- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2168件がヒットしています。check

Introduction
When integrating generative AI into business operations, the design must encompass not only inference quality but also resilience to communication interruptions, continuous operation, and operational costs. In particular, systems that constantly handle video, audio, and logs often face challenges in terms of bandwidth, latency, and availability if they simply send all data to the cloud.
Up until now, edge computing has faced limitations such as "insufficient GPU memory to run large models, making inference at practical speeds difficult."
NVIDIA® Jetson Thor™ alleviates this limitation and expands the practical options for deploying multimodal generative AI in the field.
Furthermore, NVIDIA's Nemotron™ 3 Nano Omni is an attractive multimodal inference model that can handle text, images, audio, and video in a single model. This eliminates the need to combine multiple models, reducing the complexity of management and operation, and is likely to consume less GPU memory than when deploying multiple models.
Use cases for edge generation AI
The reason for wanting to use generative AI at the edge is not just low latency. In real-world operation, the following requirements arise simultaneously:

- We want to keep it running even at locations with unstable networks.
- We want to process the product in environments requiring high temperature, high vibration, and outdoor conditions.
- We want to process large amounts of data, such as camera and audio, 24/7, while keeping bandwidth and cloud costs down.
- We want to avoid the risk of cloud downtime or network outages and continue operation on-site.
As mentioned earlier, introducing generative AI at the edge presented challenges such as "insufficient GPU memory to run large models and difficulty in performing inference at practical speeds."
However, with Jetson Thor, this limitation has been significantly alleviated at a practical operational level thanks to improvements in GPU performance, software optimization, and NVFP4 support.
Jetson AI Lab
Jetson AI Lab provides a collection of model execution information for Jetson, allowing you to quickly check compatible models, deployment procedures, and benchmarks.
In addition to the NVIDIA Nemotron series, models such as NVIDIA Cosmos Reason, Google Gemma 4, OpenAI GPT-OSS, and Alibaba Qwen series have also been tested and confirmed to work with Jetson AI Lab, significantly reducing the time required to begin testing.
Furthermore, the document lists multiple inference server options, including vLLM, SGLang, llama.cpp, Ollama, and TensorRT Edge-LLM, which is helpful when considering combinations of models and inference servers.
Jetson AI Lab Models
Nemotron 3 Nano Omni
Nemotron 3 Nano Omni is an open, multimodal inference model that handles text, images, audio, and video in a single model. While many multimodal models can handle images and videos, its key feature is its ability to handle text, images, audio, and video in a single model.
30B-A3B Hybrid MoE Architecture
Input: Text / Image / Audio / Video
Output: Text
The Nemotron 3 Nano Omni's strength lies in its ability to integrate multimodal functionality into a single model, making it easier to achieve both efficiency and operability.
As the various benchmarks in the link below demonstrate, this model combines high accuracy and throughput, making it easier to design architectures that are less dependent on the cloud when combined with high-performance edge AI devices such as JetsonThor.
For more information about Nemotron 3 Nano Omni, please refer to the following URL.
Nemotron 3 Nano Omni on Hugging Face
NVIDIA Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning in a Single Efficient Open Model
MediaPerf Results for New NVIDIA Nemotron 3 Nano Omni Pushing the Efficiency Pareto Frontier
How to run Nemotron 3 Nano Omni on Jetson Thor
This time, I'll introduce how to build a server using vLLM, as presented in Jetson AI Lab.
We also publish instructions on how to set up Jetson, so we hope you find them helpful.
Jetson AGX Thor Developer Kit Introduction: From Quick Setup to Verifying AI Inference Functionality
First, run the following command in the terminal.
sudo docker run -it --rm \
--runtime=nvidia --network host \
-v $HOME/.cache/huggingface:/root/.cache/huggingface \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.20.0-ubuntu2404 \
-c "pip install -q 'vllm[audio]' && vllm serve nvidia/Nemotron-3-Nano-Omni-30B-
A3B-Reasoning-NVFP4 \
--trust-remote-code \
--gpu-memory-utilization 0.65 \
--max-model-len 32768 \
--reasoning-parser nemotron_v3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder"After that, wait for the vLLM server to start up and the model to load, as shown in the image below.

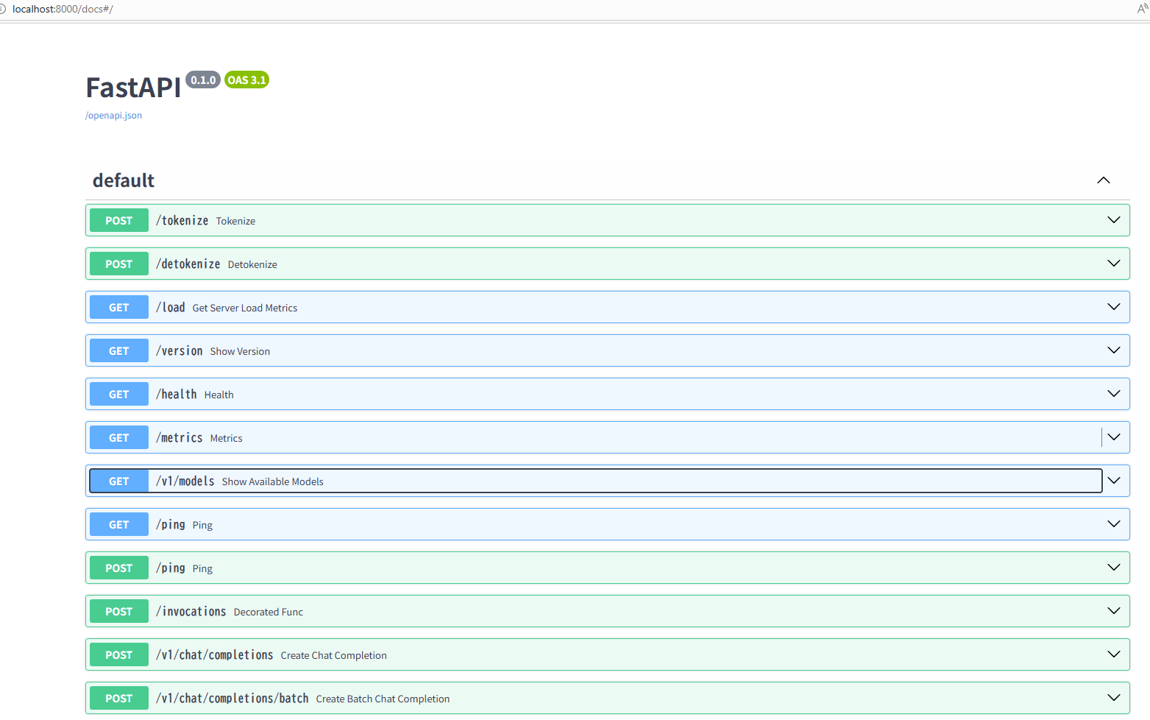
Once the model is loaded, the OpenAI-compatible API endpoint will be activated, as shown in the image below.

Accessing localhost:8000/docs will display the FastAPI documentation screen, allowing you to verify API connectivity.
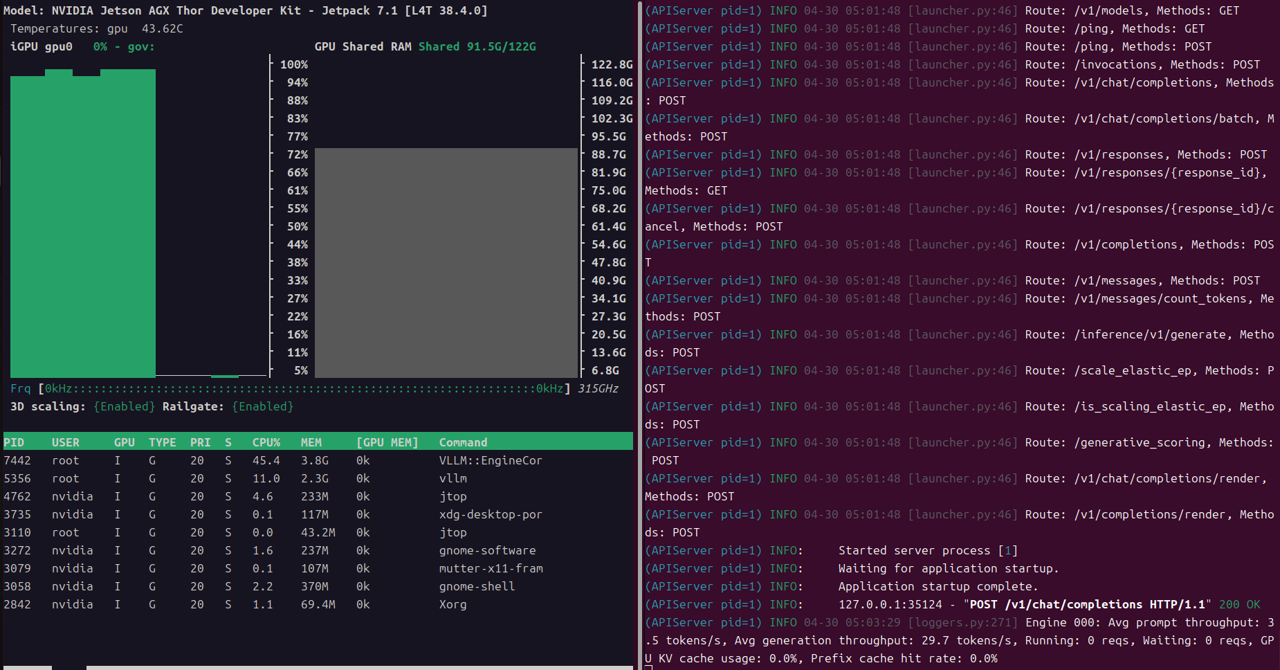
By checking GPU usage with tools like jtop and sending requests to the API, you can see that inference is being performed.
With just these few steps, you can run cutting-edge models on Jetson Thor, significantly reducing the time it takes to begin testing.
It's actually working.
The following is an example of the NVIDIA Nemotron 3 Nano Omni running on Jetson Thor. This time, referencing the Hugging Face example, I created a simple application for multimodal inference of text, images, audio, and video using Streamlit, a Python library.
If you are interested, please feel free to contact us.
Text Inference
This is an example where the inference result is returned on the UI in response to a Japanese prompt.
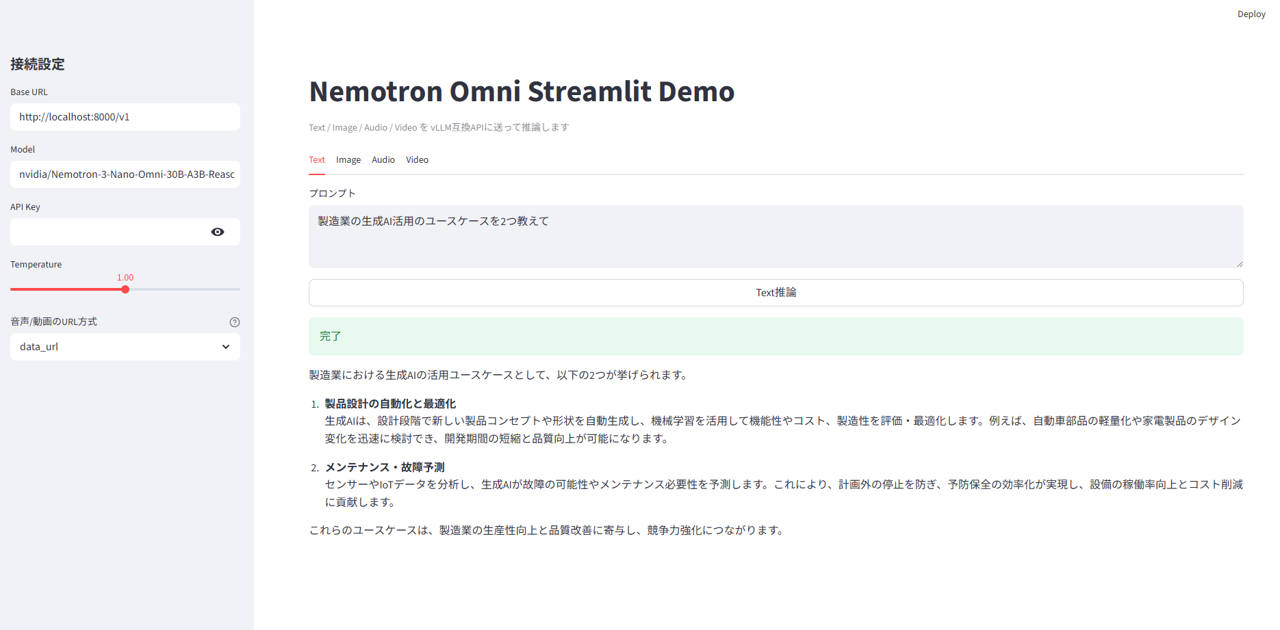
Image Inference
This is an example where a camera or uploaded image is used as input, and the subject and background can be described.

This image shows an area in a Japanese park where playground equipment is installed.
• Playground equipment: On the left side of the screen, there are two swings suspended from a blue frame, and below them is a small playground structure made from a red frame.
On the right side of the screen, there is a play structure that combines a red pillar, an arched railing, a yellow slide, and a blue staircase.
• Ground: Beneath the playground equipment is a safe area covered with gray sand and pebbles.
Background: Behind the playground equipment is a black metal fence and a small hill covered with green grass. Several trees are scattered on top of the hill.
Further in the distance, you can see buildings such as houses and apartments, with power lines and utility poles crossing the sky.
Weather: The sky is cloudy, and the light is rather dim.
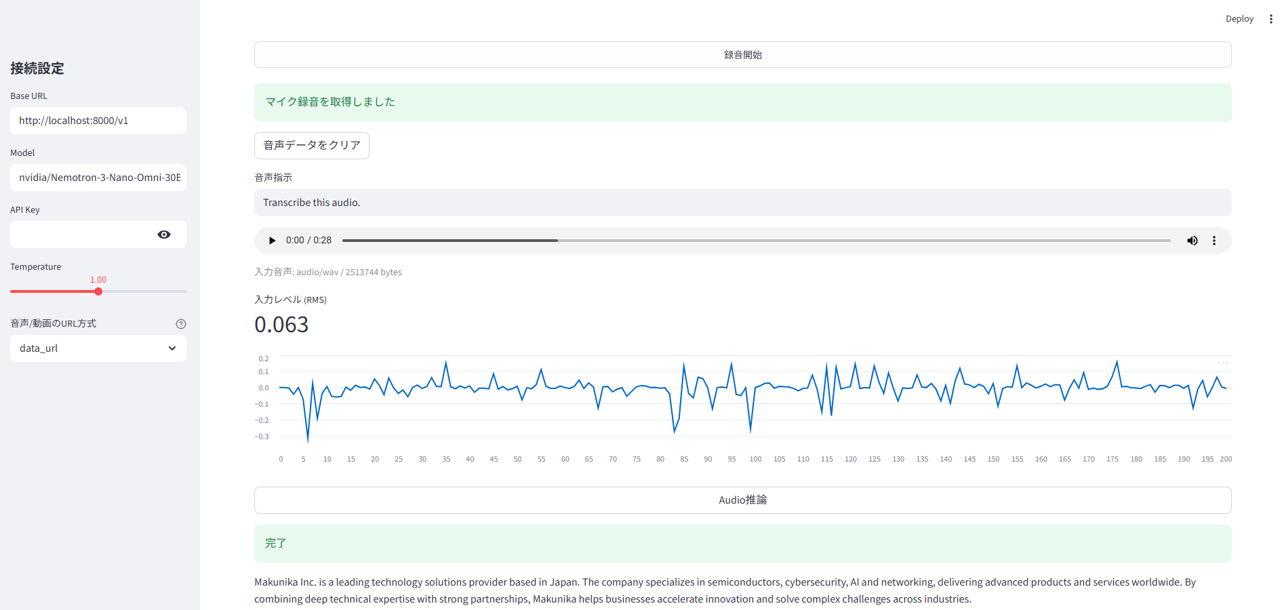
Speech inference
This is an example of capturing audio from a microphone and performing transcription.
Video Inference
This is an example of describing the content of a video chronologically, including changes in behavior.

This video shows a view of the railway tracks below from a position such as an elevated walkway or bridge. A green mesh fence runs in the foreground, and below it, you can see the gravel-covered rails.
At the beginning of the video, the front of the train appears from the right side of the screen. This train has a silver body with a bright green stripe running along the top. It has large windows on the front and the top is designed to reduce air resistance.
As the train approaches the front of the camera, its side becomes clearly visible. The "JR" logo and the word "YOKOHAMA" are written vertically on the body, suggesting that this is a JR East commuter train operating from Yokohama. The doors and windows are lined up regularly, and the joints between the carriages are also clearly visible.
As the train moves forward, the following carriages also pass by in quick succession. In the background is a tall concrete retaining wall, topped with green vegetation. Further in the distance, multi-story apartment buildings and commercial facilities can be seen, forming a cityscape.
A complex network of power lines and poles supports the train overhead. Finally, the last carriage of the train moves to the left of the screen, the tracks become empty, and distant slopes and buildings become visible. This footage quietly records an everyday commute scene.
Summary
In the field of edge-generated AI, requirements such as communication quality, environmental resilience, 24/7 operation, and cloud dependency risks are often needed simultaneously.
Jetson Thor significantly alleviates the bottlenecks on the edge side that have historically been "insufficient GPU memory to run large models and difficulty in performing inference at practical speeds," providing a more practical option for real-world use.
Furthermore, the Nemotron 3 Nano Omni is attractive because it can handle multimodal systems with a single model, resulting in a simpler configuration while achieving high inference quality. In addition, referencing Jetson AI Lab can shorten the time to start validation.
Furthermore, the Nemotron 3 Nano Omni can be combined with NVIDIA NemoClaw and AI agents to enable more advanced multimodal inference and tool integration.
If you're considering using generative AI at the edge, I highly recommend trying the combination of Jetson Thor and Nemotron 3 Nano Omni.
Reference URL

Click here for inquiries

