- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2183件がヒットしています。check

本記事では、NVIDIA® Jetson AGX Orin™ 開発者キット(以下、AGX Orinとする)を最大限活用いただくために、AGX Orin上でコンテナやKubernetesを活用したアプリケーション開発を体験する方法をご紹介します。
第2話は第3章から解説します。第1章からご覧になる方はこちら
第1章 構築体験できるシステムは「音声によるロボット操作」
第2章 エッジデバイスでKubernetesを活用する際のアプリケーション構成を理解する
第3章 コンテナ/Kubernetesを活用したアプリケーション開発の流れを理解する
第4章 レッドハットMicroShiftを用いてKubernetesを活用したシステム構築を実践する
第3章 コンテナ/Kubernetesを活用したアプリケーション開発の流れを理解する
そもそも、コンテナとは
コンテナとは、Linux Kernelの仕組みを使ってアプリケーション(プロセス)の実行環境を論理的に分離する技術です。具体的には、ファイルシステムやネットワーキング、各コンテナのシステムリソースが名前空間として分離されます。この分離技術により、アプリケーションの実行環境を最低限の権限とリソースにとどめて運用することが可能です。
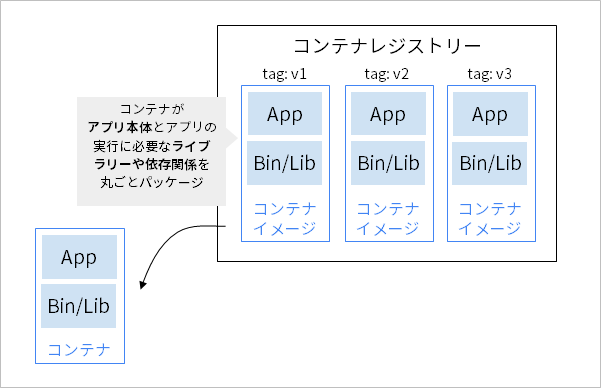
コンテナを利用する際は、「コンテナイメージ」と呼ばれるイメージファイルを作成します。コンテナイメージは、コンテナの中身を記録したブループリントやスナップショットのようなものです。コンテナを利用する際は、コンテナイメージの単位でアプリケーションのバイナリーや利用するライブラリーとの依存関係をパッケージングし運用します。
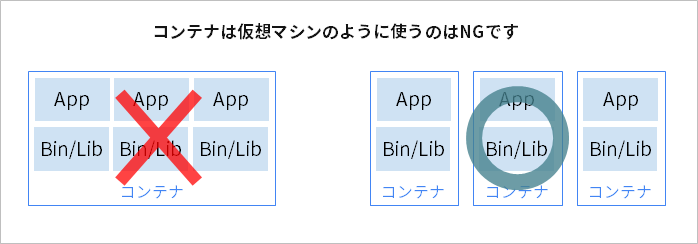
コンテナが出始めた頃は、コンテナを仮想マシンの様に扱い、複数のアプリケーションをコンテナに詰め込んだ使い方が多かった印象があります。しかし、コンテナのメリットを活かすには、アプリケーションを一つのコンテナに詰め込みすぎないで、更新しやすい単位で分割することが大切です。コンテナを用いたアプリケーション開発の原則として、「1コンテナ1プロセス」という原則を最低限知っておく必要があります。少なくともこの原則を守るだけで、更新しやすいシステムの実現の近道になります。
一方、この原則に則ると、多くのコンテナを管理する必要が出てくるでしょう。そこで、コンテナの管理を効率化するソフトウェアとしてKubernetesが登場しました。
そもそもKubernetesとは
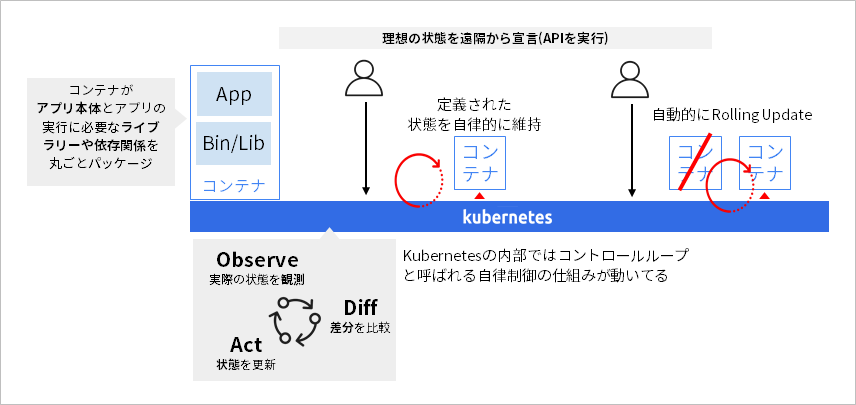
Kubernetesは、Googleが開発したBorgというソフトウェアがベースのオープンソースです。Kubernetesの特徴は、宣言型のオペレーションによる「自律システム」という点です。Kubernetesの内部では、管理対象のリソースの現在の状態を逐次監視し、現在の状態とあるべき状態に差分が発生した際に、現在の状態をあるべき状態へ自律的に近づける「コントロールループ」と呼ばれる機構が動作します。このコントロールループを活用し、利用者は、システムのあるべき状態をAPIにより「宣言」することで、Kubernetesが自動的にシステムの状態を宣言された状態へ維持するように働きます。たとえば、遠隔からコンテナをデプロイして起動したり、アプリケーションの新しいバージョンを宣言して通信へ影響を与えないように自動的にローリングアップデートしたりすることが可能です。
Kubernetesは、広範なリソースを管理対象とでき、単純にコンテナだけにとどまらず、CPU/メモリー/ストレージといったコンピューティングリソースや、ロードバランサーなど、さまざまなリソースを管理できます。つまり、Kubernetesは、コンテナを用いてシステム開発する際の「OS」のような役割を担います。
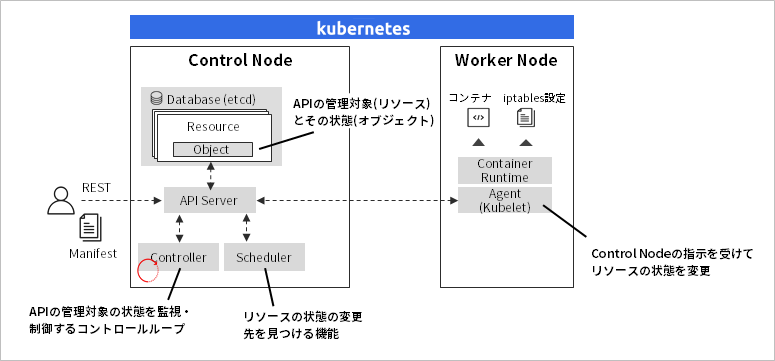
Kubernetesのアーキテクチャーは、APIを中心に各コンポーネントが分散した設計が採用されています。KubernetesのAPIは、「リソース」と「オブジェクト」と呼ばれる概念を用いて、監視対象の状態を把握します。リソースは、たとえば、コンテナ(Kubernetesでは、「Pod」と呼ばれます)、オブジェクトは起動状態、起動台数、ヘルスチェックの結果といった、コンテナの状態に該当します。前述のコントロールループは、Kubernetes内部で動作するControllerが担い、Kubernetes APIを介してリソースの状態を再帰的に把握、制御します。
また、Kubernetesには独自のリソースを追加する「カスタムリソース」と呼ばれる機能があります。このカスタムリソースを活用することで、Kubernetesの管理対象のリソースをさらに拡張することが可能です。たとえば著名なものに、データベースのクラスターの状態の管理やGPUドライバーのライフサイクルの管理などがあります。このカスタムリソースの恩恵により、KubernetesのAPIやコントロールループの仕組みを活用して、自律的なオペレーションの種類を増やすための「Kubernetesネイティブなオープンソース」が数多く開発されています。
このようなKubernetesのエコシステムの広がりにより、Kubernetesによる自律オペレーションの種類を増やすことができ、セルフサービス型のプラットフォームを容易に実現できる環境が整備されてきました。この特徴をエッジデバイスにも活用することで、エッジとクラウドを組み合わせたSaaSの実現を視野に入れることができます。
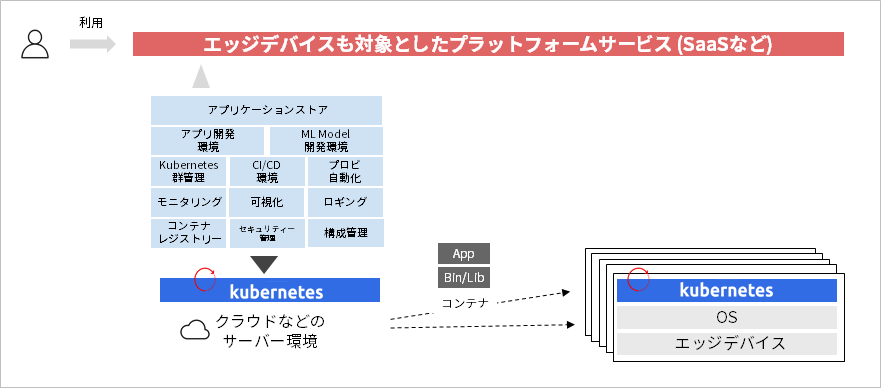
コンテナ/Kubernetesを活用したアプリケーション開発の流れ
コンテナを活用したシステム構築では、実装したアプリケーションを含むコンテナイメージをビルドし、「コンテナレジストリー」へ登録します。つまり、コンテナを用いたシステム構築ではコンテナを納品物として管理するのが最適です。コンテナイメージをアプリケーションのバージョンの単位で管理しておくことで、アプリケーションのアップデートやロールバックを効率化できます。また、納品されたコンテナをテスト環境や本番環境へ段階的にリリースし、アプリケーションの信頼性を高める運用も可能です。
また、Kubernetesを用いたシステム構築では、コンテナの単位で機能を開発し、コンテナ間の連携で機能追加します。できるだけ既存のアプリケーションへ手を加えずに、新たな機能を既存機能と連携させる構成をとることで、機能追加やアップデートに伴う業務影響を小さくすることを考慮します。コンテナの単位でアプリケーションをデプロイすることで、各コンポーネントの責任業界が明確になり、各々の責務で更新や機能追加に対応できるようになります。
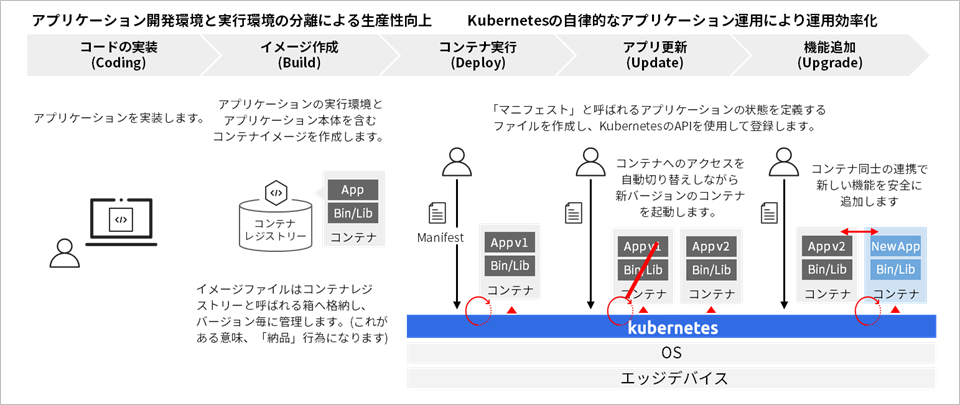
第4章 レッドハットMicroShiftを用いてKubernetesを活用したシステム構築を実践する
それでは、Kubernetesをしたシステム構築を実践してみましょう。なお、本記事では、具体的な手順でなく、ポイントを凝縮して解説します。手順は以下の順番でGitリポジトリーをご参照ください。
AGX Orin側 対応の流れ
Gitリポジトリー: https://gitlab.com/yono1/microshift-orin-dev.git
1. Orinのセットアップ
2. MicroShiftのインストール
3. NVIDIAのNGCからRivaをダウンロード
4. Riva APIサーバーのコンテナイメージのビルド
5. Riva APIサーバーのデプロイ
6. Riva APIサーバーのクライアントアプリのコンテナイメージのビルド
7. クライアントアプリのデプロイ
ロボット側 対応の流れ
Gitリポジトリー: https://gitlab.com/yono1/picar-meets-k8s
1. ラズパイのセットアップ
2. MicroShiftのインストール
3. ロボット制御アプリのコンテナイメージのビルド
4. ロボット制御アプリのデプロイ
本記事では、Kubernetesとしてレッドハット社が開発を推進するオープンソースの「OpenShift」のエッジデバイス向けであるMicroShiftを使用します。MicroShiftは、KubernetesとOpenShiftの軽量化を図り、160MB程度のバイナリーサイズのシングルバイナリーにより提供される軽量版OpenShiftです。MicroShift自体のライフサイクル管理はsystemdが担います。そして、MicroShiftが起動すると必要なコンポートがコンテナとして自動デプロイされ、クラスターをインストールします。これにより、Kubernetesのインストールと更新方法を簡素化でき、エッジデバイスへのKubernetesの導入や運用の障壁を低減します。なお、MicroShiftのエンタープライズ版はRed Hat Device Edge(2023年4月 Developer Previewとしてリリース)です。
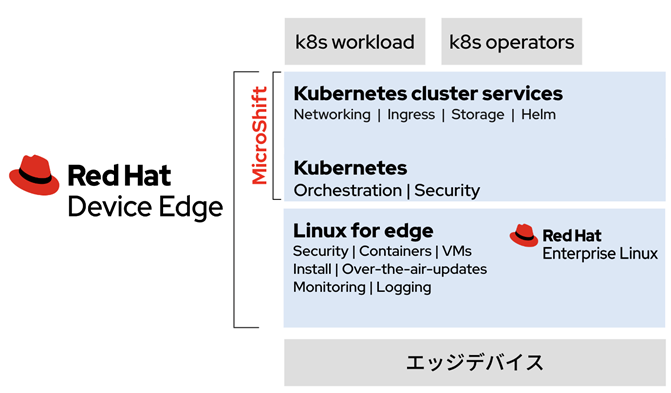
エンタープライズ版のMicroShiftのホストOSは、Red Hat Enterprise Linuxのみがサポートされますが、オープンソースのMicroShiftは、v4.8のリリースまでバイナリーリリースがあり、試験用途でDebian系のOSでも実行可能です。そのため、本記事では、お試しとして、MicroShift v4.8をAGX OrinのOS Ubuntu 20.04へインストールし、Riva APIを用いた音声認識アプリケーションを試作してみます。
注意①
MicroShiftは2023年1月のエンタープライズ版のリリースを契機にv4.8の次のリリースとして、v4.12以降の採番で開発が進められています。v4.12以降はソースコードとrpmパッケージのみリリースされているため、Debian系のOSで実行するにはソースコードからバイナリーをビルドする必要があります。v4.12以降もDebian系のディストリビューションをサポートするかについて、コミュニティーで議論中です。
注意②
MicroShift v4.8は、Kubernetes v1.21/CRI-O v1.21と古いKubernetesバージョンを使用しているため、本番環境での利用は避け、あくまでデモの実装、お試し利用程度にとどめてください。
以降より、MicroShiftを使ったエッジデバイスのシステム構築で最低限おさえておきたいポイントを記載します。
ポイント① アプリケーションの設定パラメーターの管理
MicroShiftには、ConfigMapとSecretと呼ばれる、アプリケーションの設定パラメーターや認証情報を管理するリソースがあります。これらを使うことで、アプリケーションの設定ファイルや環境固有のパラメーターの管理をKubernetesへ切り出すことができます。複数のコンテナへ共通の設定を参照させたい時に、コンテナごとに設定ファイルを管理しなくて良い点や、環境差分を吸収しながらアプリケーションのデプロイに対応できる点が利点です。
アプリケーションのソースコードでは、連携するAPIサーバーのエンドポイントURLなどの環境固有の設定をハードコーディングせずに、環境変数を使用して記述することを意識してください。そして、その環境変数をConfigMapで管理する構成とします。
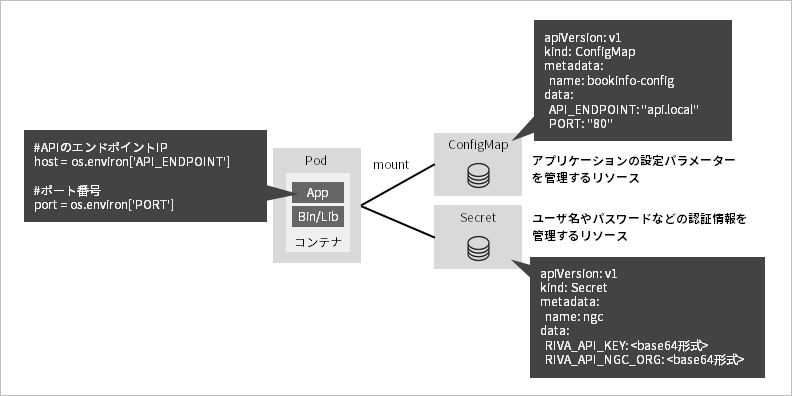
ポイント② MicroShift内のアプリケーション間連携
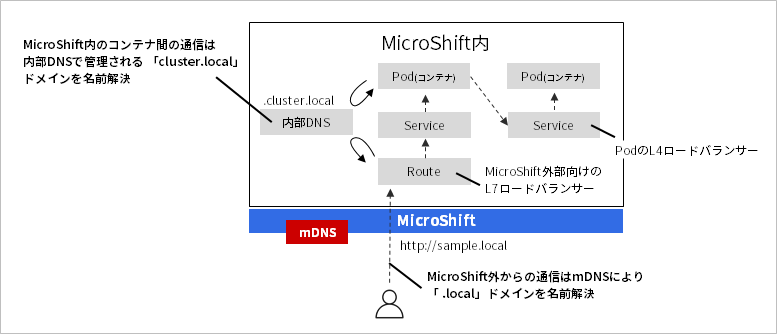
MicroShiftでは、クラスター内のアプリケーション間の連携でコンテナのIPアドレスを意識しない運用が大切です。MicroShiftをインストールすると、クラスター内にDNSサーバが起動し、クラスター内のアプリケーション間連携に使用する用途の「cluster.local」ドメインを管理します。このドメインは、コンテナのL4ロードバランサーの役割を担う「Service」リソースの名前と組み合わせて使用できます。つまり、クラスター内のアプリケーション間連携では、Serviceリソースの名前を用いて宛先のコンテナのIPアドレスを解決します。(厳密には、「Service名.namespace名.svc.cluster.local」の形式)
一方、クラスター外からクラスター内のアプリケーションへアクセスする際は「Route」と呼ばれるL7ロードバランサーを経由します。通常、Routeのドメインの名前解決には外部のDNSサーバーを別途用意する必要がありますが、MicroShiftはmDNSがビルトインされており、Routeのドメインが「.local」形式の際に、ホストOSの接続するLAN内に限り、DNSサーバー不要でRouteのドメインを名前解決できます。
まとめ
本記事では、NVIDIA Jetson AGX Orinでコンテナ/Kubernetesを使ったロボットのボイスコントロールのデモの実装方法を解説しました。クラウドネイティブは本記事で紹介したコンテナやKubernetesのことだけを指すわけではありません。これらの技術を中核に、アプリケーションのビルド、デプロイの一連の作業の自動化(CI/CD)や、専門知識不要でプロビジョニングを完了する自動化オペレーション(ZTP: Zero Touch Provisioning)など、アプリケーションのリリースサイクルを迅速化するために重要な開発・運用プロセスをエッジコンピューティングへも取り入れることが可能です。
本記事の内容が少し難しいと感じた方もいらっしゃいましたら、ぜひお問合せ下さい。体験を重ねて慣れていくことが大切で、エッジとクラウドを統合したSaaSの実現に向けて、ぜひトライしてみてください。
参考情報
無料でコンテナやKubernetesの体験ができる勉強会(もくもく勉強会)を定期開催中です。主催者のレッドハット社員もおり、気軽に質問ができます。リモート開催なので全国各地からぜひご参加ください!
関連製品情報

お問い合わせはこちら

