- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

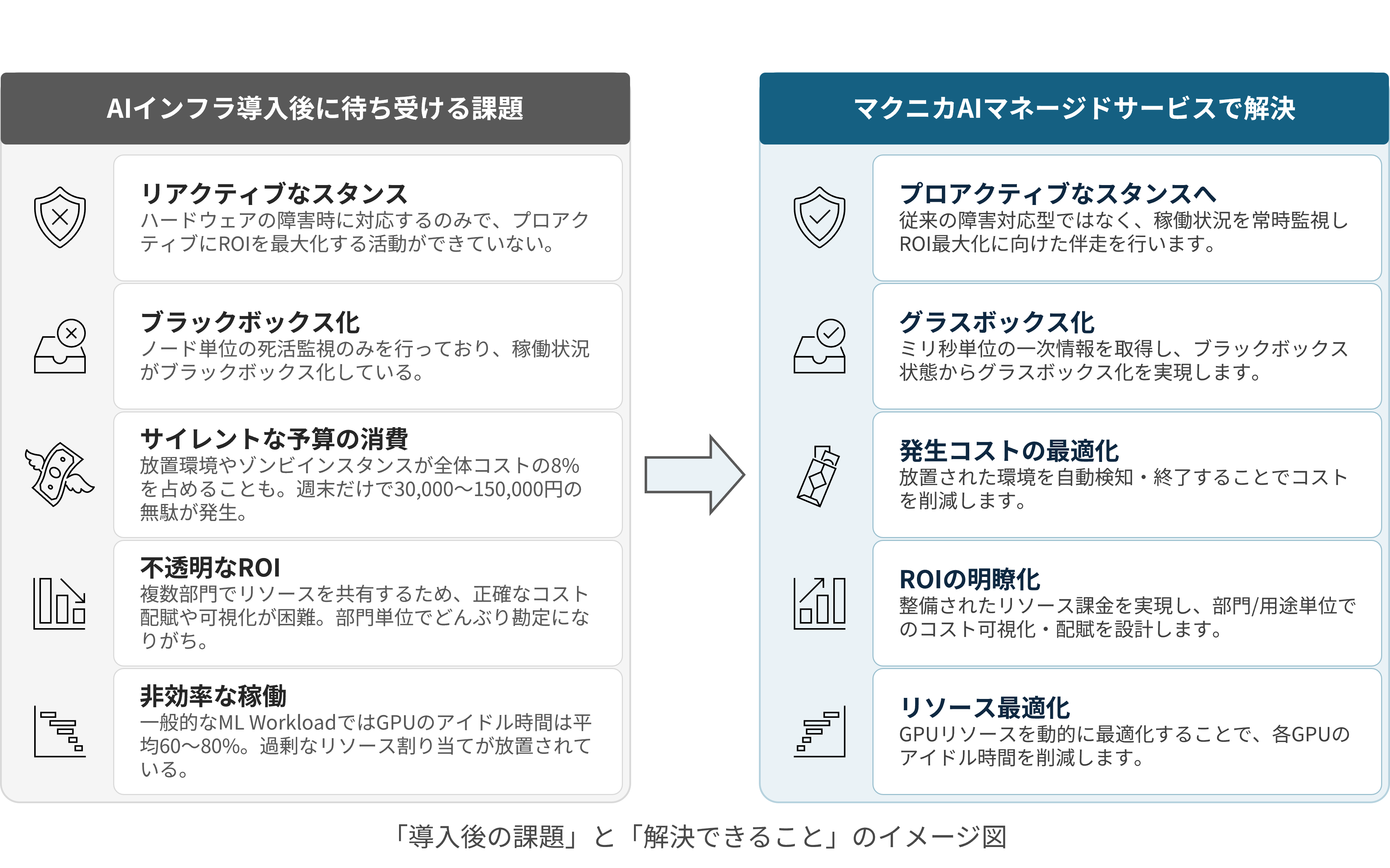
AIインフラ導入後に待ち受ける課題
リアクティブなスタンス
ブラックボックス化
サイレントな予算の消費
不透明なROI
非効率な稼働
一般的なML Workloadでは、GPUのアイドル時間は平均60~80%。過剰なリソース割り当てが放置されている。
AI Factory オブザーバビリティ マネージドサービスについて
本サービスで解決できること
プロアクティブなスタンスへ
グラスボックス化
発生コストの最適化
ROIの明瞭化
整備されたリソース課金を実現し、部門/用途単位でのコストの可視化・配賦を設計します。
リソース最適化
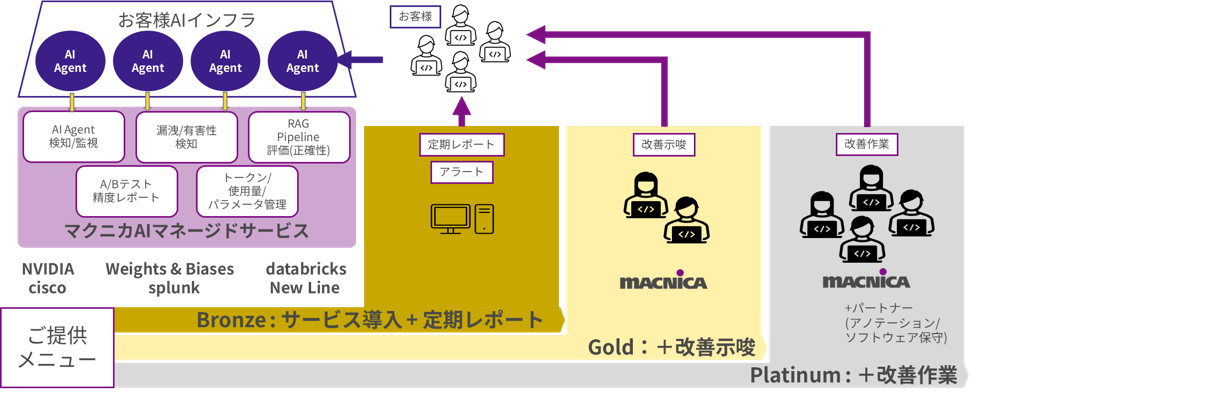
サービスイメージ
お客様のご状況に応じて、サービス導入+定期レポート/ 改善示唆 / 改善作業 を段階的に提供することで、お客様のAIインフラの安定した本番運用を実現いたします。
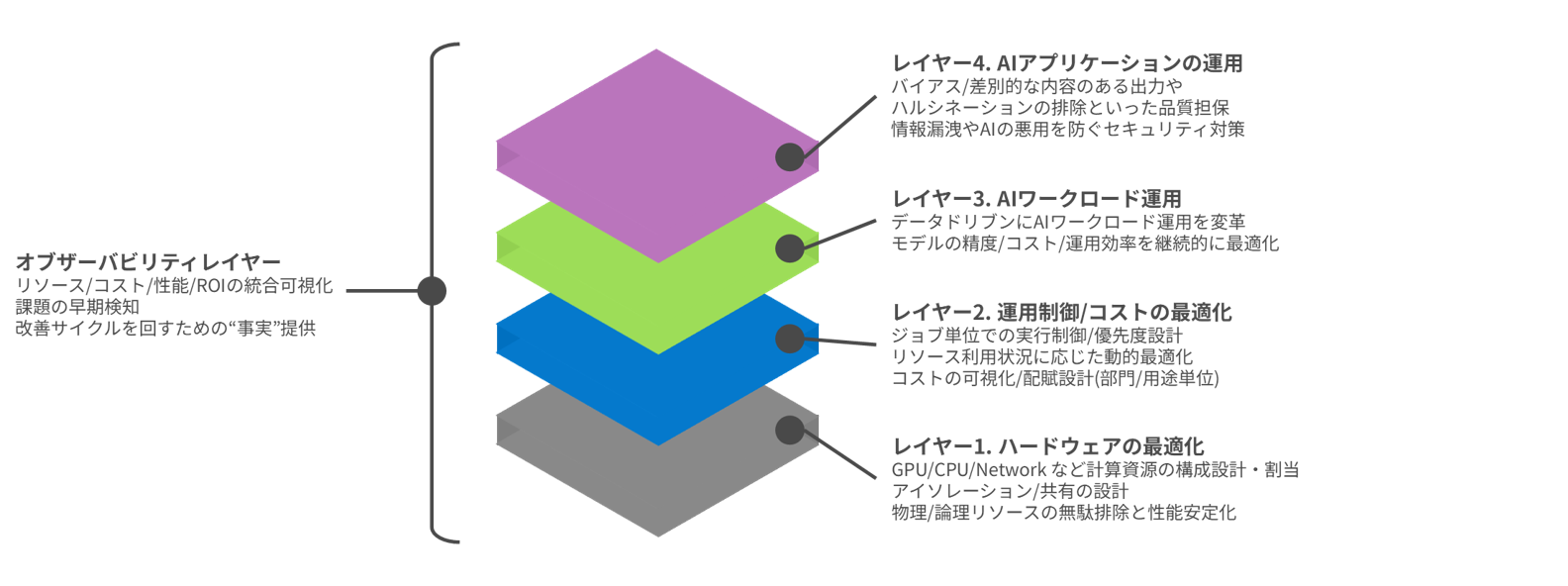
サービスの構成要素
各レイヤーから1次情報を取得しつつ、それらを統合管理することでオブザーバビリティを高め、相互に連携する単一のエコシステムの構築/マネージドサービスを提供いたします。
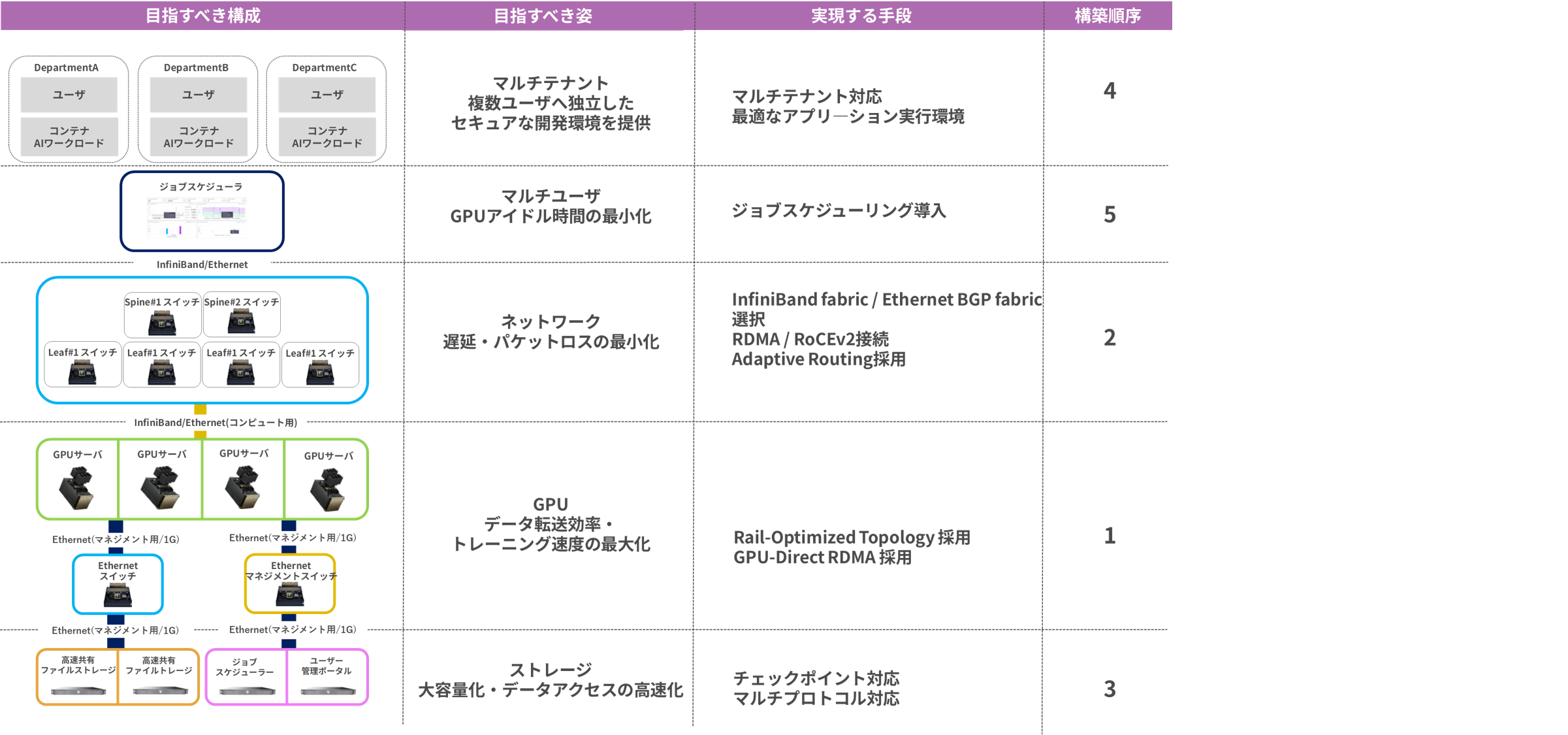
レイヤー1でのご支援内容詳細
ユースケースに適した基盤を選定/構築し、ユーザー利用を考慮したソフトウェア構築まで設計/実装いたします。どのGPU/サーバー/ソフトウェアを選び、どのようなネットワーク構成とするべきなのか、そしてそれらをどのように構築するのかは専門的な知識が必要なので、国内でGPUクラスターの導入/構築実績が多数あるマクニカから、専門的にサポートさせていただきます。以下のようなアーキテクチャーがGPUクラスターの一例になります。
レイヤー2でのご支援内容詳細
GPUリソースを動的に最適化することで費用対効果を最大化しつつ、 部門/用途単位でのコストの可視化・配賦を設計いたします。お客様の中には、GPUの利用率が可視化できておらず、用途に合わせたGPUの使い分けができていなかったり、GPUリソースを過剰に占有したりすることが原因で、他の人が使いたいときに使えず、稼働率が上がらないような状況となってしまっています。動的にGPUリソースを最適化することにより、これら課題を解決いたします。
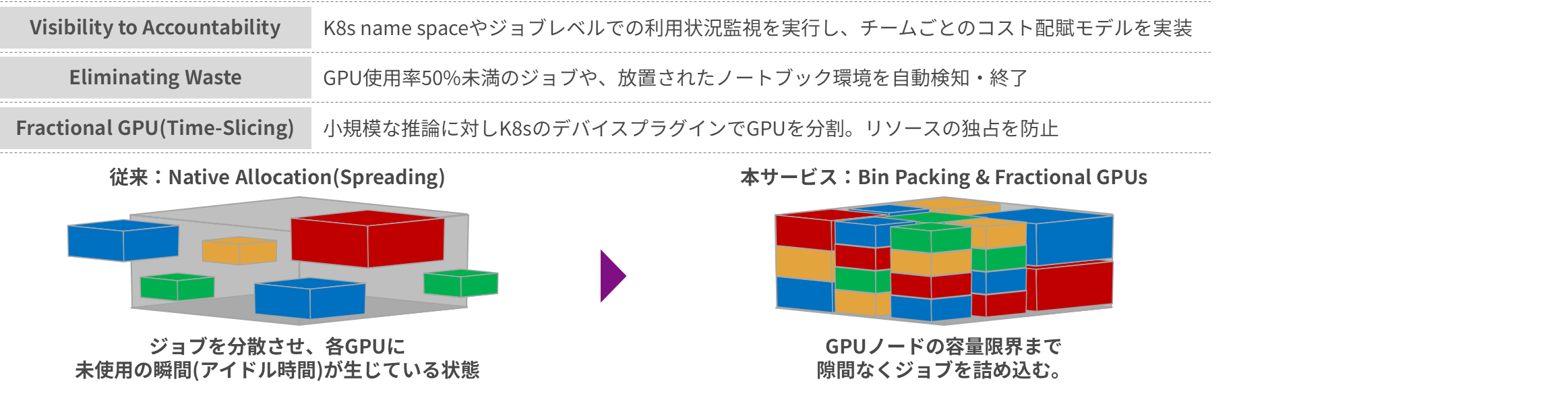
レイヤー3でのご支援内容詳細
AIワークロード運用をデータドリブンに変革し、モデルの精度/コスト/運用効率を継続的に最適化いたします。属人化しがちなモデル性能の評価や改善の判断を定量的に可視化/最適化することで、再現性のある運用プロセスを確立することができます。

レイヤー4でのご支援内容詳細
Weights & BiasesやAI RedTeamingサービスを活用し、Safetyリスク(品質)とSecurityリスクを評価し、改善のための示唆出しをさせていただきます。AIアプリケーションは構造が複雑に入り組んでいるため、デバッグが難しく、品質改善の難易度が高くなっております。加えて、外部からの攻撃によるセキュリティリスクも増大しています。これらに対して、プロフェッショナルからの専門的なコンサルティングを実施させていただくことで、より高品質でセキュアなアプリケーションを提供することが可能になります。
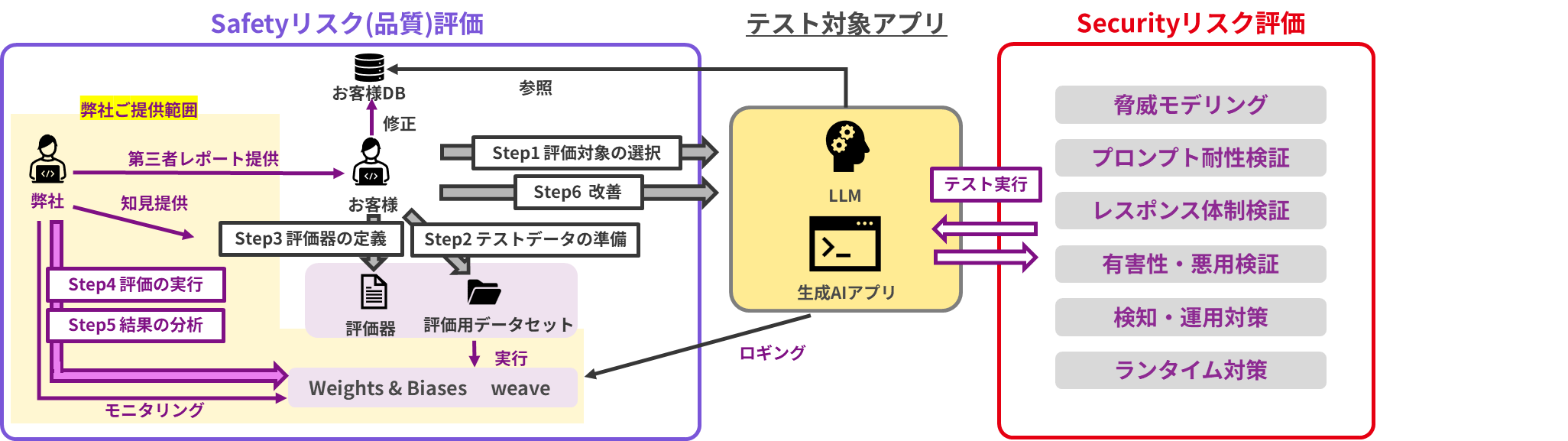
オブザーバビリティレイヤーでのご支援内容詳細
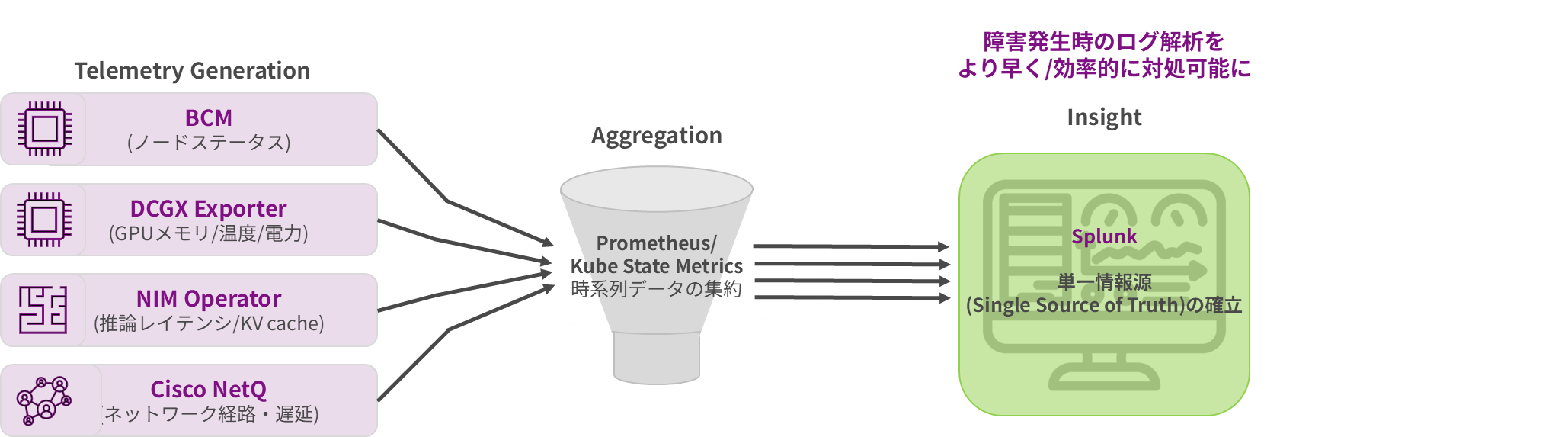
サイロ化されたメトリクスを統合 / 全階層をグラスボックス化し、AI駆動型インシデント管理を活用することで問題発生を予測し、デジタルサプライチェーン全体をプロアクティブに防御します。様々な情報を単一の情報源で把握できるようになることで、障害発生時のログ解析をより早く・効率的に対処できるようになります。
まとめ
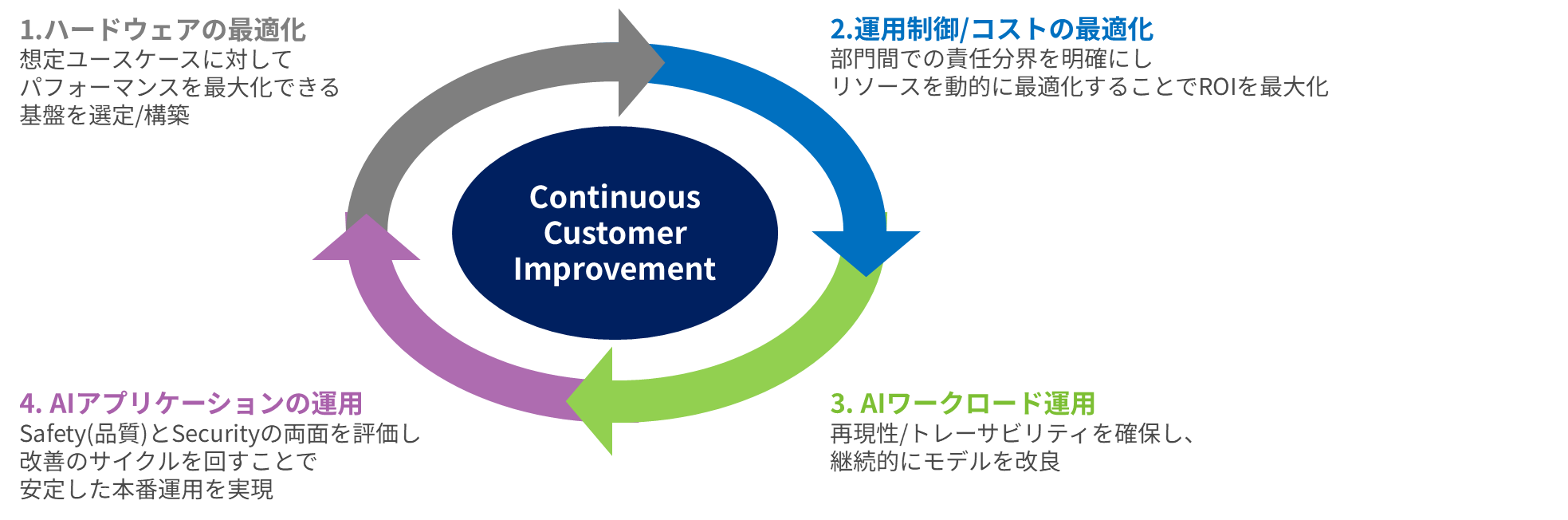
また、情報システム部門のご担当者様にも安心して導入いただけるよう、ヒアリングから運用改善まで5つのステップで段階的にご支援いたします。各ステップでの作業内容を明確化し、円滑な合意形成と着実な本番稼働を実現します。
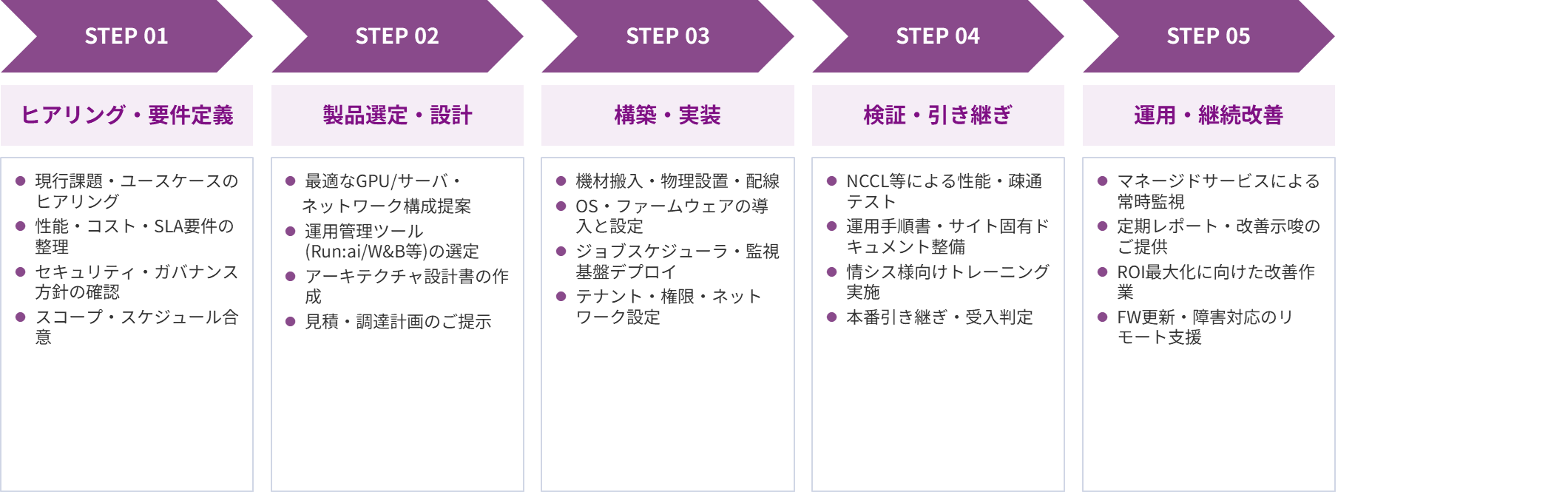
導入したAI基盤の一次情報を取得し、「安定した本番運用に向けての定期的なヘルスチェック」および「システムの改善示唆と改善作業のコンサルティング」をおこなう点が本サービスの特長です。
お問い合わせはこちら

