ChatGPT対オープンソースLLM、社内データ活用に選ぶべき大規模言語モデルを比較検証

はじめに
こんにちは、マクニカでデータブリックスのエンジニアをしている山本です。
この記事では、AIを社内利用する時に使われる可能性が高い『ChatGPT』(または、ChatGPTと社内データを保存したベクトルDB連携)と、ChatGPTをセキュリティの観点で使用出来ない企業の代替策となる『社内データでファインチューニングしたオープンソースLLM』とを比較した場合、どの程度精度に違いが出るかを比較検証した際の内容を記載します。
まず最初に、何故私がこの記事を書く事になったかですが、それはデータブリックスがオープンソースLLMであるDolly 2.0をリリースした時にまで遡ります。
Dolly 2.0は、データブリックス社が独自に作成したdatabricks-dolly-15kデータセットを使って、EleutherAIのpythiaモデルをファインチューニングしたモデルになっていて、ファインチューニングするためのコードもGithub上に公開されていました。
その後、日本語でファインチューニングされたオープンソースLLMがリリースされ、これら"オープンソースLLMをファインチューニングしたモデル"と”ChatGPTで社内利用”を考えた場合にどの程度精度に違いがあるかを確認してみようと考え、本記事の比較検証を実施してみました。
本記事の検証内容を、セミナーでもご紹介しています。よろしければ併せてご視聴ください。
目次
1.“ChatGPT対オープンソースLLM”検証内容
1‐1.検証パターン
まず、社内利用を想定した検証データは、データブリックス社作成のQiita記事から作成されたデータ(1245行)を編集して使用しました。
※JSON形式で記述されたデータでinstruction(質問)部分とresponse(回答)部分を使用しました。
検証パターンは以下の3つになります。
- ChatGPT単体での検証
ChatGPT単体への質問から得られた回答を比較します。ここで出来る事はChatGPTに送信する文章の工夫のみです。
社内利用を考えた場合、最新の情報や社内独自の内容に関する質問には答えられない可能性が高いです。 - ChatGPTと検証データを保存したベクトルDBを連携させた検証
検証データを保存したベクトルDBから質問内容に近い類似文書を検索し、その検索結果をChatGPTに送信する文章に挿入して、得られた回答を比較します。
社内利用を考えた場合、最新の情報や社内独自の情報をベクトルDBに保存して使う事で、社内独自の内容にも答えられるようになる可能性が考えられます。 - 検証データでファインチューニングしたオープンソースLLMでの検証
検証データを学習したオープンソースLLM単体への質問から得られた回答を比較します。
社内利用を考えた場合、質問文を含めて外部に送信しないなどセキュリティを高めた状態で利用できる可能性が考えられます。また、最新の内容や社内独自の情報も学習可能なため、社内独自の質問にも答えられるようになる可能性が考えられます。

≪補足≫
- オープンソースLLMのファインチューニング手法
MicrosoftリサーチがリリースしているDeep Learning最適化ライブラリであるDeepSpeedを使用しています。 - コード
データブリックス社がGithubに公開しているコードを参考にしています。- 検証データの加工: https://github.com/yulan-yan/dolly_jp
- ChatGPTとベクトルDB連携: https://github.com/databricks-industry-solutions/diy-llm-qa-bot
- DeepSpeedを使用したファインチューニング:https://github.com/databrickslabs/dolly
1‐2. 検証対象
以下が今回の検証対象になります。
- ChatGPT
- オープンソースLLM
1‐3. 検証環境
ChatGPT単体の検証環境は以下になります。
ChatGPTの場合はAI処理をChatGPTに任せるため、GPUを積んだインスタンスは不要になります。
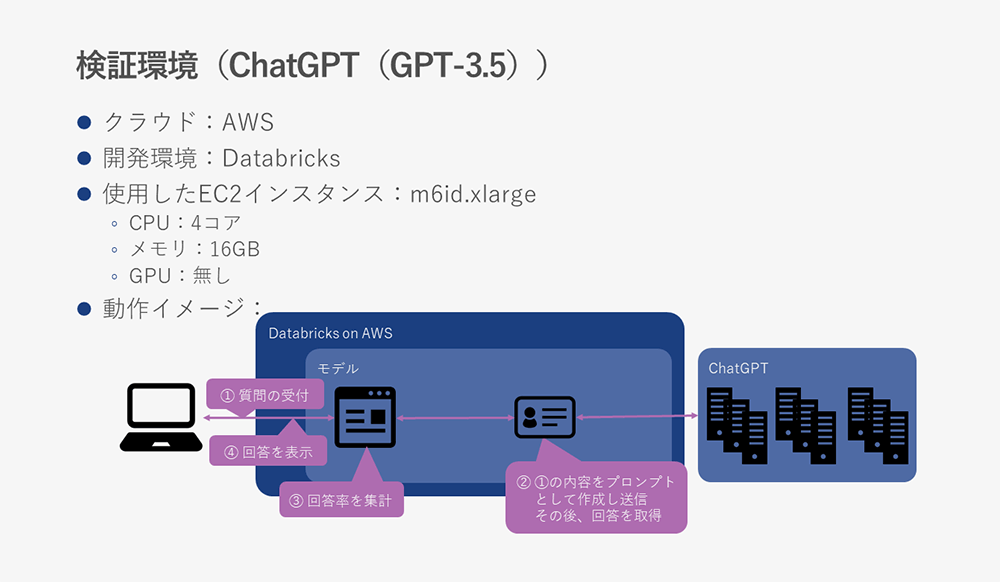
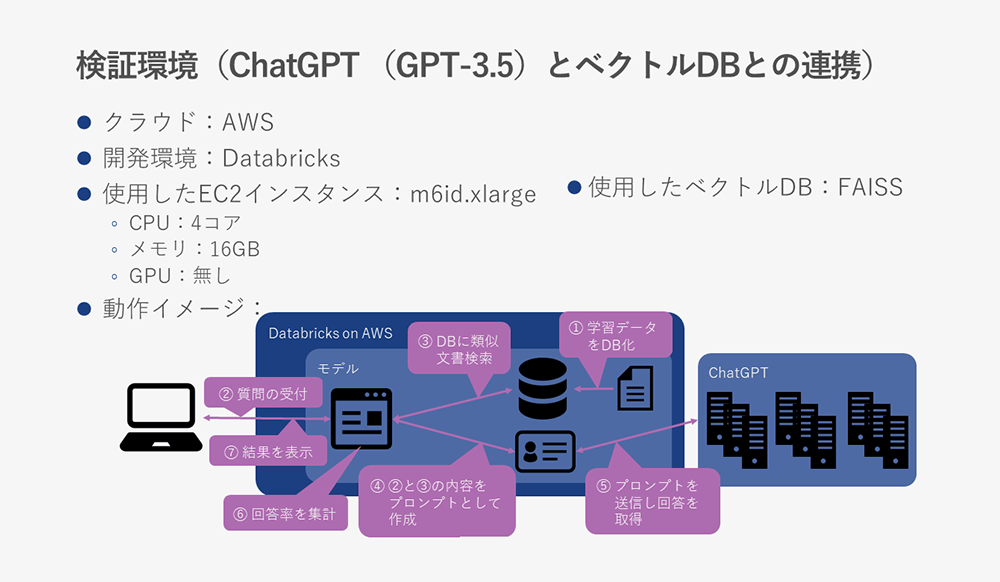
ChatGPTと検証データを保存したベクトルDBとの連携の検証環境は以下になります。
ここで使用したベクトルDB(正確には違います)は、FAISSになります。
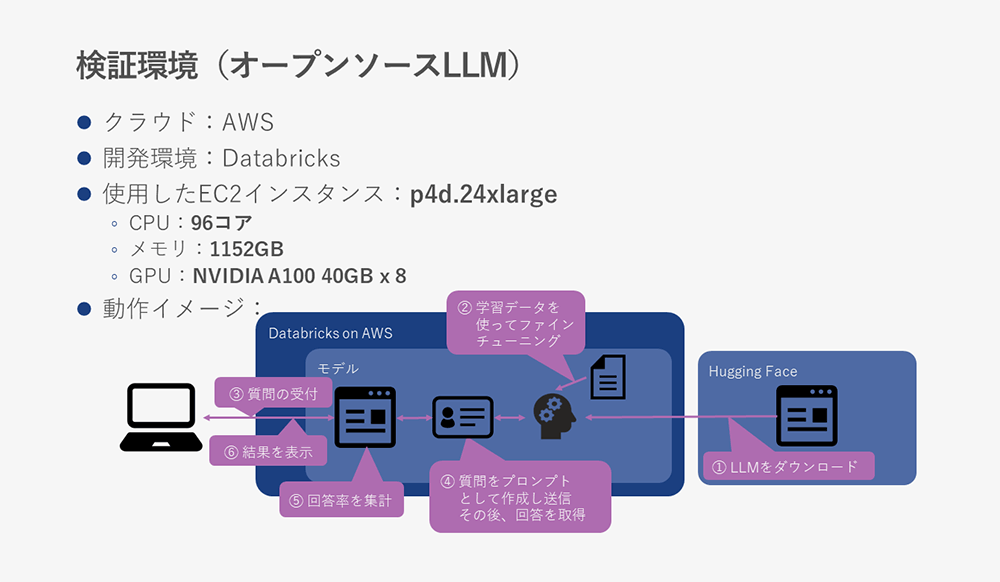
検証データでファインチューニングしたオープンソースLLM各種の検証環境は以下になります。
使用したインスタンスがChatGPTと比べるとかなり大きくなっていますが、これはGPUにNVIDIAのA100を積んだインスタンス がこのサイズのインスタンスしかなかったためになります。
GPUさえ用意出来れば、CPUとメモリはもっと少なくても問題なかったと考えています。
2.性能評価の確認方法と確認結果
性能評価の確認方法としては、LangChainのQAEvalChainを使用しました。
問題数36問に対して回答が期待する内容かどうかは、ChatGPTがQAEvalChain内で指定しているChatGPT(temperature=0に設定して独自性を排除)が判定しています。

確認結果は当初想定していたのとは異なり、「ChatGPTとベクトルDBの連携」と「日本語でファインチューニングされていないdatabricks/dolly-v2-7b」が同率で1番良い結果となりました。データセットがデータブリックスの内容であるため、相性が良かった可能性もありますが、オープンソースLLMの中ではGPUメモリを1番使用していたこともあるため、学習が最も進んだ可能性もあります。
3.オープンソースLLMの社内利用検討の参考に!思ったより苦労した点と簡単だった点
3‐1.思ったより苦労した点
- オープンソースLLMのファインチューニングにメモリが大きいGPUが必要だった点
今回は最大でも70億パラメーターのモデルまでしかファインチューニングしていませんが、これ以上のパラメーターを持つモデルだとGPUがメモリ不足となりファインチューニングが出来ませんでした。
また、検証の直前にLlama2がリリースされたため、こちらも検証の対象として検討しましたが、GPUのメモリ不足で検証が出来ませんでした。Llama2のファインチューニングにはA100 80GB以上のGPUが必要になると考えています。 - AWS上でp4d.24xlargeオンデマンドインスタンスが起動出来ない点
上記理由によりメモリが大きいGPUが必要でしたが、p4d.24xlargeのスペックが高いこともありリソース不足によりインスタンスが起動できない事が結構な頻度でありました。そのため、複数のリージョンでp4d.24xlargeの起動を試行して起動したリージョンで検証しました。幸い、検証用コードはGithubで同期出来たのでリージョンが変わっても実行に大きな支障はありませんでした。
3‐2.思ったより簡単だった点
- ファインチューニングの時間が短時間だった点
ファイルチューニングに数時間はかかる事を想定していましたが、以下のようにすべてのモデルで1時間未満の時間しかかかりませんでした。これは上述のようにGPUであるA100 40GBを8枚積んだインスタンスを使っていたこともありますが、それでも想定よりはだいぶ短い時間で処理が終わりました。- databricks/dolly-v2-7b:約39分
- rinna/japanese-gpt-neox-3.6b-instruction-ppo:約16分
- cyberagent/open-calm-7b:約23分
- 変更したパラメーターはラーニングレートとエポック数だけで充分だった点
ラーニングレートとエポック数を以下の値にするだけで充分な学習ができました。- ラーニングレート:5e-6
- エポック数:30
4.まとめ
- 社内利用としてもオープンソースLLMをファインチューニングしたモデルは期待できる
ChatGPT単体より良い結果を出すモデルが複数あり、ChatGPTとベクトルDB連携したモデルと同等のモデルもありました。
今回GPUメモリの関係で検証出来なかったLlama2など新しいモデルを使えばさらに良い結果が期待できそうです。 - メモリ量が多いGPUが複数用意出来れば、ファインチューニングは簡単
DeepSpeedを使ってもGPUメモリ不足にならない環境が用意出来ればファインチューニングは短時間で完了出来ます。
但し、参考情報にあるように今回のモデルでも40GBギリギリ近くまで使用していたモデルもあるため、今後リリースされる
モデルではA100 40GB以上のGPUが必要になると考えられます。 - 環境の変更が容易なデータブリックスなどのクラウド環境での実施が望ましい
今回の記事には記載していませんが、他のGPUでも検証をしました。結果、GPUメモリが不足したため、GPUを変更していき今回のA100 40GBを使わないと期待する検証が出来ないと分かりました。このように、環境の変更が必要な時に直ぐに変更出来るのがクラウド環境の良いところなので、少なくとも手法が確立するまではクラウド環境で実施した方が良いと感じました。
5.(参考情報)ファインチューニング時の状況とGPU使用率とGPUメモリの使用状況
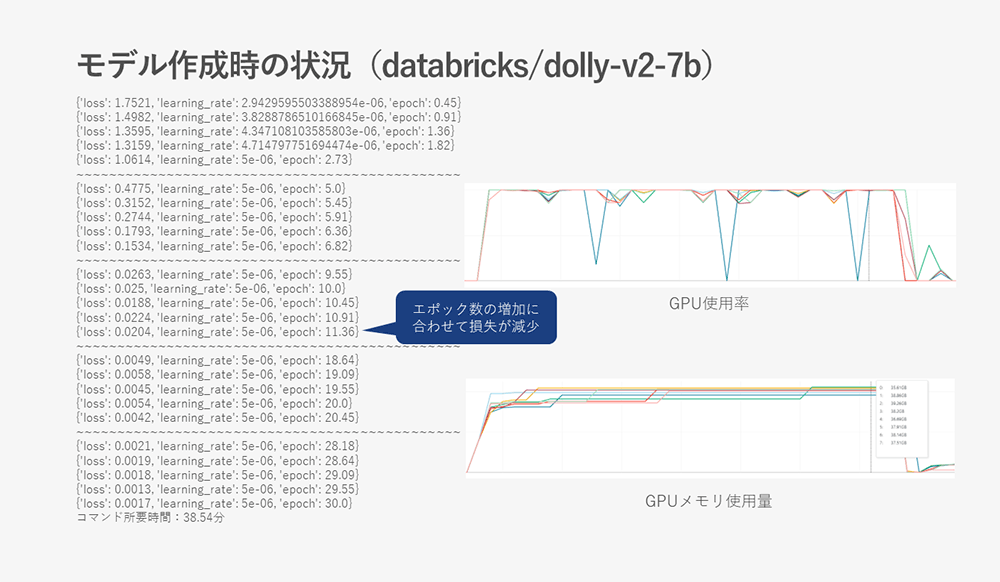
以下にファインチューニング時の学習状況とGPU使用率とGPUメモリの使用状況のスクリーンショットを残しておきます。
- databricks/dolly-v2-7b
GPUメモリの使用量が39GBを超えているものがあり、GPUメモリ的にはギリギリの状況である事が分かります。
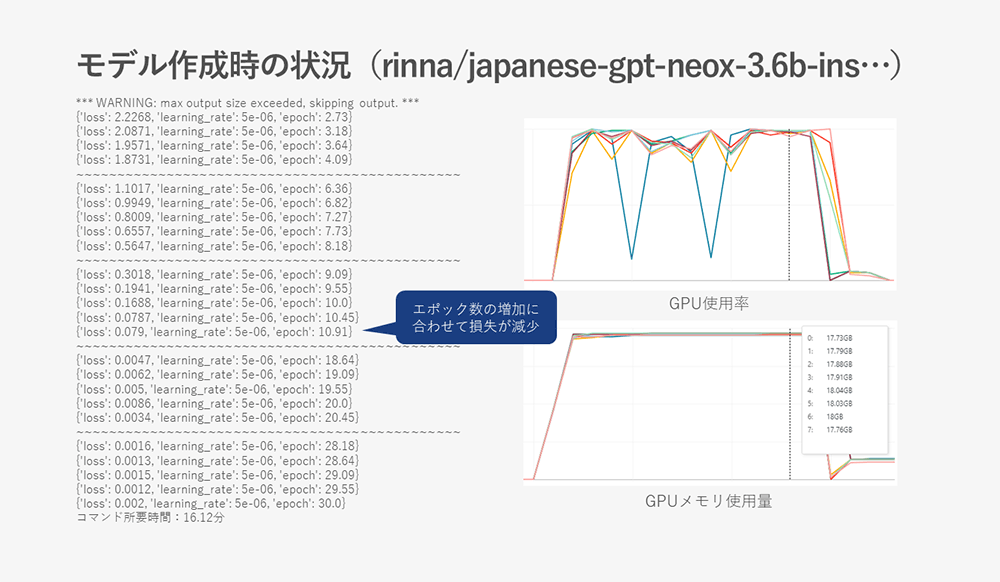
- rinna/japanese-gpt-neox-3.6b-instruction-ppo
他に比べてパラメーター数が半分近いモデルのため、使用するGPUメモリも少ない事が分かります。
- cyberagent/open-calm-7b
同じ70億パラメーターのモデルでも使用するGPUメモリが少ない事が分かります。このあたりが結果の違いに影響を与えている可能性も考えられます。

この記事が皆さまのLLM活用の一助になれば嬉しいです。
本記事の検証内容を、セミナーでもご紹介しています。よろしければ併せてご視聴ください
お問い合わせ・資料請求
株式会社マクニカ Databricks 担当
- TEL:045-476-2010
- E-mail:databricks-sales@macnica.co.jp
平日 9:00~17:00