- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2172件がヒットしています。check

Introduction
For LLM applications that are expected to be used by a large number of people, "responsiveness" and "throughput" are important, as they have a significant impact on user experience and operating costs.
The cost of running an LLM application is a trade-off between the number of simultaneous queries it can handle while still providing responsiveness that keeps users engaged, and the user experience. Therefore, responsiveness and throughput are of concern.
In this three-part series, we will explain the results of using GenAI-Perf, a benchmark tool recommended by NVIDIA NIM™, and the various indicators that are output.
Since we are focusing on cost, we will not be looking at the output quality (accuracy) of LLM applications.
In this first article, we will explain the output indicators of GenAI-Perf, a benchmark measurement tool.
[Benchmarking LLM Applications]
Episode 1: What is GenAI-Perf?
Episode 2: How to use GenAI-Perf
Episode 3: NVIDIA NIM and vLLM Benchmark Measurement
What is GenAI-Perf?
GenAI-Perf is a command line tool for measuring the throughput and latency of generative AI models running on an inference server, and is provided as part of the Triton client library. The inference server API is assumed to be OpenAI compatible. It is recommended by NVIDIA as a benchmark tool for NVIDIA NIM.
Scenarios for LLM applications envisioned by GenAI-Perf
GenAI-Perf measures throughput latency assuming the LLM application is running in the following scenarios:
- A user of the LLM application issues a query (which includes a prompt that the user creates).
- The inference server receives it and places it in the job queue.
- The LLM model handles the prompts.
- The LLM model outputs a response to the user on a token-by-token basis (streaming response).
Indicators output by GenAI-Perf
Metrics
- Time to First Token (TTFT)
- End-to-End Request Latency (e2e_latency)
- Inter-Token Latency (ITL)
- Total system Throughput : Tokens Per Second (TPS)
- Requests Per Second (RPS)
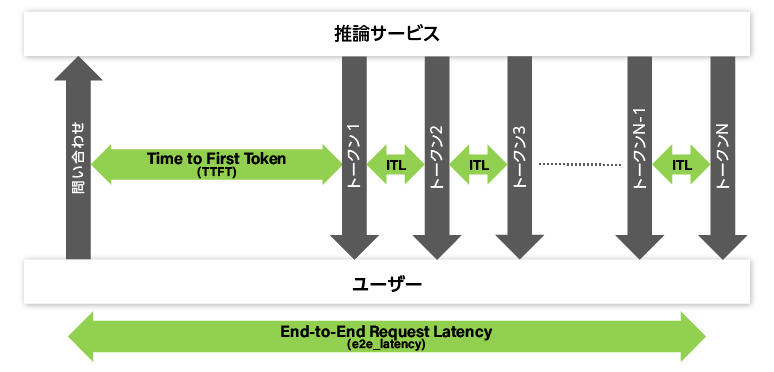
Time to First Token (TTFT)
Time to First Token (TTFT) is the time from when an inquiry is made to the LLM to when the first output token is returned. If the reply from the LLM does not contain a token, it will be excluded. (If the first reply from the LLM does not contain a token, but the second reply contains a token, the time from the inquiry to the second reply will be the TTFT value.)
In applications that use streaming LLM, tokens are typically displayed to the user as they are received, so the TTFT is the waiting time for the user.
Note that the TTFT includes the time it takes the LLM server to fill the request queue, as well as network latency. Also, the longer the query prompt, the longer the TTFT, since the LLM attention mechanism needs every prompt to populate the key-value cache.
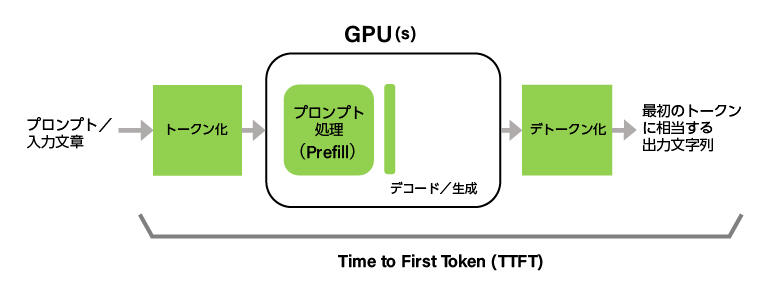
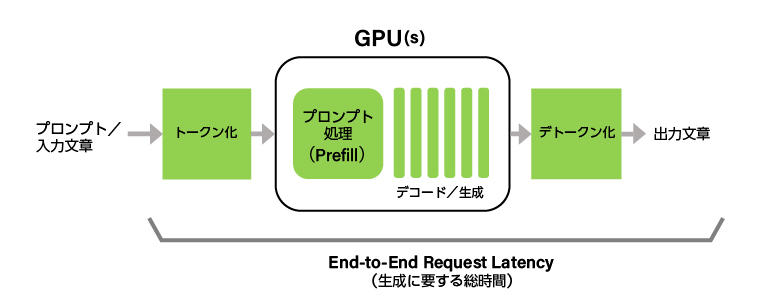
End-to-End Request Latency (e2e_latency)
End-to-End Request Latency (e2e_latency) is the time from when a user queries the LLM to when the LLM returns all output tokens. Note that e2e_latency includes the time involved in the LLM server's queuing and batch organization mechanisms, as well as network latency.
If Generation_time is the time between when a user receives the first token and when they receive the last token, e2e_latency can be expressed as follows:
e2e_latency = TTFT + Generation_time
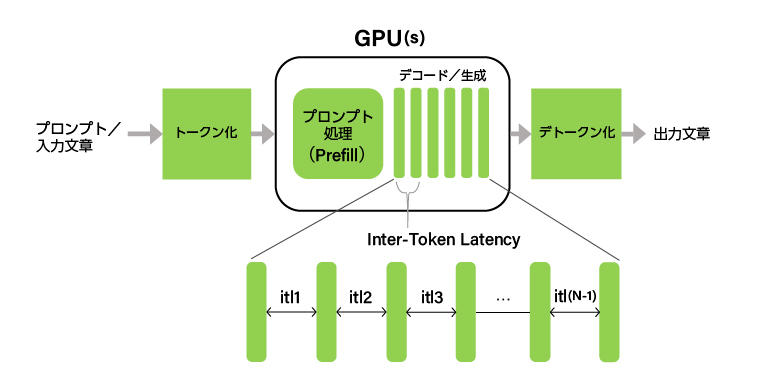
Inter-Token Latency (ITL)
Inter-Token Latency (ITL) is the average time between successive output tokens, sometimes called Time Per Output Token (TPOT).
Even if the metric is named the same, there are differences depending on the benchmark tool, such as whether or not to include the time to first token (TTFT). GenAI-Perf does not include TTFT and is defined as follows:
ITL = (e2e_latency - TTFT) / (Total_output_tokens - 1)
Total system Throughput : Tokens Per Second (TPS)
Tokens Per Second (TPS) is the number of tokens output per second. When there is sufficient GPU computing resources, TPS will increase as the number of queries to the LLM server increases. The strict definition of TPS is as follows:
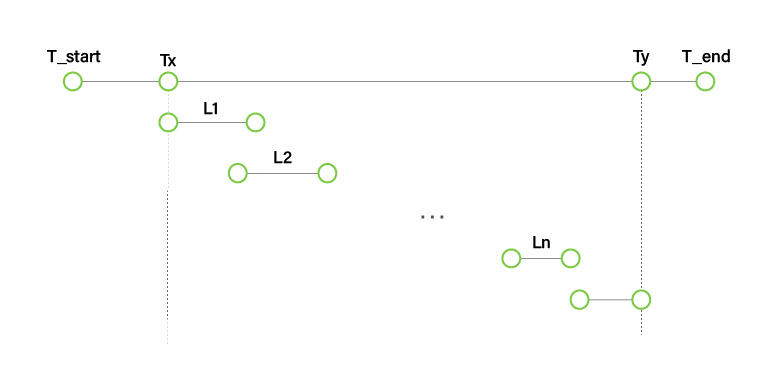
- Li: e2e_latency for the i-th query
- T_start: The start time of the benchmark by GenAI-Perf
- Tx: Time of first inquiry
- Ty: The time when the last response to the last query was received.
- T_end: Benchmark end time by GenAI-Perf
TPS = Total_output_tokens / (Ty - Tx)
Note: Warm-up and cool-down queries are not included when calculating TPS.
Requests Per Second (RPS)
Requests Per Second (RPS) is the number of queries completed per second.
RPS = total_completed_requests / (Ty - Tx)
Next time, we'll thoroughly explain how to use GenAI-Perf!
In this article, we introduced each of the indicators output by GenAI-Perf. What did you think?
Next time we will explain how to use GenAI-Perf.
If you are considering introducing AI, please contact us.
For the introduction of AI, we offer selection and support for hardware NVIDIA GPU cards and GPU workstations, as well as face recognition, wire analysis, skeleton detection algorithms, and learning environment construction services. If you have any problems, please feel free to contact us.

