徹底比較!Hadoopのデメリット「処理の遅さ」「複雑さ」を解消する『現代版DWH(データウェアハウス)』の実力

はじめに
近年、国際的なデジタルデータの量は飛躍的に増大しており、今後もさらなる増加傾向にあります(図1)。そんな中、オンプレミス環境やクラウド環境で発生する様々なデータは、システム運用視点だけでなくビジネス利活用視点でも注目されており、企業内で分析を行うデータアナリスト・サイエンティストにとって大規模データというのは身近なものになりつつあります。
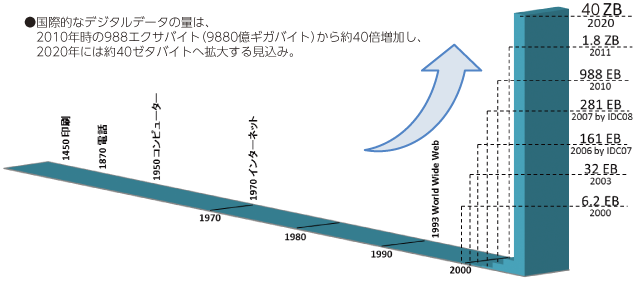
(出典:https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h26/html/nc131110.html)
データ量の増加とともに問題となるのが定期的なバッチ処理やデータ分析時に発生するデータ処理時間です。
データ量が小さいうちはあまり問題になりませんが、データ量が増えると処理時間が大幅に増加するため、大規模なデータをいかに現実的な時間で処理し、業務を成立させるかが重要になってきます。そういった場面で力を発揮していたのがApache Hadoop(以後、Hadoop)と呼ばれる分散処理フレームワークです。
このHadoopは複数台のサーバーを利用することで処理時間を短縮することが可能で、特にバッチ処理の高速化に大きな効果を発揮してきました。しかしHadoopを利用して実際にシステムを構築・運用すると、その「複雑さ」や「リアルタイム処理の遅さ」によって、運用面で負担がかかることが見えてきました。
本記事ではHadoopのメリットとデメリットを押さえつつ、その進化系である現代版データウェアハウス(以後、DWH)についてご紹介します。
※本記事ではHadoopやリレーショナルデータベース(以後、RDB)について扱っていますが、決してHadoopやリレーショナルデータベースなど従来の方法を否定するわけではありません。特性をきちんと理解し、それぞれの技術を適材適所で利用することの必要性をご紹介できればと思います。
目次
1.Hadoopとは? RDBとの違いから見るメリット・デメリット
そもそもHadoopとはどのようなメリット・デメリットがあるのでしょうか。
この章では広い分野で利用されているRDBと比較しながらHadoopのメリット・デメリットを見ていきたいと思います。
① Hadoopのメリット
Hadoopには様々なメリットがありますが、代表的なものとして以下が挙げられます。
・様々なデータタイプに対応している
様々なデータタイプを取り扱うことができる、これがHadoopのメリットの中でも非常に重要なものです。
これまでRDBでは例外を除けば構造化データしか取り扱うことができませんでした。しかしHadoopは非構造化データ(動画など)、半構造化データ(XMLファイルなど)、構造化データといった多様なデータ形式を格納する機能があります。データを格納する際に、定義済みのスキーマに対して検証する必要はありません。むしろダンプするデータの形式は不問で、ニーズに応じて任意のスキーマに適合されるため、同じデータを使用して異なる知見を得るという柔軟性が得られます。
・様々な言語で処理を書ける
HadoopはJavaで書かれたフレームワークのため、Javaで処理を記述するのが最も一般的です。
それ加えてHadoop Streamingという仕組みが提供されており、Java以外にもRuby、Perl、Python、PHP、Bashなど標準入出力を持つ言語であればあらゆる言語でHadoopの処理を書くことができます。
・スケールアップによる増強が容易
Hadoop登場以前は非常に難易度が高かった分散処理が、Hadoopの登場によって一般的な企業であっても扱える技術となりました。この功績は非常に大きく、分散処理が扱えるようになったことで、これまでは処理しきれなかった大量のデータが活用されるようになり、そこからビッグデータやデータ分析の世界が広がったと言えます。
そして1台のサーバーでは現実的な時間で処理できなかった大規模なデータ分析が、現実的な時間で処理できるようになり、企業としても大幅なコスト削減にもなりました。
・オープンソース実装
オープンソースであることもHadoopのメリットです。
近年、米国の大企業を中心に顕著なのが、オープンソースなソフトウェアの利用です。大規模データを扱う企業ほどデータ基盤技術にオープンソースを使っているかどうかを厳しくチェックするため、クローズドで独占的な自社技術で囲い込むのではなく、オープンソース化を進めていくほうがデータ分析市場で優位なポジションに立ちやすくなります。
いまや基盤技術のオープンソース化は顧客企業が求める重要な条件のひとつになりつつあり、オープンソース実装は必須要件となっています。
② Hadoopのデメリット
次にHadoopのデメリットを挙げてみましょう。
・リアルタイム処理に向かない
Hadoop はそもそも分散処理を実行するためのオーバーヘッドがあるため、RDBでも簡単に処理できるような小さなデータ処理の場合はHadoopで処理する方が圧倒的に時間がかかるケースがあります。
またディスクに対する頻繁な読み書き処理もあるため、リアルタイム処理を苦手としています。
・データの更新・変更ができない
Hadoopはデータの更新機能を実装せず、入力したデータを整理・変換して、別のデータを出力するという処理モデルに限定しています。
もっとも、それでは使い勝手が向上しない部分もあるので、徐々に更新処理が可能な仕組みも導入されてきていますが、それでもHadoopは更新が苦手という事実は変わりません。
・データのガバナンス・セキュリティを細かく制御できない
Hadoopはテーブルの行・列レベルの高粒度のセキュリティとガバナンスに対応することが難しいというデメリットがあります。
・複雑で導入時のハードルが高い
Hadoop は低レベルの Java ベースのフレームワークであり、エンドユーザーが作業するには複雑で困難なアーキテクチャになっています。
Hadoop アーキテクチャには、セットアップ、保守、およびアップグレードに関する重要な専門知識とリソースが必要になる場合もあり、運用における大きなデメリットとなりえます。
・頻繁なディスクI/Oが発生してしまう
Hadoop は分散ファイルシステムによってディスクI/Oを分散させることには成功しました。
しかし、ディスクに対する頻繁な読み取りと書き込みが発生することに変わりなく、Apache Spark などの可能な限りメモリ内にデータを格納して処理することを目的とするフレームワークと比較すると、時間がかかり非効率な面があります。
ここまで述べてきたRDBと比較したHadoopのメリット・デメリットを表にすると以下のようになります(表1)。

2.Hadoopの代替案「現代版DWH『データブリックス』」とは?
ここまでHadoopがRDBに比べてどのようなメリット・デメリットがあるのかを見てきました。
この章からは、Hadoopの進化系である「現代版DWH『データブリックス』」について見ていこうと思います。データブリックスは、サンフランシスコに本社を置くDatabricks社が提供するクラウドデータプラットフォームであり、DWHとデータレイクの最良部分を統合することから「レイクハウス」と呼ばれています。
Hadoopには多くの利点がありますが、処理の各段階間のディスク書き込みに依存するため、リアルタイムのデータ処理では効率的ではありません。そこで登場するのがこのデータブリックスです。
データブリックスはデータ処理にApache Sparkを利用しています。Apache Sparkは、メモリ内のデータストレージを使用してHadoopのリアルタイム処理の課題を解決した分散型データ処理エンジンです。Hadoopのサブプロジェクトとして開始されましたが、独自のクラスターテクノロジーを使用して、現在では高いシェアを誇ります。
データブリックスはApache Sparkの優れたデータ処理機能を利用し、それに加えて処理アルゴリズムについては、SQLクエリ、ストリーミング、機械学習、グラフをサポートする独自のライブラリを使用して利便性・運用の容易さを大きく高めています。
3.Hadoopと現代版DWH『データブリックス』の比較
Hadoopとデータブリックスの比較にあたり、まずはApache Sparkの特徴をご紹介します。
Apache SparkではHadoop同様に様々なデータタイプを取り扱えます。これはデータの取り込みも通常のファイルアクセスのようにデータ保管場所のファイルデータを読み込み、分析や機械学習を実施してデータをファイルとして保存することで実現しています。ファイル操作なので、データについては特に制約がなく、操作の自由度が非常に高いため様々なデータタイプを利用できるのです。逆を言えば、データに対して何でもできてしまい、データ管理はユーザー側に委ねられることになります。
実はApache Sparkを運用する上での課題がここにあります。企業などの組織レベル、もしくはエンタープライズ用途でApache Sparkを運用する場合、そのデータの品質の管理が非常に困難になるのです。たとえば、頻繁なデータコピーが発生する、データアクセス権限がファイルやフォルダ単位、データ破損の検知機構がない、派生データから上流のオリジナルデータをたどれず、データが正しいかの正当性判断が難しいなど、実際の運用での課題は多岐にわたることになります。
Apache Sparkは、自由度やオープン性が高い反面、こうしたデータの品質管理における課題を運用等で補足し構築管理することが求められます。これらを解決したのがデータブリックスです。
データブリックスはApache Sparkプラットフォーム上に、RDB・DWHの機能を提供する論理レイヤーが上座する構成をとっています(図2)。
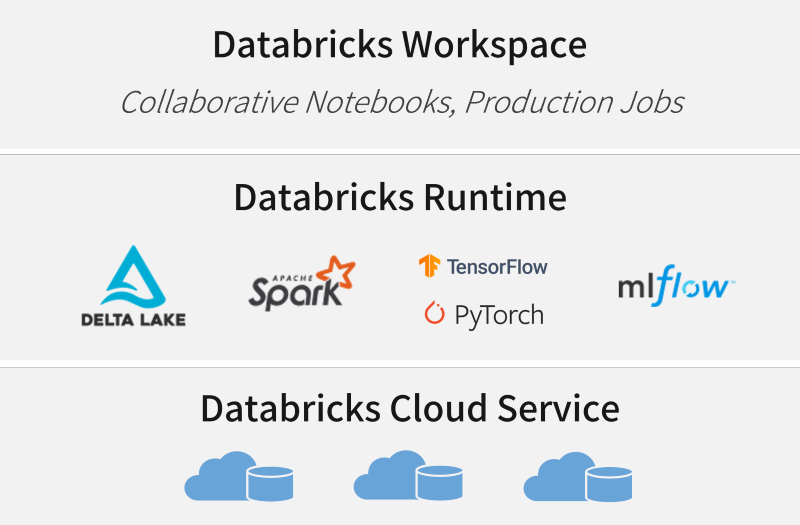
(参考:https://www.databricks.com/jp/spark/comparing-databricks-to-apache-spark)
これにより、ユーザーから見るとApache Spark上のデータをRDBの品質・ガバナンス・セキュリティ・パフォーマンスで利用できるプラットフォームとして機能することで、先にあげた課題が解決されます。これらの特徴を、1章で示したHadoopとRDBのメリット・デメリットと比較すると以下のようになります(表2)。
このようにデータブリックスでは、HadoopとRDBそれぞれのデメリットまでカバーするかたちで、すべての種類のデータ(構造化データおよび非構造化データ)を高信頼、高速に利用でき、一貫のデータガバナンスを適用し、機械学習、SQL分析、BI、ストリーミングなどすべてのユースケースを実現できるのです。

4.まとめ
本記事ではHadoopがRDBに比べてどのようなメリット・デメリットがあるのか、そしてその課題を解決するデータブリックスとはどのようなものかについて述べてきました。
Hadoopは分散型のデータ処理エンジンとして大きな功績を残しましたが、運用の複雑さやリアルタイム処理などに課題を持っていました。この課題の一部をApache Sparkは解決しました。現在データアナリスト・データエンジニアが幅広く使用しているApache Sparkは、高速かつ簡潔で機能豊富なAPIを備え、大規模なデータに対する処理がHadoopよりも容易に実現できるようになりましたが、一方で取り扱うデータの豊富さ・柔軟さがデータの品質管理を難しくしてしまう課題にも繋がっていました。
データブリックスはApache Sparkプラットフォーム上にRDBの機能を提供する論理レイヤーを加えることで、Hadoop・Apache Sparkのメリットを残したまま、RDBのもつデータの品質管理のメリットを合わせもつプラットフォームを構築できるようになりました。これにより、クエリ処理から、ストリーミング処理、深層学習を含む機械学習まで一つのプラットフォームで対応できるようになりました。従来では、異なるソリューションを組み合わせて実装していたことを考えれば、データブリックスを使うことで開発の生産性が圧倒的に高まるでしょう。
Hadoopからデータブリックスへの移行にご興味のある方は、実際の移行事例も交え 動画で詳しく解説していますので、ぜひご覧ください。

データブリックス詳細・お問い合わせ

参考資料
お問い合わせ・資料請求
株式会社マクニカ Databricks 担当
- TEL:045-476-2010
- E-mail:databricks-sales@macnica.co.jp
平日 9:00~17:00