- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2136件がヒットしています。check

今回の内容
第1話、第2話でベンチマークの各指標やベンチマーク測定ツールであるGenAI-Perfについて解説しました。
最終話となる第3話ではNVIDIA NIM™とvLLMと呼ばれる推論サーバーの2種類の推論サーバーについて、GenaAI-Perfを使用してベンチマークの測定を行います。
[LLMアプリケーションのベンチマーク測定]
第1話 GenAI-Perfとは?
第2話 GenAI-Perfの使い方
第3話 NVIDIA NIM™とvLLMのベンチマーク測定
NVIDIA NIM™とは
NVIDIA NIMは、企業における生成AIの展開を加速するために設計された推論用のマイクロサービスで、NVIDIA AI Enterpriseに含まれます。
オープンソースのモデルやNVIDIA AI FoundationモデルなどをサポートするNIMは業界標準のAPI(OpenAI互換)により、オンプレミスでもクラウドでもシームレスでスケーラブルなAI推論を実現します。
詳細はこちらをご覧ください。
vLLMとは
vLLM は、LLM 推論とサービングのための高速で使いやすいライブラリーです。
NIMと同様に業界標準のAPI(OpenAI互換)であり、HuggingFaceのモデルとのシームレスな統合を実現します。
詳細はこちらをご覧ください。
測定条件
今回測定した条件およびコードを下記に示します。
本記事ではRAGのパイプラインを構築することを想定し、input/outputは2500/500とします。
また、今回の測定ではRun:aiと呼ばれる高度なジョブスケジューラーを使用してコンテナをデプロイしました。
Triton Inference Serverは24.06-py3使用しました。
| 推論サーバー | Model | Quantization | GPU | concurrency | input/output | Version |
| NIM | meta / llama-3.1-70b-instruct | FP8 | H100x4(SXM) | 1,10,50,100 | 2500/500 | v1.1.0 |
| vLLM | neuralmagic/Meta-Llama-3.1-70B-Instruct-FP8 | FP8 | H100x4(SXM) | 1,10,50,100 | 2500/500 | v0.5.4 |
declare -A useCases
# Populate the array with use case descriptions and their specified input/output lengths
useCases["RAG"]="2500/500"
# Function to execute genAI-perf with the input/output lengths as arguments
runBenchmark() {
local description="$1"
local lengths="${useCases[$description]}"
IFS='/' read -r inputLength outputLength <<< "$lengths"
echo "Running genAI-perf for$descriptionwith input length$inputLengthand output length$outputLength"
#Runs
for concurrency in 1 10 50 100; do
local INPUT_SEQUENCE_LENGTH=$inputLength
local INPUT_SEQUENCE_STD=0
local OUTPUT_SEQUENCE_LENGTH=$outputLength
local CONCURRENCY=$concurrency
local MODEL=meta/llama-3.1-70b-instruct
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3.1-70B-Instruct \
--measurement-interval 10000 \
--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json \
-- \
-v \
--max-threads=256
done
}
# Iterate over all defined use cases and run the benchmark script for each
for description in "${!useCases[@]}"; do
runBenchmark "$description"
done測定結果
測定結果を下記に示します。
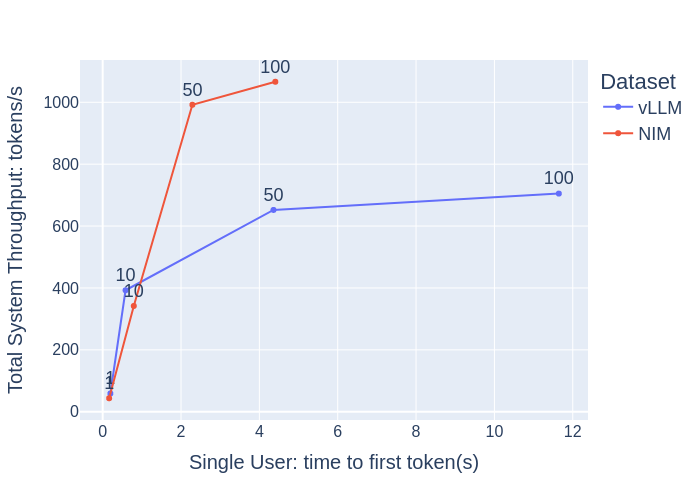
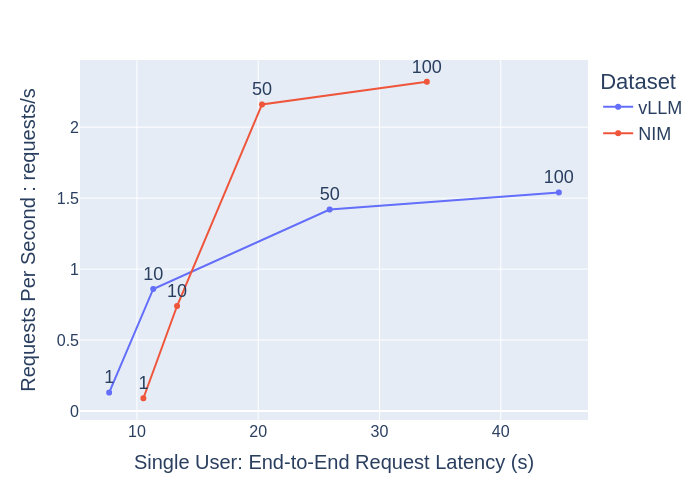
【concurrencyが1や10のように小さい場合】
・vLLMとNIMでは上記の結果においてそれほど差がない
・Time to First Token(TTFT)やEnd-to-End Request Latency(e2e_latency)の値自体が小さい
ここからは、ユーザーとしてはどちらの場合においても快適なLLMと言えるのではないでしょうか。
【concurrencyが1,10,50,100と増えてきた場合】
vLLMとNIMを比較した場合、NIMは、
・横軸方向のtime to first tokenとEnd-to-End Request Latencyの増加量を少なく抑えている(高い応答性を保っている)
・縦軸方向のTotal system ThroughputとRequests Per Secondの増加量が大きい(1秒当たりの処理数が高い)
これらの結果より、NIMの方がより大人数で快適に使用できることを想定した推論サーバーになっていると言えます。
LLMアプリケーションの運用コストは、TTFTやe2e_latencyのようなユーザーの興味を引き付けることができる応答性を保ちながら、同時に処理できる問い合わせをどの位に設定するかで変わってきます。
今回の測定結果は実際のLLMアプリケーションの運用コストを見積もる際の参考になるのではないでしょうか。
まとめ
本シリーズでは、運用コストに焦点を当て応答性やスループットに関して、NVIDIA NIM推奨のベンチマークツールGenAI-Perfを実際に使用した結果と、出力される各指標について解説しました。今回の結果はあくまで参考程度ではございますが、企業における生成AIの導入コストを検討する際にご参考にしていただけますと幸いです。
AI導入をご検討の方は、ぜひお問い合わせください
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際は、ぜひお問い合わせください。

