- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2145件がヒットしています。check

In recent years, the development of generative AI, typified by text generation and image generation, has been remarkable, and services using generative AI are being provided one after another via the Internet. The computers running these services are typically located in remote data centers and utilize high-performance GPU cards to speed up AI processing.
On the other hand, in the field of intelligent video analysis (IVA), represented by AI surveillance cameras, edge AI, which executes AI processing close to the site, is becoming popular due to its efficiency. Edge AI is also attracting attention in generative AI due to improved performance of edge AI hardware.
By being able to execute AI processing on the edge side, network connectivity is no longer required to provide AI services, so generation AI services can be applied to autonomous mobile robots in locations with poor communication environments or where network connections tend to be unstable. It will look like this.
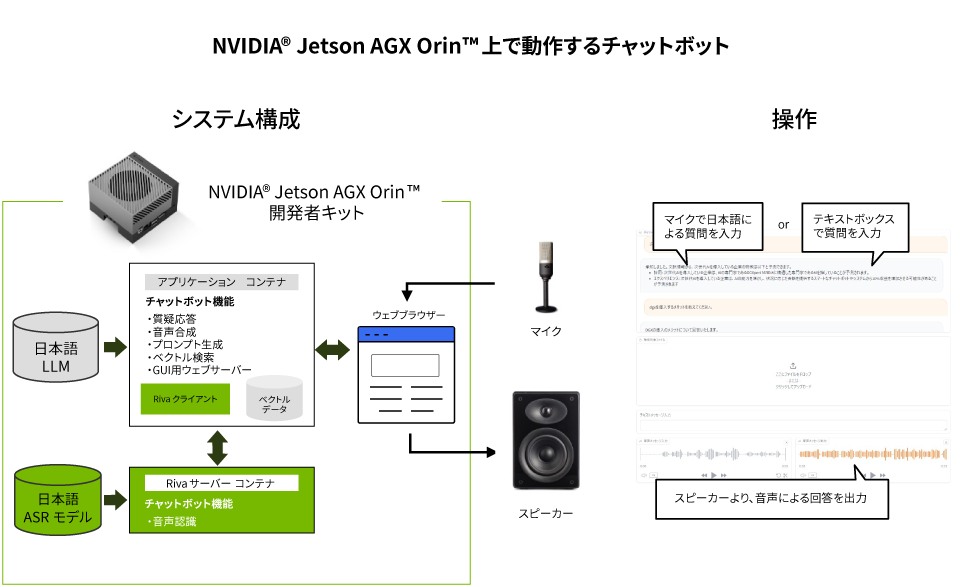
Therefore, Macnica has built a chatbot that runs on NVIDIA® Jetson AGX Orin™ as a demonstration of realizing generative AI at the edge, and will publish the process in this article.
[Create a chatbot that runs on edge-generated AI Jetson AGX Orin]
Episode 1 Jetson Generative AI Lab
Episode 2: Setting up the development environment
Episode 3 Consideration of system configuration
Episode 4 Implementation (no external information)
Episode 5 Implementation (using RAG)
In the first episode, we will understand the edge hardware requirements for generative AI and introduce a demo application published by Jetson Generative AI Lab.
Processor hardware requirements for generative AI
Generative AI uses a deep neural network model with an extremely large scale.
In addition to high-speed computing power, large-capacity and high-speed memory are also required. As an example, let's take a look at Meta's Llama2, which is a representative model for text generation provided as open source.
Llama2 has three parameter sizes: 7B, 13B, and 70B (B is Billion). When reading parameters with a bit length of 16 bits, even the smallest 7B model will take up approximately 14 GB (7G x 2 bytes). Typically, just loading an AI model requires approximately 14GB, as the entire parameter needs to be placed in memory. More memory is required to make the application viable.
*There is also a method of converting the parameter to an 8-bit integer type or 4-bit type, and in that case, the size will be 1/2 or 1/4 of the original size (16-bit floating point type), respectively. However, this decrease in accuracy may lead to a decrease in the quality of the generated results.
Additionally, as generative AI is still developing rapidly, there is a growing demand for the latest research results and the latest software to be incorporated immediately. NVIDIA CUDA® core GPUs are widely used in the field of deep learning, including generative AI, and a huge amount of software assets have been accumulated. Hardware with CUDA core GPUs is also very advantageous for edge applications.
NVIDIA® Jetson AGX Orin™
Considering the processor hardware requirements for generative AI, NVIDIA's edge platform NVIDIA® Jetson AGX Orin™ is a top choice. It has a large capacity memory of 64 GB that can support inference using generative AI models and an AI performance of 275 TOPS. Jetson AGX Orin is offered as a system-on-module (SOM). By incorporating this into your products, you can give them AI functionality.
Please see below for details on Jetson AGX Orin. (Click on the image to go to the product page)

Introducing Jetson Generative AI Lab
So, what kind of generative AI can be executed with Jetson AGX Orin? I think you'll want to try it out and actually get it working. The best way to do that is to try out the demo application that NVIDIA makes available on its Jetson Generative AI Lab website. Below are some representative examples.
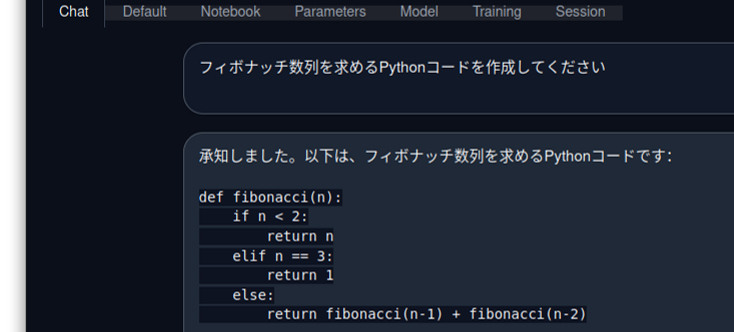
Text generation web UI (Questions and answers in Japanese)
This is a text generation demo using a large-scale language model using the Text generation web UI.
Text generation web UI supports various large-scale language models, but by using ELYZA-Japanese-Llama-2-7b-instruct*, you can try out question-and-answer in Japanese.
The ELYZA-Japanese-Llama-2-7b-instruct model is based on Llama2 developed by Meta, and ELYZA performs additional learning using Japanese text, and also solves various tasks according to instructions from the user. Post-learning for the purpose of: fine tuning.
※Akira Sasaki, Masato Hirakawa, Shintaro Horie, and Tomoaki Nakamura.Elyza-japanese-llama-2-7b, 2023.
LLaVA (AI model answers questions about the presented image)
The LLaVA model recognizes the content of images and answers questions from users about the images.
Since the LLaVA model has already learned from all kinds of images, it is possible to recognize a large number of things from images without the user having to carry out so-called annotation work such as troublesome tagging or adding bounding Box, and the associated learning. is.

(generated text)
The image depicts a large sailing ship docked in a harbor, surrounded by tail buildings and possibly some other boats. The ship has several sails up on its mast, indicating that it may be ready for departure or returning from a journey. It seems to be well-maintained as a tourist attraction in the city.
(Japanese translation)
The image depicts a large sailing ship moored in a harbor, surrounded by skyscrapers and possibly some other boats. Several sails are hoisted on the ship's mast, indicating that it is ready to set sail or return to port. It seems to be well maintained as a tourist attraction in the city.
Stable Diffusion XL (generate images from text)
Image generation using the famous Stable Diffusion.
You can try image generation using the Stable Diffusion XL model, which is an advanced version of Stable Diffusion.
As many of you may already know, this AI model generates images according to instructions entered by the user via text.
It is also interesting that by adjusting the parameters, images with different nuances can be generated even with the same instruction text.
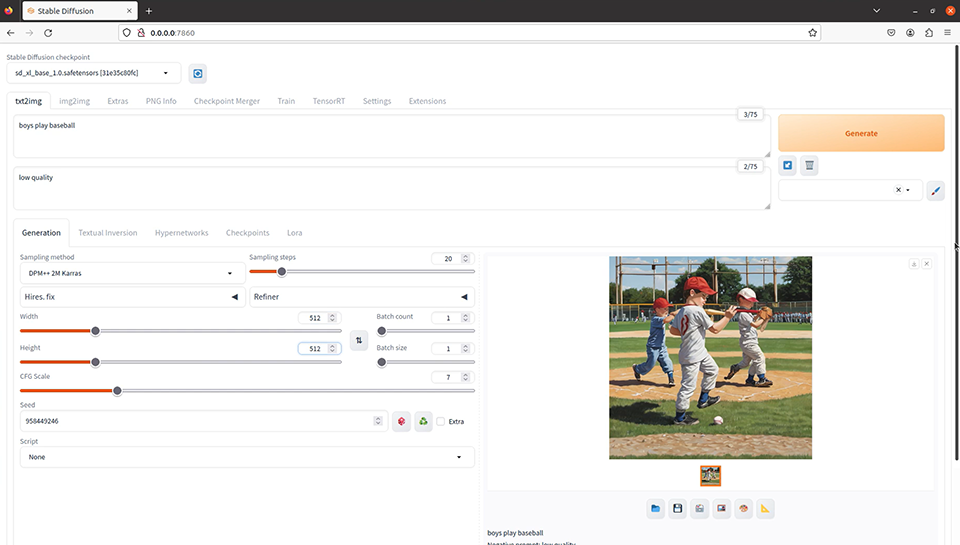
Prompt: boys play baseball
Negative Prompt: low quality
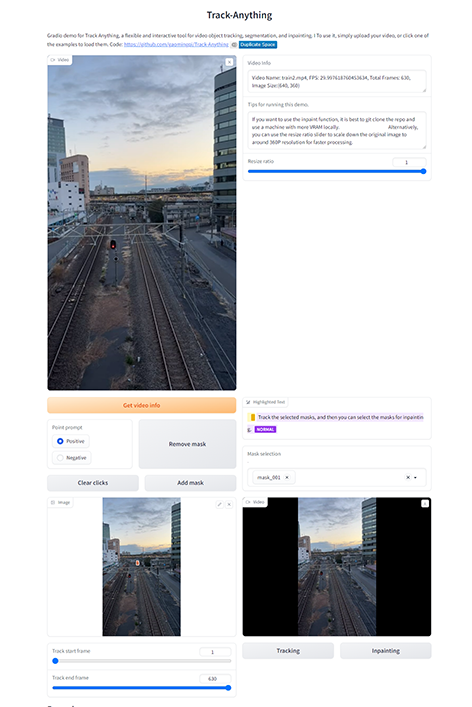
TAM (tracking any object)
This is a demo using a model called TAM (Track-Anything model) that segments anything and keeps tracking it.
Similar to the LLaVA model introduced earlier, TAM has been trained to recognize and segment any object. Therefore, users can continue tracking simply by specifying the object they want to track in one scene of a video.

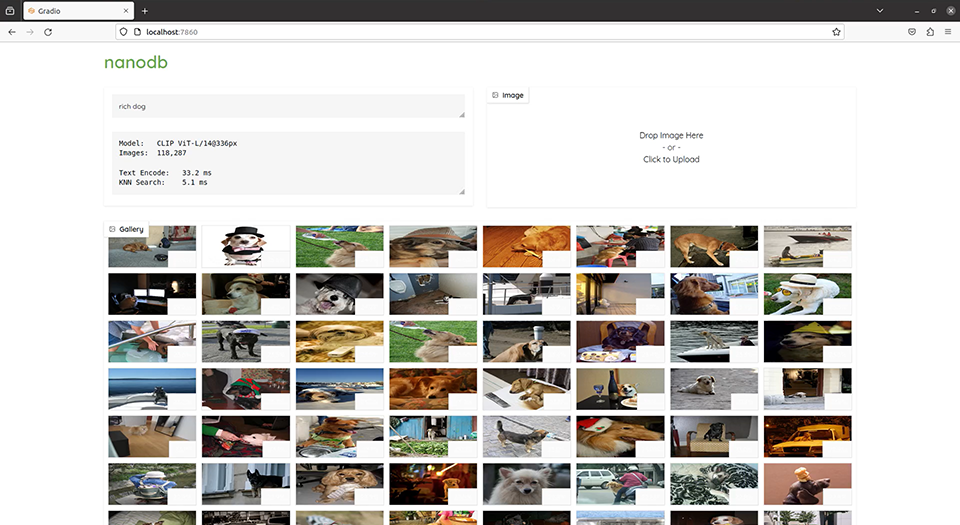
NanoDB (vector database for searching images from text)
NanoDB, a vector database, quickly searches for images that match the keywords specified by the user.
The AI model used is OpenAI's CLIP model.
The vector database is maintained by converting information into high-dimensional vectors, and the text vectors entered by the user are quickly matched with the vectors held in the database, and matching images are displayed.
In this demo, we will search for the desired image from approximately 120,000 images.
From episode 2 onwards, we will explain the steps to develop a chatbot that runs on Jetson.
In this article, we introduced the demo application published by Jetson Generative AI Lab. Jetson AGX Orin has sufficient performance to run these generative AIs and can deploy generative AIs to the edge.
In the next episode, we will explain the development environment for generative AI applications that run on Jetson.
[Create a chatbot that runs on edge-generated AI Jetson AGX Orin]
Episode 1 Jetson Generative AI Lab
Episode 2: Setting up the development environment
Episode 3 Consideration of system configuration
Episode 4 Implementation (no external information)
Episode 5 Implementation (using RAG)
*This series of articles was created in February 2024, and the chatbot was built using JetPack 5.1.2.
Clicking the button will take you to a simple form entry screen. Once you have completed the form, you will be notified by email of the URL for the second page.
If you are considering realizing generative AI with edge AI devices, please contact us.
Macnica has many achievements in supporting development using NVIDIA software solutions and Jetson that realize generative AI. If you are considering introducing AI and have any problems, please feel free to contact us.