- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2189件がヒットしています。check

NORフラッシュの弱点
NORフラッシュは、組込みシステムのコードストレージにおいて定評があります。NORフラッシュのテクノロジーは本質的に堅牢であり、”End-to-End”のシグナルインテグリティーを保有し、10万時間以上のデータ保持をサポートします。NORフラッシュは、512Mビットまでの容量帯においてビット単価のコスト競争力がありますが、ムーアの法則で唱えられているスケーリング(プロセスの微細化)の観点では大幅に遅れを取りました。
しかし、組込みシステムにAIを実装し始めている多くの開発者にとって、NORフラッシュのスケーリングの遅れは問題を引き起こします。機械学習などのアプリケーションは複雑なコードを生成するため、1Gビット以上のコードストレージを必要とし、この容量帯におけるNORフラッシュのビット単価はNANDフラッシュと比べて割高です。これは、NANDフラッシュがムーアの法則に従って46 nm、32 nm、2x nm、1x nmと推移していったためです。チップ面積とコストの間には非常に密接な相関関係があるため、1Gビット以上の高容量帯において、プロセスノードが小さいほどNANDフラッシュはNORフラッシュよりも安価になります。
今日のスマートデバイスやコネクテッドデバイスは、セキュリティーパッチや機能のアップグレードを行うためフィールドアップデートやOTA(Over-the-air)アップデートを必要とします。一般的なOTAアップデートでは、不揮発メモリーに格納された既存コードを新規コードで上書きします。つまり、アップデート実行中にシステムの電源を切る必要があります。ダウンタイムを最小限に抑えるため、開発者は出来るだけ早く更新プログラムを上書きしたいと考えるでしょう。したがって、OTAアップデートにとって重要なパフォーマンスは、プログラム/イレース時間であり、これはシリアルNORフラッシュよりシリアルNANDフラッシュの方が優れています。
NANDフラッシュの評判における問題点
組込みシステム向けのAIアプリケーションにおいて、NANDフラッシュの価格とパフォーマンスには利点があります。しかし、開発者たちにシリアルNANDを選択してもらうためには、意識改革を必要とします。これは、超大容量NANDのユースケースのみに基づいた先入観が、すべてのNANDフラッシュに対して持たれてしまっていることに起因します。
ラップトップコンピューターやタブレットなどで使われるSSD(ソリッドステートディスク)向けの超大容量NANDフラッシュにおいては、データ整合性およびデータリテンションの優先順位を下げ、大容量と低ビット単価が実現されています。事実、音楽やビデオファイルの数ビットの破損や損失は、最先端のプロセスノードで製造された超大容量NANDフラッシュにとっては許容範囲内と言えます。しかし、組込みシステムのコードストレージ用に最適化されたシリアルNANDフラッシュのパフォーマンスは、最先端の超大容量NANDフラッシュとは大きく異なります。
ウィンボンドのハイパフォーマンス・高信頼性シリアルNANDフラッシュ
組込みシステムにおけるコードストレージ用としてシリアルNORフラッシュからシリアルNANDフラッシュへの移行を加速するため、ウィンボンドはNANDフラッシュを以下のように改良しました。
- 1セクタあたり1ビットのビットエラー
- 最大83MB/秒の高速読出しパフォーマンス
- シリアルNORフラッシュとのハードウェア/ソフトウェア互換性
ウィンボンドのシリアルNANDフラッシュQspiNAND(Quad SPI NAND)の高い信頼性は、46nmプロセスでの製造とSLC(シングルレベルセル)のメモリセル構成によって得られます。この世代の製造プロセスは、長年にわたり市場で利用されてきたことにより、信頼性と品質が証明されています。ウィンボンドの46nmプロセスによるシリアルNANDフラッシュQspiNANDは、10万時間以上のデータ保持を保証しています。さらに、ウィンボンドのシリアルNANDフラッシュQspiNANDには、1ビットECC(Error Correction Code)が実装されており、書込みと読出しの両オペレーションでデータの整合性を維持します。
パフォーマンスがさらに強化されたウィンボンドの第二世代シリアルNANDフラッシュ
ウィンボンドのシリアルNANDフラッシュQspiNANDは、シリアルNORフラッシュより優れたパフォーマンスとコストの優位性を実現します。組込みシステムに実装されたAIにおいても、機械学習アルゴリズムをローカルに実装する推論エンジンは、非常に複雑なコンピューティング操作をミリ秒単位で頻繁に実行する必要があります。これには、高速なデータ読出しパフォーマンスが必要です。
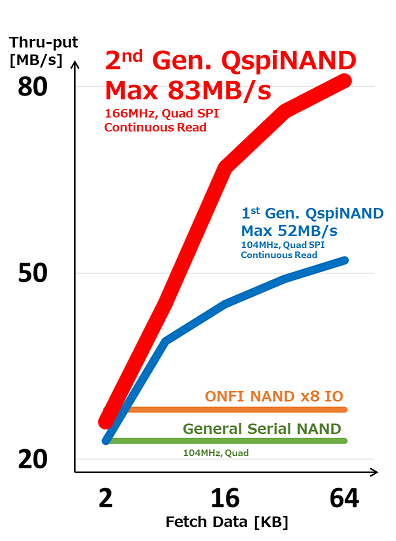
図1:ウィンボンドの第二世代シリアルNANDフラッシュQspiNAND W25N-JWは、最大83MB/秒の読出しスループットを提供する(画像著作権:ウィンボンド・エレクトロニクス株式会社)
ウィンボンドの第一世代のシリアルNANDフラッシュQspiNANDにおいて、読出しスループットは最大52MB/秒でした。昨年発表したウィンボンドの第二世代のシリアルNANDフラッシュQspiNAND W25N-JWシリーズでは、最大読出しスループットが83MB/秒です(図1参照)。さらに、W25N-JWのチップを二枚スタックしたW72N-JWシリーズでは166MB/秒まで倍増させることが可能です。W72N-JWシリーズは、デュアルQuad SPIインターフェースにより8つのI/Oで構成されています。ホストコントローラは一つのチップセレクト端子を介してW72N-JWの操作が可能です(図2参照)。
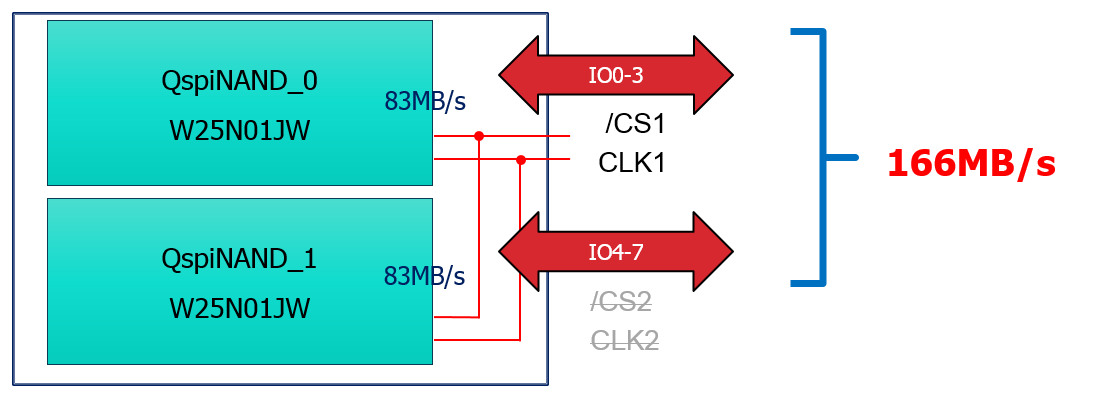
図2:ウィンボンドのデュアルQspiNAND W72N-JWは、最大166MB/秒の読出しスループットを提供する(画像著作権:ウィンボンド・エレクトロニクス株式会社)
この高速読出しスループットにより組込みシステムのレイテンシーが短縮されます。ウィンボンドのシリアルNANDフラッシュQspiNANDは、スピーディーなOTAアップデートもサポートし、ダウンタイムを最小限に抑えるという性能も備えています。シリアルNORフラッシュの書込みスループットが0.36MB/秒なのに対し、シリアルNANDフラッシュQspiNANDは8.5MB/秒です。シリアルNORフラッシュが1Gビットのデータをプログラミングするのにかかる合計時間は約6分ですが、第二世代のシリアルNANDフラッシュQspiNANDではわずか15秒しかかかりません。イレース時間は、シリアルNORフラッシュでは64Kバイトのブロックに対して150msですが、シリアルNANDフラッシュQspiNANDでは128Kバイトのブロックに対して2msです。
組込みシステムへ簡単に統合可能
AIの機能を組込みシステムに統合する傾向は、1Gビット以上の容量で割高なシリアルNORフラッシュの代替としてシリアルNANDフラッシュに移行する動きを強力に後押しします。ウィンボンドのシリアルNANDフラッシュQspiNANDは、シリアル NORフラッシュのインターフェースとソフトウェアの互換性があり、追加で必要なコマンド数は、NANDフラッシュ固有の操作、ECC、ルックアップテーブル(LUT)制御の5個だけです。さらに、業界標準のフットプリントと互換性をもったピン配置で提供されるため、シリアルNORフラッシュを実装した既存デザインに対して単純に置き換え可能です。
また、ウィンボンドのシリアルNANDフラッシュQspiNANDは、NXPセミコンダクターズやSTマイクロエレクトロニクス、ルネサス エレクトロニクスなどのSoCプロバイダーにサポートされており、そのエコシステムによってさらに採用が促進されるでしょう。たとえば、NXPセミコンダクターズは、エッジコンピューティングプロセッサLS1012Aの開発ボードFRWY-LS1012Aに、ウィンボンドのSpiStack(シリアルNORフラッシュとシリアルNANDフラッシュを1つのパッケージにスタックした製品)を採用しました。QspiNANDフラッシュにLinux® オペレーティングシステムコードが格納され、シリアルNORフラッシュにブートコードが格納されています。
第2世代のQspiNANDは現在1Gビットにて提供していますが、2Gビットや4Gビットなどの容量にも拡張可能です。これは最先端のAIテクノロジーなどにより1Gビット以上のコードストレージを必要とする組込み開発者のニーズに対するロードマップを提供します。
お問い合わせ
本記事に関してご質問などありましたら、以下より問い合わせください。
Winbond メーカー情報Topに戻る
Winbondのメーカー情報Top ページに戻りたい方は以下をクリックください。