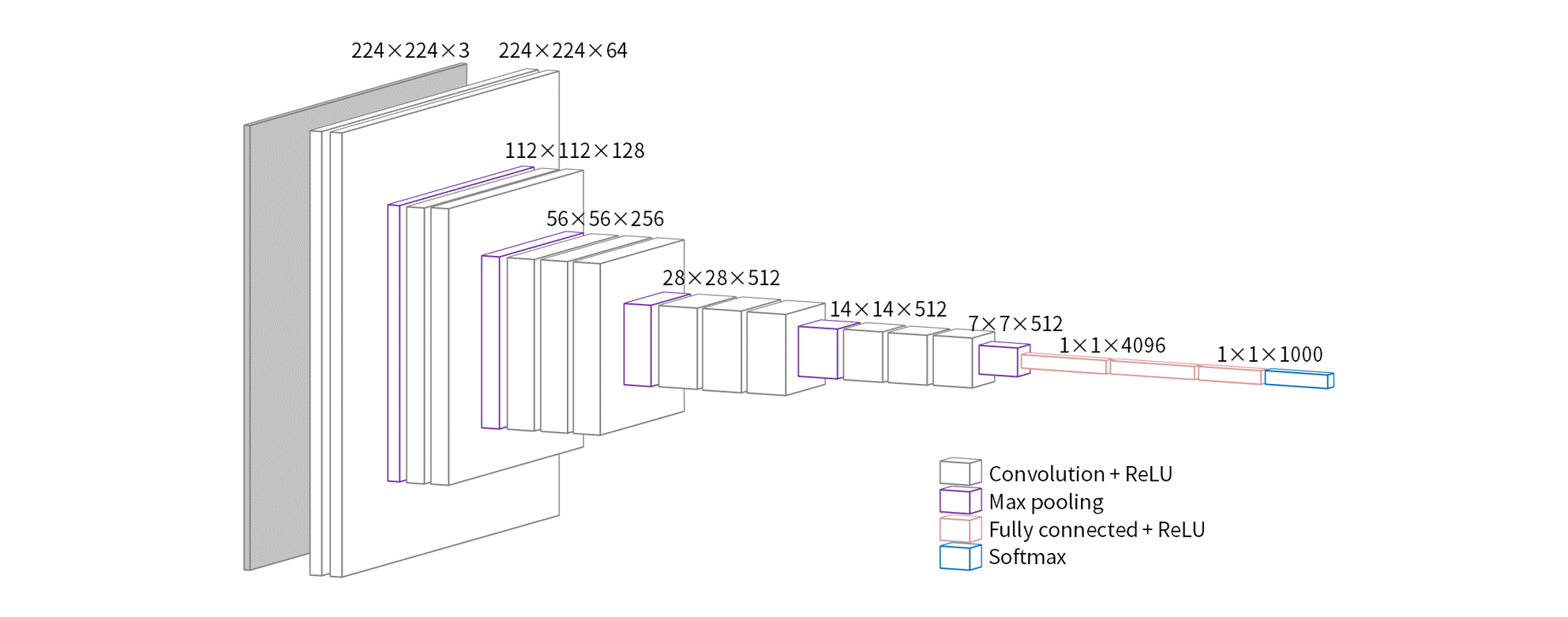
In VGG-NetAlexNetIt is a model in which further research has been conducted on the relationship between network depth and accuracy by increasing the number of layers.VGG-NetThe most important feature of the convolutional layer is3×3small filters connected in series. The configuration is a very simple network, and while reducing the number of parameters, by deepening the layersAlexNetWe have been able to achieve accuracy that surpasses that of especiallyVGG19,VGG16called19layer,16layersVGG-Netwas well known and considered the optimal number of layers in this network configuration.
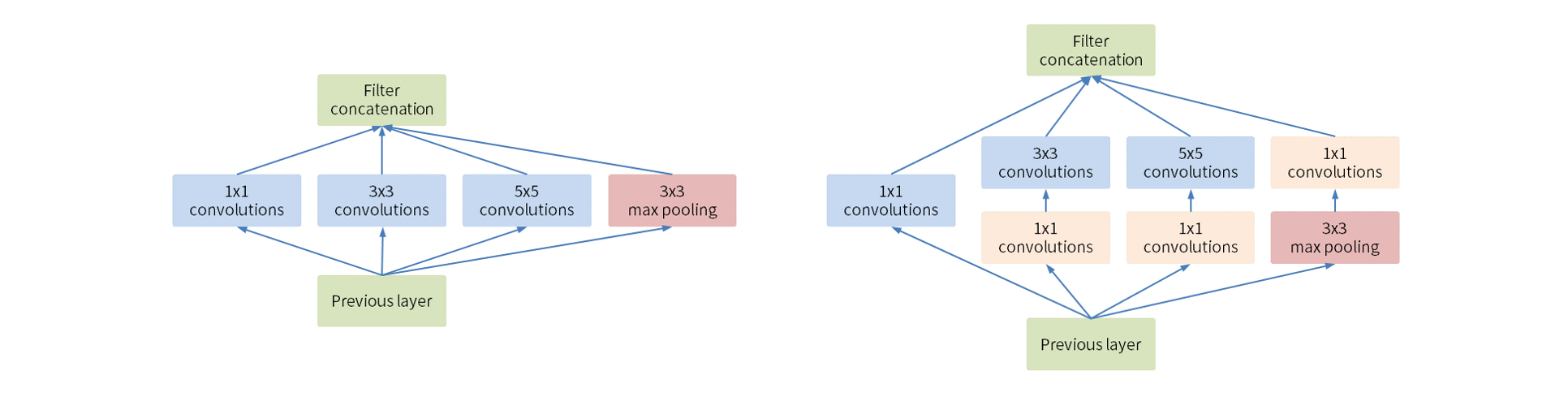
GoogLeNet Inception
In GoogleNet Inception, multiple size filters are applied at the same level along with 1×1 convolution. Considering practical examples of image recognition, the input image does not always have the same layout, so it is not always possible to use the same size filter when detecting objects. For example, if you want to do object detection and feature extraction on the dog image below, you should use a large filter on the left image and a small filter on the right image.

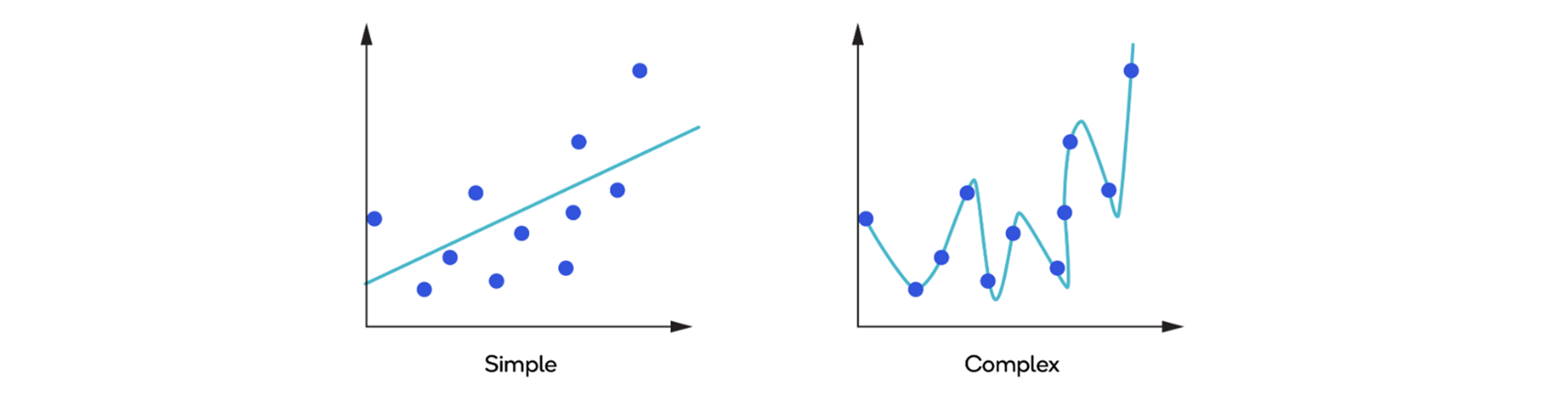
GoogleNet Inception helps avoid overfitting by increasing the width of the model relative to the depth. As the depth of the model increases and more features can be captured, the activation function overfits the training data and becomes difficult to use universally. The images below show a generic model (simple model) and an overfitted model (complex model).
In GoogleNet Inception, as mentioned in the dog example above, the background and layout of the images used for feature extraction and object detection are different, so different size filters are applied to one input. . By using multiple size filters at the same level, you can easily detect different size objects in different images.
By convolving the input with a 1x1 matrix before applying the filter, we can reduce the number of computations done on the image. For example, convolving a filter of size 5x5x48 with an input of size 14x14x480 requires (14x14x48)x(5x5x480) = 112.9 million computations. . But after convolving with 1×1Five×Five, the total amount of computation is (14×14×16)×(1×1×480)=1.5 million and (14×14×48)×(5×5×16)=3.8 million530It can be reduced up to 10,000 times. After branching the network with the Inception module and performing convolution with different sizes, we are processing to connect those outputs.
ResNet
As neural networks get deeper, they start to see a problem called "vanishing gradient" where the gradient of the loss function progresses towards zero. ResNet(Residual Network)implements the suppression of vanishing gradients by incorporating the idea of shortcut connections in the network. Blocks with shortcut connections are called residual blocks.(Residual Block)By connecting these residual blocks, we build a deep network. The residual block includes the baseline residual block (The figure belowleft)and the bottleneck residual block (The figure belowright)There are two types of
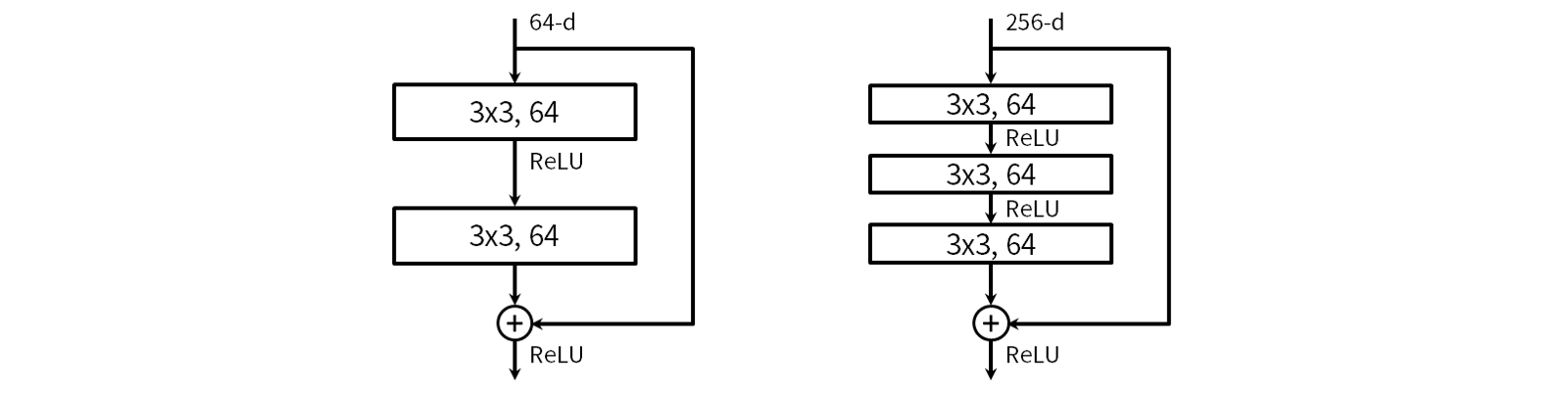
ResNetThere are several types depending on the total number of convolution layers,34layersResNet-34is the baseline residual unit,50/101/152layersResNet-50/ResNet-101/ResNet-152uses the bottleneck residual unit. The baseline residual unit consists of two 3x3 convolutions, batch normalization, and ReLU. The bottleneck residual unit is a series of 1×1, 3×3, 1×1 convolution operations stacked three times, with two 1×1 operations aimed at dimensionality reduction and restoration, preserving accuracy. while enabling computational efficiency. Batch normalization and ReLU are applied after each convolution.
The figure below shows a 34-layerResNet-34architecture.

Qualcomm Snapdragon related products suitable for AI implementation
Edge AI Computing Box (EB Series)


Inquiry/Quotation
If you have any questions or would like more product information, please contact us here.