- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2144件がヒットしています。check

[NVIDIA x NXPで実現するエッジAI]
第1話 プロセス概要
第2話 データセットの作成(NVIDIA Omniverse)
第3話 AIモデルの学習(NVIDIA TAO Toolkit)
第4話 エッジデバイスへのデプロイと推論(i.MX 8M Plus EVK)

前回の第3話では、合成データを使用してTAO Toolkitによる転移学習を実行し、人形を検出するAIモデルを作成しました。
第4話では、そのAIモデルをエッジデバイスであるi.MX 8M Plus EVKにデプロイする手順を紹介します。TAO ToolkitはONNX形式でモデルを出力できるため、さまざまなエッジデバイス向けにモデルを変換することが可能です。
今回はNXP社のデバイスに焦点を当てて説明しますが、他のエッジデバイスにも応用が可能ですので、参考になれば幸いです。
モデル変換の概要
今回は、TAO Toolkitで作成したONNXモデルをTensorFlow Liteに変換していきます。NXP社のi.MX 8M PlusのNPUはさまざまなモデルに対応していますが、他のデバイスでも幅広く対応しているTensorFlow Liteを選びました。

エッジデバイス向けのモデル変換
エッジデバイス向けのモデル変換は、単にモデルの拡張子を変更するだけではなく、そのデバイスのアクセラレーター(NPUやGPU、DSPなど)で処理できるように変更を加えたり、量子化を行ったりします。NVIDIA社ではTensorRTと呼ばれる最適化が有名ですが、これはNVIDIA GPUに最適な形で動くようにモデルを変換し、処理を高速化させるものです。一般的に変換(最適化)前のモデルを学習モデル、変換後のモデルを推論モデルと呼び、推論モデルは余分な処理を減らしているため、高速化が見込めます。
参考:[ディープラーニング推論の高速化術] 第1話 NVIDIA TensorRTの概要
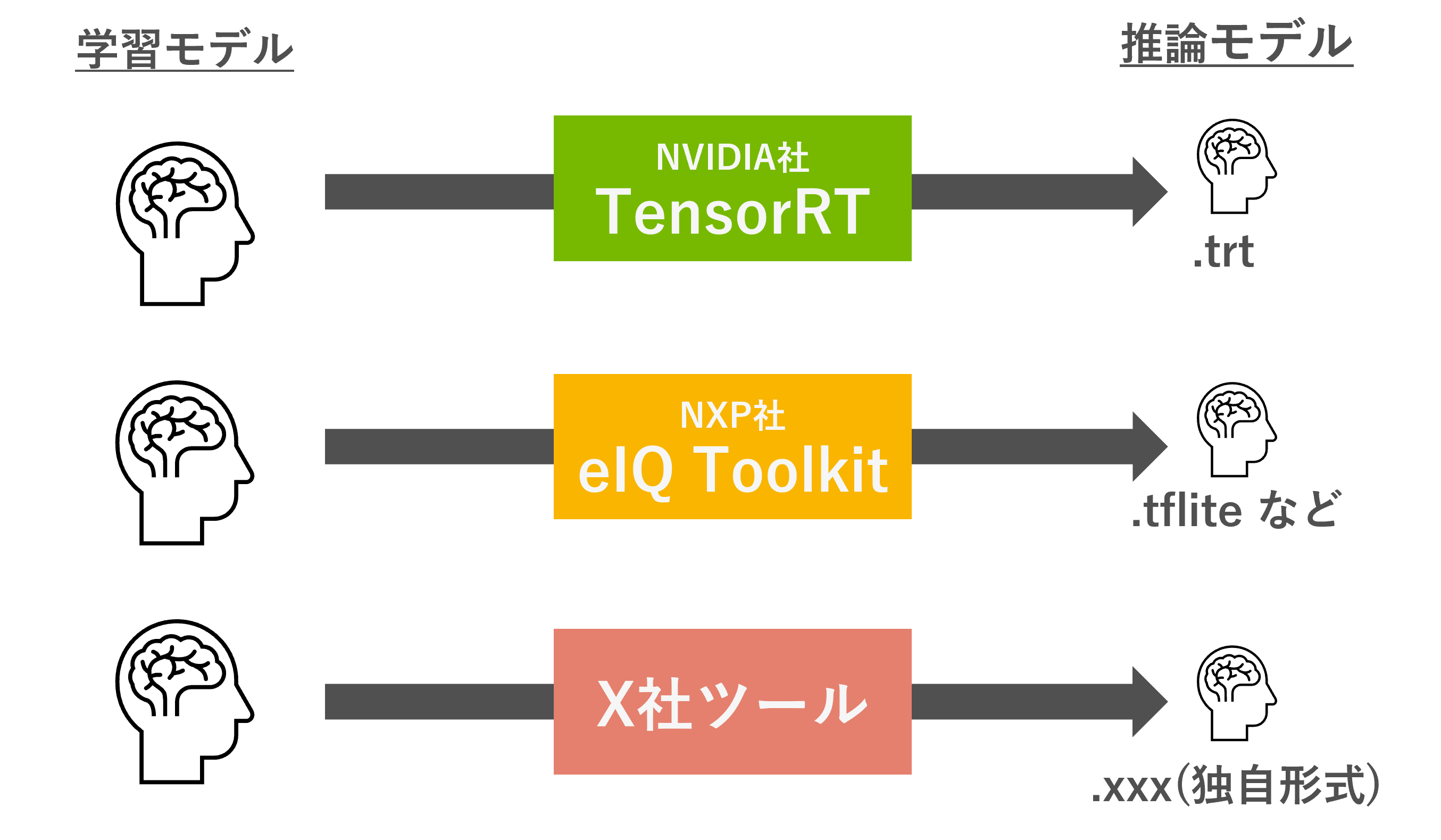
エッジデバイスを作っている会社は、各社それぞれが変換・最適化ツールを提供しています。NXP社の場合は、eIQ®Toolkitを提供しており、TensorFlow LiteやArm NN、ONNXランタイムで動くようにモデルを変換することができます。ツールごとに対応しているオペレーターが異なるため、自分の用意したモデルが変換できるかは、各社のドキュメントを見て確認しましょう。
モデル変換の流れ (i.MX 8M Plus編)
今回使用するNXP社のi.MX 8M Plusは、TensorFlow Liteに対応しているため、.tflite形式にモデルを変換します。モデル変換の手法は主に2種類あり、ベンダー専用のツール(eIQ®Toolkit)を利用する方法と、オープンソースのツールを利用する方法があります。
ベンダー専用ツールを使用する方法 (eIQ®Toolkit)
NXP社の提供するeIQ Toolkitは、機械学習モデルの開発と展開を支援するための強力なツールセットです。推論エンジン(推論モデル)への変換だけでなく、モデルの開発、プロファイリング機能、データセット管理などの機能が含まれています。
個人的にはかなり使いやすく、UIを使った操作ができる&Netronライクにモデル構造を確認できるため、非常に便利です。UIを操作して推論エンジンに変換した後、モデル構造に無駄が無いか、視覚的に確認することができます。
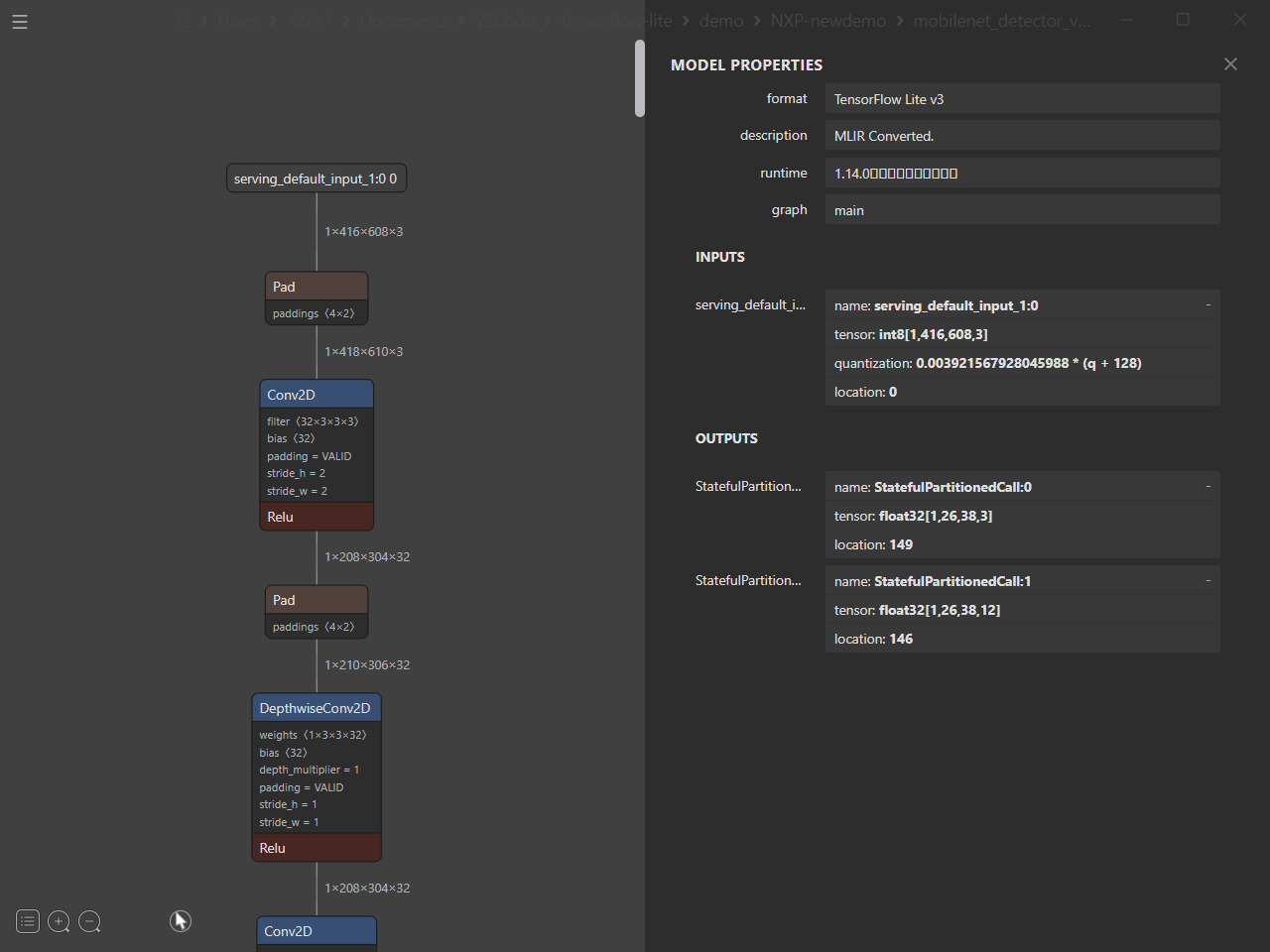
非常に便利なツールなのですが、NCHW形式のモデルをNHWC形式(TensorFlow)に変換する場合、無駄なレイヤーが挿入されてしまいます。
(参考:Deploy PyTorch Models to NXP Supported Inference Engines Using ONNX)
そこで今回はフリーで公開されている変換ツールを使用しました。
フリーの変換ツールを使用する方法
TensorFlow Liteは有名なフレームワークのため、様々な変換方法が用意されています。今回はGitHubで公開されている変換ツールを使用して、TensorFlow Liteのモデルに変換しました。ONNX(NCHW形式)からTensorFlow(NHWC形式)への直接変換には問題があるため、遠回りのアプローチを取っています。無駄なレイヤーが挿入されない分、高速化に繋がるため、NCHW形式のモデルを変換する際はこちらの方法がおススメです。(具体的なコマンドは今回説明しませんが、後日別の記事で公開予定です)

長い道のりですが、かなりの効果が期待できます。実際にResNet-34ベースのモデルを変換した際、eIQ Toolkitで変換するよりも、推論時間を1/10まで短縮することができました。
TensorFlow Lite モデルの処理をNPUにオフロードする
TensorFlow Liteのモデルを作ることができれば、デプロイは非常に簡単です。TensorFlow Liteのデリゲート機能を使用するだけで、簡単にCPUの処理をNPUにオフロードできます。まずCPUで動くアプリケーションを作成した後、ソースコードをたった2行変更するだけです。非常に楽なので苦労することはありません。
delegate = tflite.load_delegate("/usr/lib/libvx_delegate.so")
interpreter = tflite.Interpreter(model_path=model_path, experimental_delegates=[delegate], num_threads=4)モデル変換・デプロイの注意点
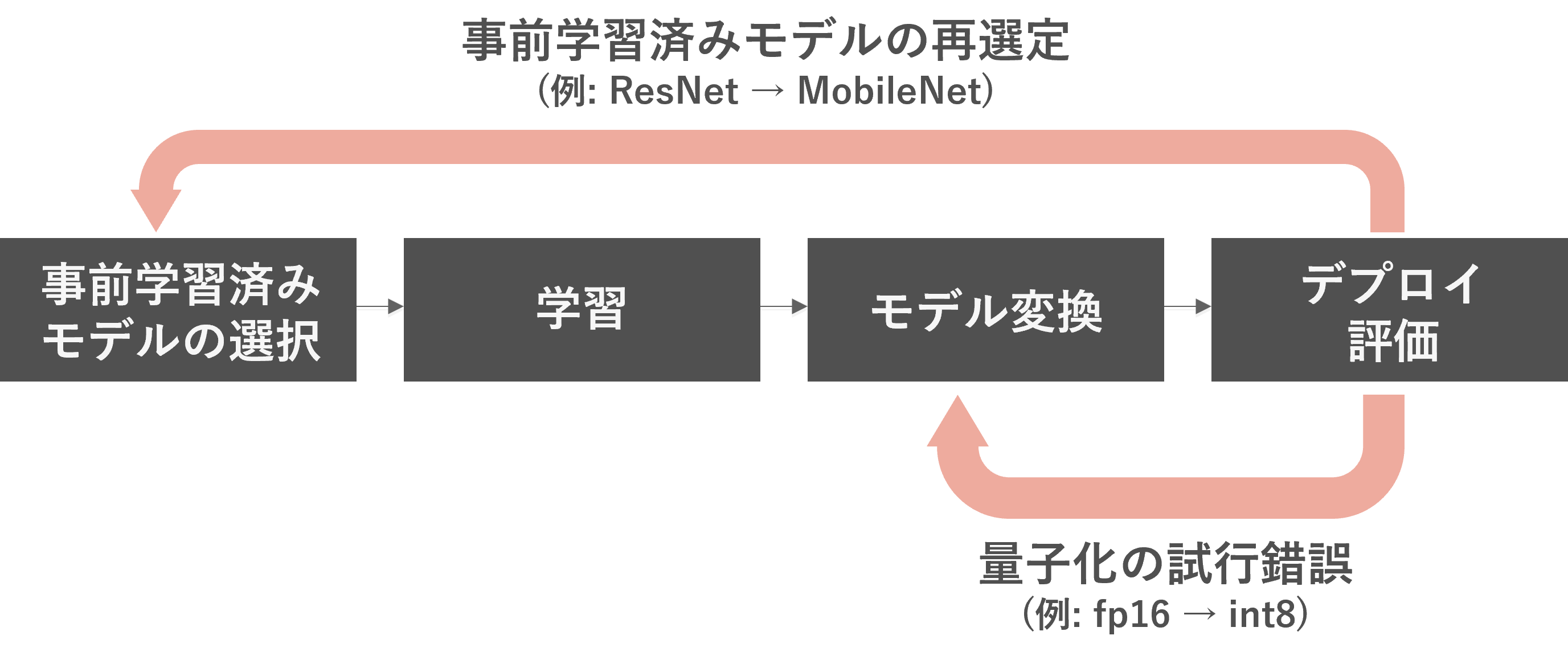
推論モデルへの変換は、トラブルがつきもので、使用するモデルアーキテクチャーやエッジデバイスに合わせたモデル変換が必要になります。量子化しすぎて精度が出ない、変換ツールが対応していないオペレーターがモデルに含まれている、ということはよくあることです。最適化の試行錯誤や、エッジデバイスに合ったモデルアーキテクチャーを選択しましょう。
(例1)精度を保ちながらモデルを使用したいため、fp32のモデルをfp16に変換して使用していたが、処理速度が足りない。そのためint8に変換してトライする。
(例2)ResNetベースのモデルを使用していたが、処理速度が足りない。MobileNetベースのモデルを再度転移学習させてみる。
エッジAIを実現!
本記事では、モデルの作成からエッジAIの実現までの流れを説明しました。NVIDIA Omniverseのプラットフォームを活用することで、実際の現場で撮影することなく、データセットをフォトリアルな仮想空間内で自動生成し、それをAIモデルの作成に活用しました。AIモデルを作成した後は、できあがったONNXモデルをTensorFlow Lite形式に変換し、エッジデバイス(i.MX 8M Plus EVK)にデプロイしました。デリゲート機能を用いることで、非常に簡単にNPU(AIアクセラレーター)にオフロードすることができました。
是非本記事を参考に一連のフローをお試しいただければ幸いです。
OmniverseやTAO Toolkit、エッジAIをご検討の方は、ぜひお問い合わせください


関連する情報


