- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

生成AI活用の課題点
自社の業務に特化した回答ができない
LLM(大規模言語モデル)の学習データは主にインターネット上の公開文書から作成されています。このため、汎用LLMは一般的な知識を持つ一方で、特定の企業やドメイン固有の専門知識が不足しており、業界や個別企業に特有の語彙や文脈を理解することが難しいです。これを解決するためには、カスタムモデルの構築やRAG(Retrieval-Augmented Generation)と呼ばれる仕組みを利用し、基盤モデルが持っていない知識を補完する必要があります。
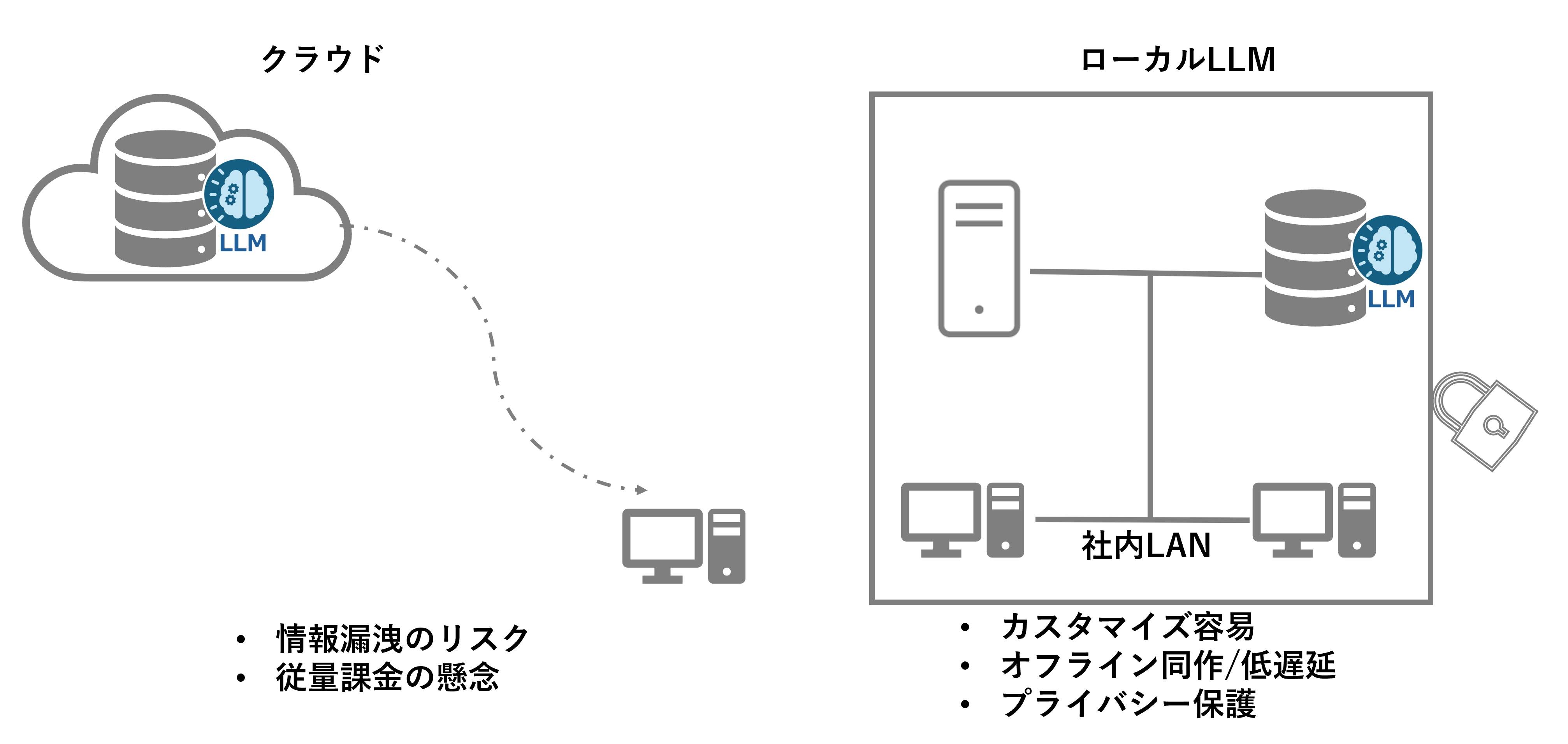
機密情報をクラウドにあげたくない
クラウド環境ではデータが外部のサーバーに保存されるため、社内のノウハウや顧客情報などの機密情報が漏洩するリスクがあります。また、クラウドサービスプロバイダー(CSP)によって提供されるセキュリティ対策は基本的に高いものの、最終的なデータ管理責任は企業側にあるため、特に機密性の高い情報については慎重になる必要があります。このような理由から、多くの企業は機密情報をクラウドにアップロードすることを避け、オンプレミス環境での処理を選択する傾向があります。
ローカルLLMとは
ローカルLLM(Local Large Language Model)とは、企業や組織が自社のオンプレミス環境で構築・運用する大規模言語モデルを指します。
ローカルLLMの詳細を学びたい方はこちらの記事を併せてご覧ください。
ローカルLLMのメリット
1.セキュリティとプライバシー
ローカルLLMは自社内でデータを処理するため、機密情報や個人情報を外部に送信する必要がなく、データ漏洩のリスクを低減できます。
2.カスタマイズ性
自社の特定の業務ニーズに応じてモデルを自由にカスタマイズできるため、業界固有の知識や専門用語を学習させることが可能です。
3.パフォーマンス
ネットワーク遅延がないため、リアルタイムでの推論が可能であり、大量のデータを迅速に処理できます。
4.コスト管理
初期投資は高額になる場合がありますが、長期的には従量課金制のクラウドサービスよりもコストを見積もりやすく、安定した運用が可能です。
このように、ローカルLLMは特にセキュリティやカスタマイズ性を重視する企業にとって非常に有用な選択肢となります。
ローカルLLM導入ハードル
GPU環境の構築(インフラ)
ローカルLLMを効果的に運用するためには、高性能なGPU環境が必要です。この構築にはいくつかの障壁があります。

最適なハードウェアの選定
実現したいことに対して、最適なGPUリソースを選定するためには、生成AIのモデルに対する知見や実際に試してみる環境が必要となります。またGPUインフラは高額なので、最適なハードウェアを選定できないと無駄な投資となってしまう可能性があります。

インフラ環境構築とメンテナンス
インフラ環境構築についてはサーバーやネットワーク、その上で実装されるソフトウェアなどの専門知識が必要となります。GPU環境の構築後も、ハードウェアのメンテナンスやアップグレード、故障時の対応などに対応できる人材が必要となります。これにより、運用コストや人的リソースが増加する可能性があります。

スケーラビリティの制約
クラウド環境と比較して、オンプレミスのGPU環境ではリソースの拡張が難しい場合があります。需要の変動に応じて柔軟にスケールアップ・ダウンできないことが、導入の障壁となることがあります。
ローカルLLMの構築(ソフトウェア)
ローカルLLMを活用するためのソフトウェアの構築にも、いくつかの課題があります。

技術的な専門知識
ローカルLLMを構築するためには、機械学習や自然言語処理に関する深い理解が必要です。また、モデルのファインチューニングやRAG(Retrieval-Augmented Generation)、AIエージェントなどの高度な技術を駆使する必要があるため、専門的なスキルを持つ人材の確保が重要です。

開発時間
自社のニーズに合わせたカスタマイズや統合を行う際、開発にかかる時間が長くなることがあります。特に、試行錯誤を繰り返すプロセスが必要な場合、迅速な展開が難しくなることがあります。

適切なツールの選択
ローカルLLMを実装するために必要なツールやライブラリは数多く存在する為、自社の目的に合わせたツールの選択が重要となります。
以上のように、ローカルLLMの導入にはインフラとソフトウェアの構築それぞれにおいて、コストや技術的な課題が存在し、企業にとっては慎重な検討が必要です。
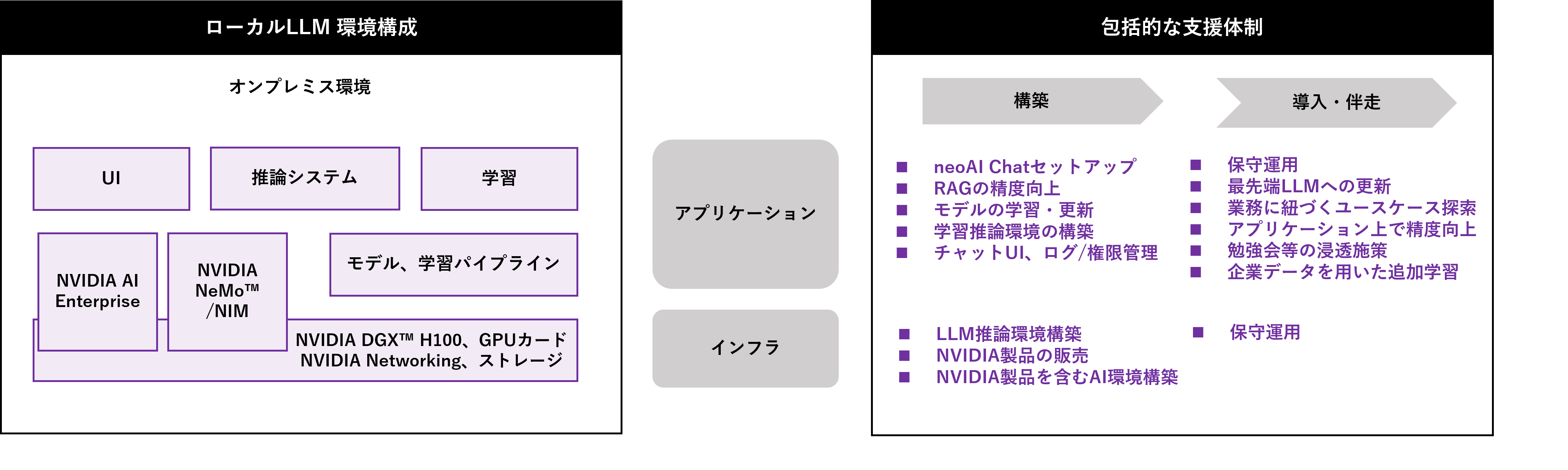
ローカルLLM構築サポート サービス内容
ローカルLLMの活用においては、自社に開発のノウハウを蓄積したい場合とアプリケーションパッケージを導入したい場合があります。
NVIDIA製品を取り扱う国内代理店でAIインフラ構築の専門知識や生成AI活用における豊富な実績とノウハウを持つマクニカでは、その両方に対応できるよう包括的な支援体制を組み、構築から導入、伴走支援まで一気通貫で企業の生成AI活用をサポートします。
ローカルLLMのインフラ構築では、お客様の課題感やコストに合わせて最適なハードウェアの提案から導入、環境構築からメンテナンスまでサポートすることが可能です。
インフラを管理運用するためのツールも取り扱っており、インフラ管理者の方が特別な知識なく、メンテナンスできる環境や、GPUを効率的に使用することができ、より多くのユーザーが利用できる環境の提供も可能です。
RAGやAIエージェントなどの構築では、生成AI開発を加速するソフトウェアNVIDIA NeMo™や、展開を加速するソフトウェアNVIDIA NIM™、さらにソフトウェア有償サポートとNVIDIA NIMを活用するときに必須となるエンタープライズAIプラットフォーム NVIDIA AI Enterprise等様々なツールを活用し、NVIDIA AIインフラストラクチャーソリューション上でローカルLLMの構築を実施します。
導入後も、各企業の固有の課題に応じた精度向上や機能拡張など、継続的かつきめ細やかなサポートを提供し、本ソリューションを通じて日本企業のDXを加速させ、生成AIの実用化と企業競争力の向上を強力に推進してまいります。
お客様の実現したい内容に合わせてハードウェアとソフトウェアをワンストップで提供
メニュー
1ヶ月間でRAGの精度評価の自動化実現を伴走させて頂くサービス
2ヶ月間でAIエージェントの基礎からユースケースに沿った実装までを伴走させて頂くサービス
ローカルLLM構築のメリットを、ウェビナーで学びませんか?

関連製品ページ





お問い合せはこちら

