- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2183件がヒットしています。check

Services that utilize AI (artificial intelligence) and deep learning technology have become a part of our daily lives, for example, temperature measurement systems for COVID-19 countermeasures, voice recognition on smartphones, and facial recognition systems for attendance management in companies. Users enjoy AI services through edge terminals and devices, but behind the scenes there are servers and data centers that provide the services, on which AI learns from large amounts of data and returns the results of analysis and predictions after processing the vast amounts of data. This use of AI has been progressing first in the HPC (High Performance Computing) field for research and development, and gradually enterprise cloud service providers and data center operators are actively incorporating it into their own services.
On the other hand, AI requires enormous computing resources, and due to the nature of parallel processing using multiple resources at the same time, it is becoming difficult to process with the in-house infrastructure and computing resources that we have been familiar with for many years. . Until now, if resources were insufficient, dozens of units would be added, and dozens of more units would be added and expanded based on the concept of scale-out. Out, scale up does not work.
This is due to the difference in data processing practices, such as “parallel processing” of huge amounts of data, whereas “sequential processing” that was commonplace in cloud network configurations is performed in AI. Therefore, for cloud service and data center operators who will start using AI from now on, we will introduce the manners of AI processing that "if you don't know now, you will lose money" and the construction of smart servers and networks for AI. We'll show you how.
Conventional cloud network and HPC/AI network
Differences between serial and distributed processing
In general cloud services, a client user makes some kind of request from an application. Then, the processing is broken down by function, the first half is executed, the result is passed to the next step, and the second half is processed. After completing the process in a form called service chaining, the result is returned to the user. The processing at this time is completed within one server when viewed on a server-by-server basis.
On the other hand, AI requires a huge amount of processing, so a single processing itself is distributed among the nodes within each server and is always synchronized. After completing the processing in a form called distributed computing or parallel computing, the result is returned to the user. In this case, the processing spans multiple servers.
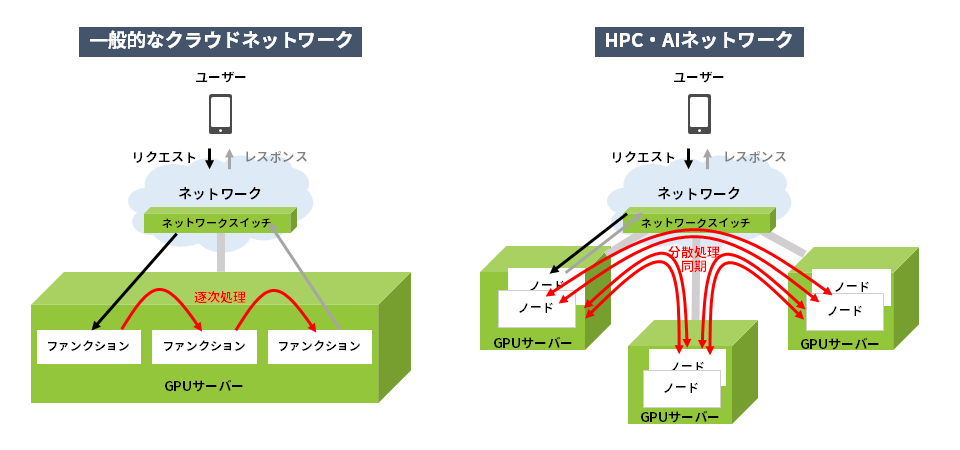
The difference between the two can be seen here
in a series of processes
・Whether the communication partner is inside the server cabinet or outside the server cabinet
・Whether the frequency of communication is low-frequency processing with only requests and responses, or high-frequency processing that always synchronizes
becomes.
In AI processing, there is a lot of communication with the outside of the server cabinet, and it can be seen that there is much more processing via network switches than in a general network. Next, let's compare the communication inside the server cabinet and the communication outside the cabinet, and look in detail at how much the network communication bandwidth changes.
Differences in communication bandwidth between inside and outside the server cabinet
Communication within the chassis is between GPUs, and the theoretical communication speed achieved by the high-speed GPU interconnect is 600Gbyte/sec (in the case of NVIDIA's third-generation NVLink). Communication outside the chassis requires network processing, so the CPU must be involved. In that case, it goes through PCI Express, so the theoretical communication speed is 31.51Gbytes/sec (PCIe gen.4 x16), which is only about one-thirtieth of communication between GPUs. It is well known that GPUs have high computing speeds, but you may have realized that this much communication speed is lost when you step outside the chassis.
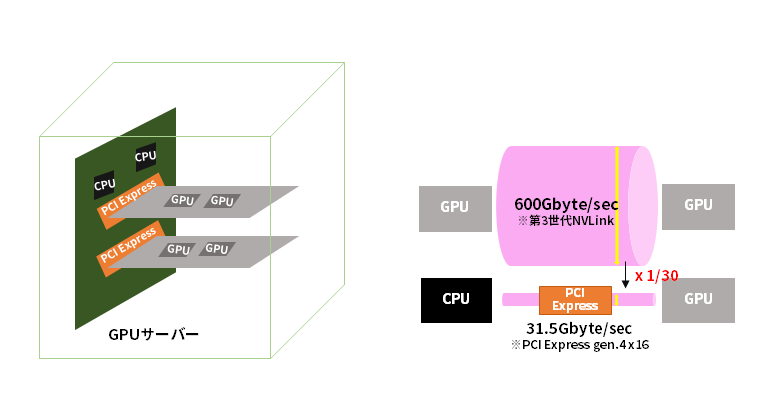
This communication speed is merely a theoretical value, and the actual value will be even slower. Although there are software and algorithms that can improve the loss, it would not hurt for network infrastructure engineers to know about the measures that can be taken to improve the infrastructure. In the next section, we will look at some specific measures.
Technology essential for network construction that does not slow down GPU computing speed
Based on the above, in order to avoid slowing down the GPU's calculation speed, it is very important to "construct a network that does not involve the CPU." The network communication bandwidth, in other words the size of the pipe, is predetermined, and the idea is to use it as efficiently as possible within that bandwidth.
There are several technologies that support this, but I will introduce the technology used by NVIDIA.
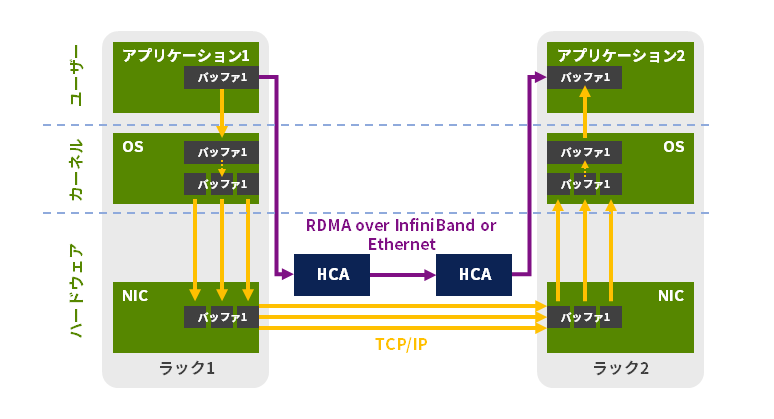
RDMA
RDMA is a data transfer technology that eliminates CPU intervention when copying memory data in inter-computer communication.
The card reads the memory in the computer's application and communicates with the corresponding card (HCA), bypassing normal network protocols, allowing data to be transferred directly to the destination computer's application memory without memory-to-memory copying, using only the card's hardware.
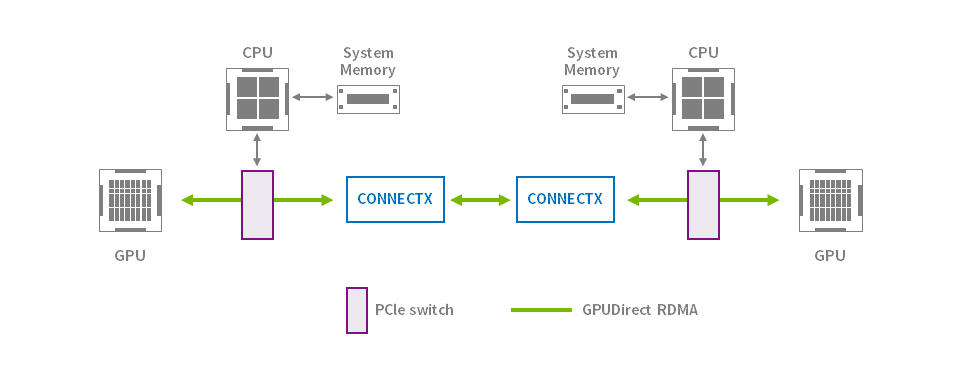
NVIDIA GPU Direct
RDMA allows peripheral PCI Express devices to directly access GPU memory. Designed specifically for GPU acceleration needs, GPUDirect RDMA provides direct communication between NVIDIA GPUs in remote systems. This eliminates the necessary buffer copying of data through the system CPU and system memory, improving performance.
Other considerations
We introduced GPU Direct as a network that does not involve the CPU.
What is needed for GPU Direct is a server equipped with a GPU and a corresponding card. Once the calculation speed becomes fast enough, the performance of the storage that supplies the original data also becomes important. If you want to build a cluster, you will need to continue to improve the performance of the calculation method and algorithm.
(If you don't create a cluster, you can just consider storage, but there is a need for users to create a cluster.)
In order to make an HPC/AI system successful, not only techniques such as GPU Direct introduced this time, but also optimization of both hardware and software are required.
NVIDIA technology essential for building AI systems
We have introduced you to the etiquette of AI processing and the technologies that will be essential for building future server networks. What do you think? There is an NVIDIA Network Adapter Card (NIC) that is packed with these technologies. If you are considering building one, please also take a look at the following.
Inquiry



