- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2144件がヒットしています。check

[NVIDIA x NXPで実現するエッジAI]
第1話 プロセス概要
第2話 データセットの作成(NVIDIA Omniverse)
第3話 AIモデルの学習(NVIDIA TAO Toolkit)
第4話 エッジデバイスへのデプロイと推論(i.MX 8M Plus EVK)
前回第2話ではOmniverse™ Replicatorによる合成データ作成の流れを紹介しました。
第3話では第2話で作成した合成データを使用してTAO Toolkitによる転移学習を実行し、人形を検出するAIモデルを作成していきます。

NVIDIA TAO Toolkit GPU環境の構築
TAO Toolkitを用いた学習をおこなうためには、事前にGPU環境の構築が必要となります。環境構築についての詳細は以下のリンクから確認できます。
環境構築が完了するとコマンドライン上でTAO Toolkitが実行できるようになります。
以下のコマンドで正しく環境構築が完了しているか確認します。
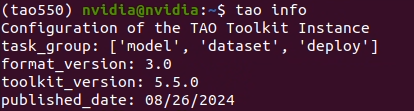
本記事では上記の通り、version 5.5.0で実行しています。
学習データセットの準備
データフォーマット変換
次に学習に必要なデータセットを準備します。
学習に必要なデータは既にOmniverse Replicatorで作成していますが、出力された合成データをTAO Toolkitで学習可能なデータフォーマットに変換する必要があります。
Omniverse Replicatorで出力されたzipファイルを解凍するとpng, npy, jsonの3種類のデータが格納されていることがわかります。
それぞれ以下の内容のファイルになっています。
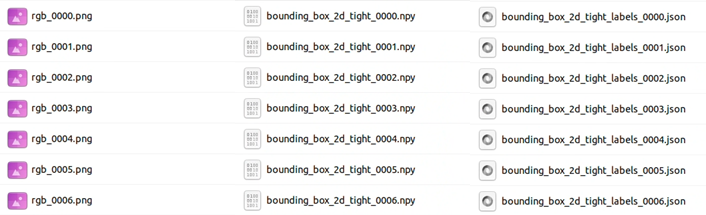
・png: 合成されたRGB画像データ
・npy: 合成画像内アセットの位置を示すBounding Boxデータ
・json: 合成画像内アセットの内容を示すClassデータ
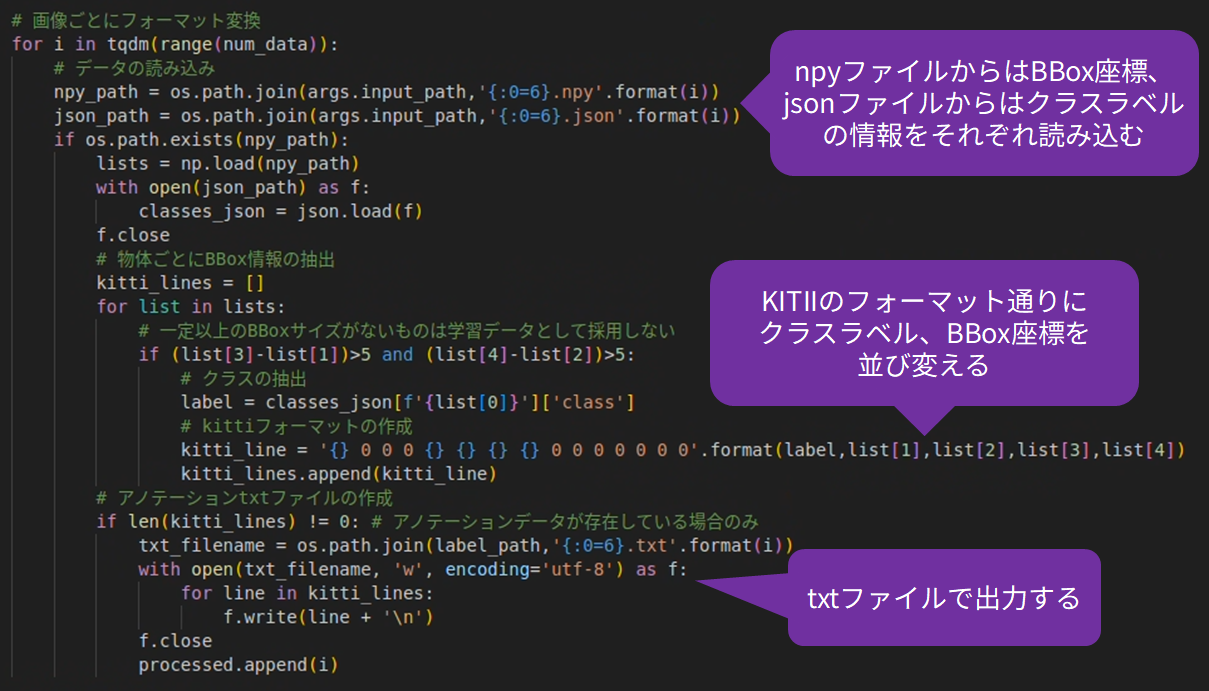
これらのデータをTAO Toolkitで学習するためにKITTIフォーマットというデータフォーマットに変換します。
KITTIフォーマットとはClassデータ、Bounding Boxデータを含むアノテーション情報を、以下のように画像ごとのtxtファイルで出力するデータフォーマットのことです。

それではnpyファイルおよびjsonファイルから必要な情報を抽出してKITTIフォーマットに変換していきます。
変換にはPythonスクリプトを使用します。
以上の処理が完了すると以下のようにデータセットが整理されます。
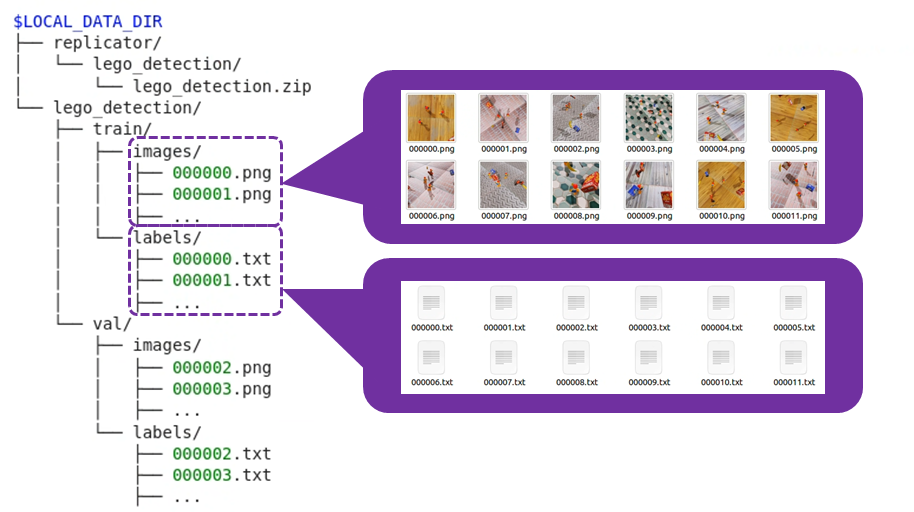
整理されたデータの数を確認してみます。
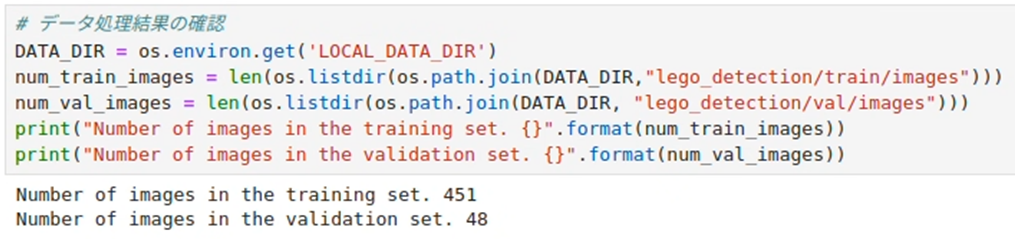
このままでも学習の実行は可能ですが、少々データ数が少ないため、次にデータ拡張(Data Augmentation)という処理をおこなっていきます。
データ拡張
データ拡張とは、学習データの環境条件を変更することによって学習データを水増しする手法です。
データ拡張は学習データ数が十分に確保できていない場合に有効な手法で、Data Augmentationとも呼ばれます。
このデータ拡張は、Pythonのライブラリ等を駆使して行われるのが一般的ですが、TAO Toolkitにはデータ拡張をおこなう機能が備わっているため、学習と同様にコマンド1つで簡単にデータ拡張を実行できます。
NVIDIA TAO Toolkitによるデータ拡張は以下のspecファイルの内容に基づいておこなわれます。
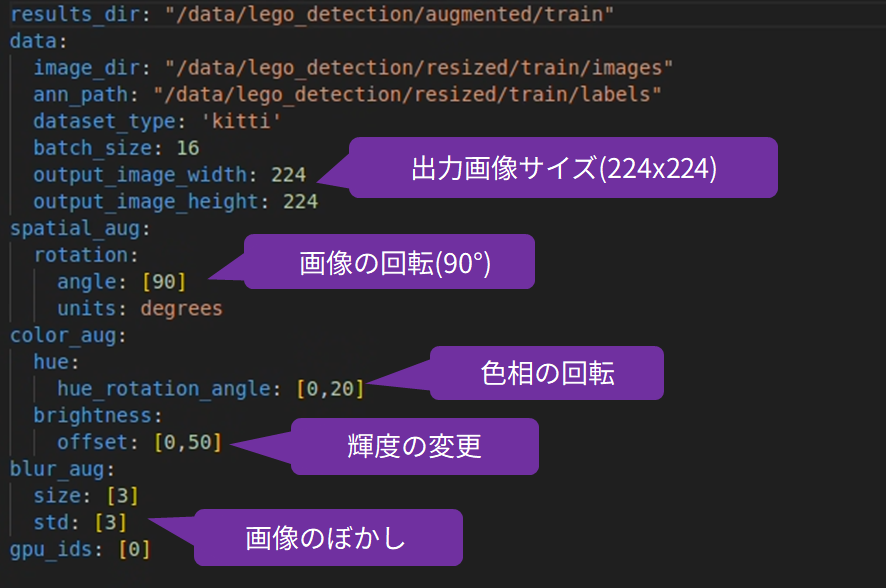
この内容では画像の90度回転、0~20度の色相回転、画像ぼかし、輝度変更が実行されます。
以下のコマンドでデータ拡張がおこなわれます。

データ拡張を行った後の画像とBounding Boxを確認してみます。
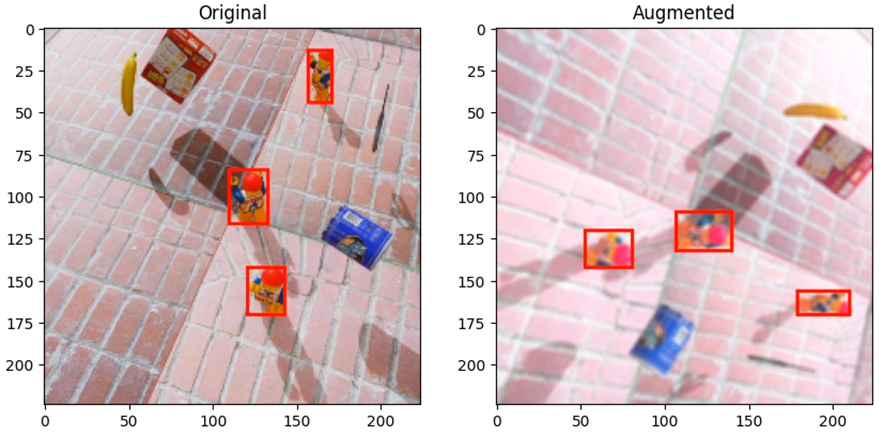
元の画像と似てはいますが、異なる画像になっていることが確認できます。
このようにデータ拡張をおこなうことで、学習に使用するデータを水増しすることができます。
以上でデータセットの準備が完了しました。
事前学習済みモデルの準備
TAO Toolkitで転移学習をおこなうための事前学習済みモデルをダウンロードします。
TAO Toolkitで使用できる事前学習済みモデルはNVIDIA社が多数公開しており、コマンド1つで簡単にダウンロードが可能です。
今回は高速で実行することを重視してmobilenet_v2を事前学習済みモデルとして使用します。
以下のコマンドを実行して事前学習済みモデルをダウンロードします。

TAO Toolkitによる転移学習
転移学習の実行
これまでに準備してきたデータセット、事前学習済みモデルを使用してTAO Toolkitによる転移学習をおこないます。
以下のspecファイルの内容に基づいて転移学習が実行されます。エポック数やバッチサイズ等の学習に関わる設定はこのspecファイルを編集することで変更できます。
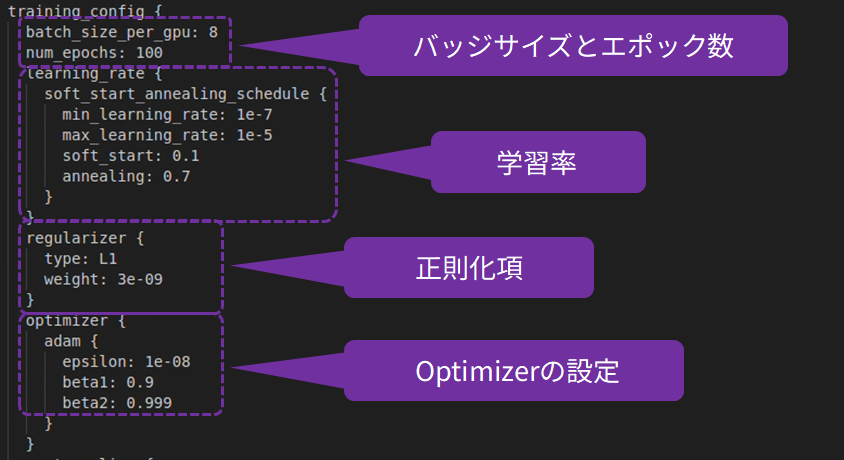
以下のコマンドを実行すると転移学習が実行されます。

学習が完了すると、学習済みモデルが出力されます。
推論の実行
学習が完了したら推論結果を確認してみます。

AIモデルが期待通りに人形を検出できているため、学習を終了します。
推論モデルの出力
学習が完了したAIモデルを推論モデルに変換し、onnx形式で出力します。

指定した場所にonnx形式のAIモデルが出力されています。
第4話ではAIモデルをデバイスにデプロイする手順を解説
今回の第3話ではNVIDIA TAO Toolkによる転移学習をおこなって、人形を検出するAIモデルを作成する流れについて紹介しました。
AIモデルをonnx形式で出力することによって、様々なエッジデバイスでAIアプリケーションを開発することが可能になっています。
次回第4話では今回作成したAIモデルをNXP社のi.MX 8M Plus EVKにデプロイし、リアルタイム推論を行うアプリケーションを作成してきます。
OmniverseやTAO Toolkit、エッジAIをご検討の方は、ぜひお問い合わせください


