- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2181件がヒットしています。check
![[NVIDIA TAO Toolkitによる物体検出AI開発] 第1話:NVIDIA TAO Toolkitとは](/business/semiconductor/articles/136593_header.jpg)
AI(Artificial Intelligence:人工知能)とは人間の知的な振る舞いをコンピューターに実行させる技術のことです。現在でも物体検出や画像生成、自然言語処理などのさまざまな応用例が研究されており、私達の身の回りでもお掃除ロボットや翻訳ツールなどに活用されています。そのなかでも物体検出は話題性のある研究課題として開発が進んだ結果、さまざまな業種で幅広く利用されるようになりました。
最近ではAIを開発するためのSDK(Software Development Kit)を使用することで、自身でAIの開発を行うことができるようになっています。現在多くのSDKが提供されており、なかにはチュートリアルが付属しているものもあるため、簡単なAIであればディープラーニングに深い知見がなくても開発をおこなうことができます。
しかし、応用的なAIの開発をおこなう場合には膨大なAIの開発用のデータセットを独自で作成したり、適切なディープラーニングの設定を行うなどのAIの開発に関する専門知識が必要になります。この専門知識が不足しているために、独自のAI開発が思うように進まないというお声を多くいただきます。
NVIDIA社が提供しているNVIDIA TAO Toolkitは、転移学習という技術を使用することでデータセット作成の労力やAIの学習時間を削減することを可能にしています。また、さまざまなAIのユースケースに合わせた開発ワークフローが提供されているため、自身で一からのプログラミングを行う必要がなく、ディープラーニングに深い知見がない場合でも幅広いAIの開発をおこなうことができます。
本記事ではその一例として、NVIDIA TAO Toolkitを使用したAIを開発する流れについて紹介します。本記事がみなさんのAI開発の一助となりますと幸いです。
[NVIDIA TAO Toolkitによる物体検出AI開発]
第1話:NVIDIA TAO Toolkitとは
第2話:転移学習の準備
第3話:転移学習の実行、推論モデルの作成
NVIDIA TAO Toolkitとは
NVIDIA TAO Toolkitとは、転移学習を用いたローコードのAI開発ツールです。
NVIDIA TAO Toolkitでは、転移学習を用いることによって一般的なディープラーニングと比較して短い時間、少ないデータ数でAIの学習を行うことができます。また、AIの開発に使用するTensorFlowやPytorchなどのフレームワークをローコードで使用できるようになっているため、NVIDIA TAO Toolkitの操作に求められるプログラミングのスキルは最低限であり、幅広いAIの開発ワークフローが提供されているため、AIの開発に関する専門知識がなくてもAIの開発をおこなうことができます。
ここで、NVIDIA TAO Toolkitを使用したAI開発のワークフロー例を紹介します。
① データ拡張:少数のデータを拡張してデータ数を確保する。
② 事前学習済みモデル:NVIDIA社が提供している事前学習済みモデルをダウンロードする。
③ 転移学習:事前学習済みモデルを用いて効率よく学習する。
④ 枝刈り:推論処理の高速化のためにモデルの規模を縮小させる。
⑤ 再学習:再度学習を実行し、縮小されたモデルの精度を回復させる。
⑥ デプロイ:実行するプラットフォームに最適化させた推論モデルを展開する。
上記フローのうち、①データ拡張、②事前学習済みモデルについて後ほど紹介します。③以降の作業については第2話以降で紹介しますので、興味がある方は読み進めていただければ幸いです。
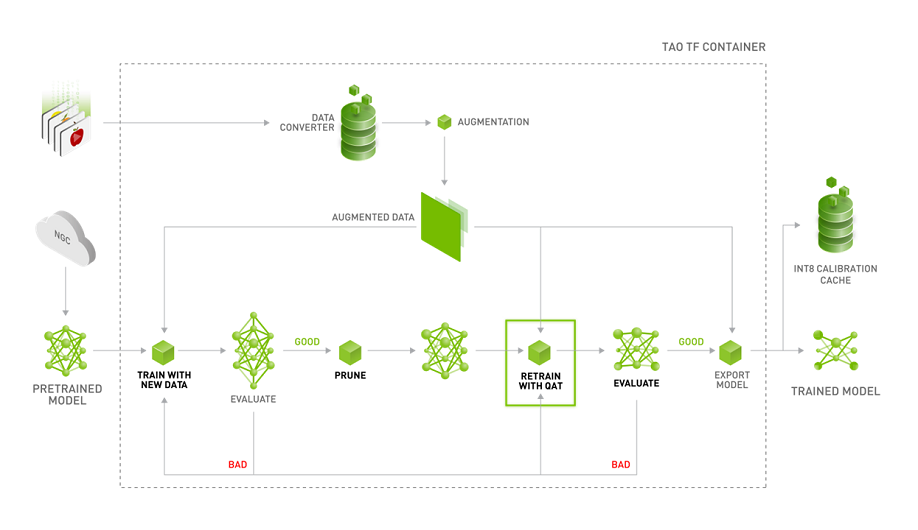
出典: NVIDIA
NVIDIA TAO Toolkitでは物体検出、画像分類、セグメンテーションなどの多様なユースケースに対応したワークフローを提供しています。どのワークフローを選んでも高度なAIの開発をおこなうことができますが、今回は物体検出AIの開発をおこなっていきます。
転移学習とは
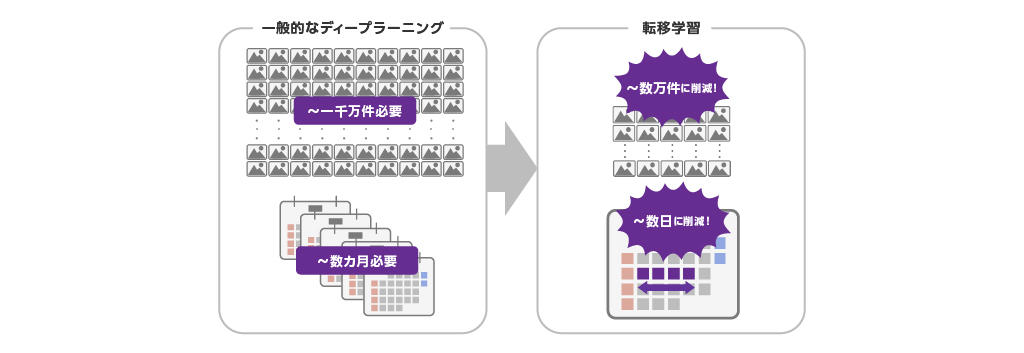
転移学習とは、ある目的で学習したAIモデルの知識を別の目的で学習されるAIモデルに転用する学習方法で、学習に使用できるデータが少ない場合や学習に必要な時間を短縮したい場合に有効な手法です。
一般的なディープラーニングは、学習データを通してAIモデルが持っているパラメーター値をより適した値に更新するというプロセスを膨大な回数繰り返すことで最適なAIモデルのパラメーター値を計算し、期待する推論結果を出力するAIモデルを作成しています。このAIモデルが持つ最適なパラメーター値を計算するプロセスを「学習する」と呼びます。
この学習に必要なデータ数は人間に近いレベルの性能を達成させようとすると1,000万件程度、最低限の性能を達成するのにも1ラベルあたり5,000件と言われています。学習に必要な時間についてはAIモデルの複雑さによって幅はありますが、数週間から数カ月と言われています。
対して転移学習では、事前学習済みモデルと呼ばれる既に何らかの学習が行われているAIモデルのパラメーター値を、これから作成するAIモデルに転用して学習を行います。AIモデルの初期状態よりも学習が進んだ状態から学習を開始できるため、最適なAIモデルのパラメーター値を計算するまでの時間や必要な学習データの数を削減することができます。
具体的には、全体で1,000件単位のデータ数でも最低限の性能を達成でき、10万件もあればかなり高性能なAIモデル作成が期待できます。学習に必要な時間も数時間から数日程度と、一般的なディープラーニングと比較して大きく削減することができます。
もし転移学習を行いたい時にこれらのデータ数も確保できない場合でも、後に紹介するデータ拡張という手法を用いれば十分なデータ数を確保できる可能性があります。
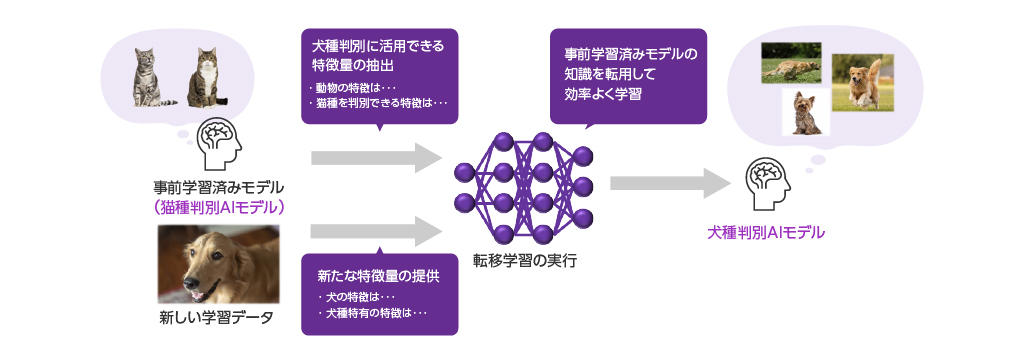
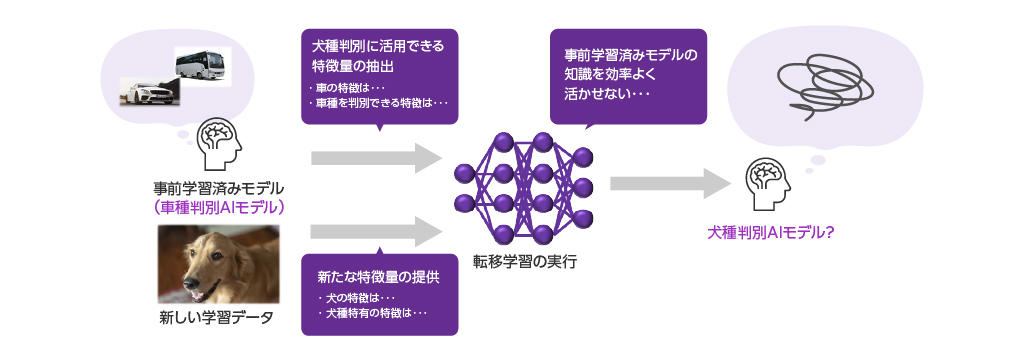
転移学習の具体例として、犬の種類を識別するAIモデルを開発する場合に、猫の種類を識別する学習済みモデルを活用するといった例が考えられます。
顔の形、4本足の形状などの動物に共通した特徴や、猫の種類を判別できる特徴といった知識を応用でき、追加で犬の種種類を判別するのに必要な犬特有の特徴を学習することで、モデルの初期状態から学習を始めるよりも必要なデータ数や学習時間を削減することができます。
ただし転移学習を行う場合には注意が必要で、利用する事前学習済みモデルで学習した内容が開発したいAIモデルの目的とかけ離れてしまっていると、かえって学習効率が悪化してしまう可能性があります。
今度は犬の種類を識別するAIモデルを開発する場合に、車の種類を識別する事前学習済みモデルを活用する例を考えてみます。
先ほどの例と同様に車の種類を識別するのに必要な特徴を活用して学習しようとしますが、そもそも車の特徴と犬の特徴が大きく異なるために事前学習済みモデルがもともと持っていた知識はむしろ邪魔になり、最終的な目標である犬の種類を識別する特徴の学習が難しくなってしまいます。
そのため、事前学習済みモデルを選択する場合には、転用する知識が目的に適したものであるか検討する必要があります。
データ拡張とは
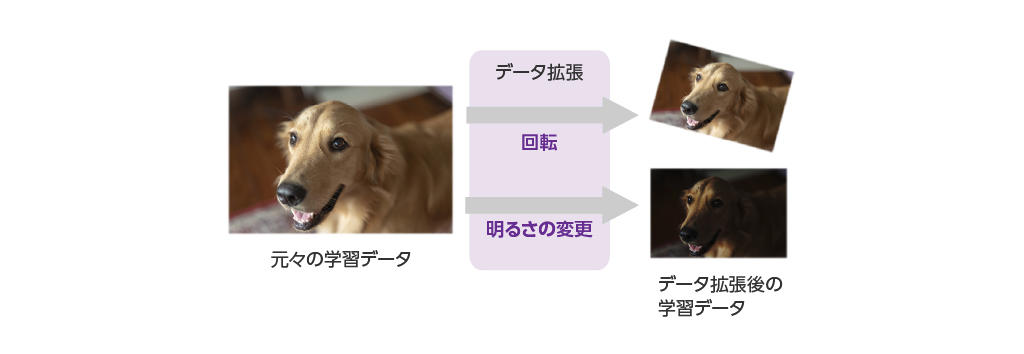
データ拡張とは、学習データの環境条件を変更することによって学習データを水増しする手法です。データ拡張は学習データ数が十分に確保できていない場合に有効な手法で、Data Augmentationとも呼ばれます。
ディープラーニングでは入力したデータに対する出力結果と正解ラベルを比較することで学習をおこないます。そのため学習が完了したAIモデルは、学習時に使用されたデータと類似したものは正しい推論結果を導けます。しかし一方で、学習時に使用されたデータ類似していないものに対しては正しい推論結果を導けない可能性があります。
AIモデルにおいて、この学習したデータと類似しているかどうかという基準は非常にシビアです。
例えばもともとが同じ画像データでも回転したり色合いや明るさが異なるだけで、AIモデルは全く違う画像データと認識して推論を行います。人間が学習する場合は同じものでも多様な環境条件(角度や明るさなど)を自然と経験して学習していますが、ディープラーニングではこのような多様な環境条件の入力データはそれぞれ学習時に準備する必要があります。
そのためディープラーニングでは多くの学習データを準備することが求められますが、十分な規模の学習データが常に準備できるとは限りません。
そこで、データ拡張を行うことで学習データの環境条件を変更することで足りないデータを補います。
NVIDIA TAO Toolkitではデータ拡張機能を使用することで、既存の学習データから回転、色合いなどのさまざまな環境条件のデータを自動的に生成し、多様な環境条件での学習が可能となります。
事前学習済みモデルとは
事前学習済みモデルとは、既に何らかの学習が完了しているAIモデルで、転移学習において目的のAIモデルに学習済みの知識を転用させるためのAIモデルのことです。
事前学習済みモデルを使用することで、準備できる学習データの規模が小さい場合や学習のための時間が少ない場合でも高性能なAIを開発することができます。
NVIDIA社はNVIDIA TAO Toolkitで使用できる事前学習済みモデルを多数公開しています。NVIDIA社が公開している事前学習済みモデルには大きく汎用モデルと専門モデルの2種類があります。
汎用モデルとはGoogle社が公開しているOpen Images Datasetを使って学習された事前学習済みモデルで、非常に幅広い分野の画像の学習が行われています。名前の通り汎用的な知識を持つモデルであるため、どのようなAIモデルを作成しようと考えたときでも一定の効果が期待できます。
専門モデルとは「人」や「車」などそれぞれ特定の分野に特化した画像のデータセットによって学習された事前学習済みモデルで、モデルが持つ知識も特定の分野に特化したものになります。先ほど紹介した通り、適切な事前学習済みモデルを選択すれば汎用モデルよりも高い効果が期待できます。
NVIDIA社が公開している専門モデルには以下のようなものがあります。物体検出やセグメンテーション、骨格推定などのさまざまなユースケースに対応しています。
|
Model |
Network Architecture |
Use cases |
|
DetectNet_v2-ResNet18 |
自動車の検出や追跡 など |
|
|
DetectNet_v2-ResNet34 |
人数カウント、人口密度ヒートマップの生成 など |
|
|
ResNet18 |
車種の分類 など |
|
|
UNET |
人周辺のセグメンテーションマスクの生成 など |
|
|
2D or 3D RGB-only Resnet18 |
人間の動作推定 など |
|
|
Four branch AlexNet based model |
視線推定 など |
出典:NVIDIA(一部抜粋)
NVIDIAが公開している事前学習済みモデルは、汎用モデル、専門モデルどちらもNVIDIA NGC Catalogからダウンロードして転移学習に使用できます。
NVIDIA NGC Catalogから事前学習済みモデルをダウンロードする方法については第2話で紹介しますので、興味がある方は読み進めていただければ幸いです。
NVIDIA TAO Toolkit 推奨ハードウェア
NVIDIA TAO Toolkitの学習では膨大なノードのネットワーク学習を行うため、以下のような大容量メモリーと高性能なGPUを搭載したハードウェア環境を準備することが推奨されています。詳細はこちらのリンクでご確認ください。

次回からNVIDIA TAO Toolkitを使ってAIモデルを作成していきます。
本記事ではNVIDIA TAO Toolkitとは何か、転移学習とは何かという部分や転移学習を行うメリット、注意するべき内容について紹介しました。
次回からはNVIDIA TAO Toolkitを用いた転移学習に必要な環境を構築し、データセットを準備するまでの流れについて紹介します。
興味を持っていただいた方は、以下のボタンから連載記事の続きをご覧いただけますと幸いです。ボタンをクリックすると簡単なフォーム入力画面へと遷移します。入力完了後に2話以降のURLがメールで通知されます。
AI導入をご検討の方は、ぜひお問い合わせください!
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際は、ぜひお問い合わせください。
※記事でご紹介した実行例は、今後のソフトウェア、ハードウェアのアップデートにより変更される可能性があります。
またサンプルプログラム、ソースコード上の細かなお問い合わせは、お受け致しかねます。あらかじめご了承ください。



![[AI画像解析アプリ開発に必要な知識] 第1話 NVIDIA DeepStream SDKとはのサムネイル画像](/business/semiconductor/articles/134117_thumb_r_11.png)