- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

AI FactoryにおけるGPUクラスターの位置づけ
*本ページはAI Factoryにおける、ハードウェアインフラの内容と一部ソフトウェアを深堀しているページとなっております。
AI Factoryを導入するにあたって、GPUクラスターは非常に重要なインフラの検討要素です。主にGPUサーバーがあり、GPU間を高速に通信させることのできるマルチノード環境を実現するネットワークを用意する必要があります。またGPUクラスターの構成要素としては高速で且つAIの要件を満たすストレージや、GPUの利活用を最大化させるためのソフトウェアが必要になります。本ページではGPUクラスターの構成要素と、各要素について深堀をしていき、GPUクラスター導入を検討している皆様へ参考となる情報を提供します。
GPUクラスター 目指すべき姿と課題
LLMやAIモデル開発の機運が高まる昨今、GPUサーバーを複数台利用するマルチノードGPUクラスターの構築需要が増えています。GPUクラスターは、モデルの学習と推論を高速に処理し、期待するアプリケーションの応答速度を満たす必要性があります。本ページではマルチノードGPUクラスターのインフラレイヤーからジョブスケジューリング、クラスター管理といったソフトウェアまでの目指すべき姿と課題について紹介しています。
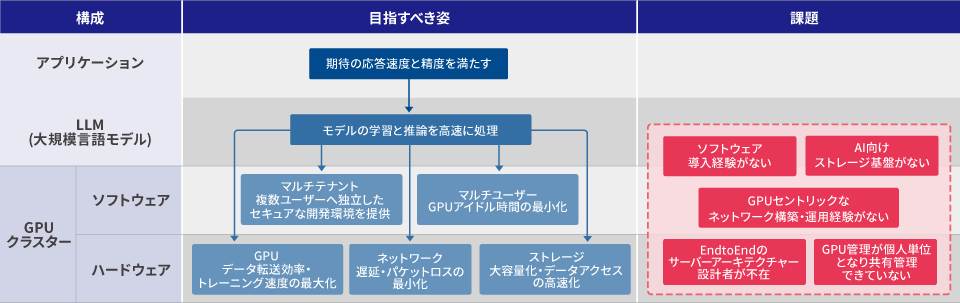
GPUクラスター システムアーキテクチャー概要
下図は理想的なGPUクラスターの全体像となっています。
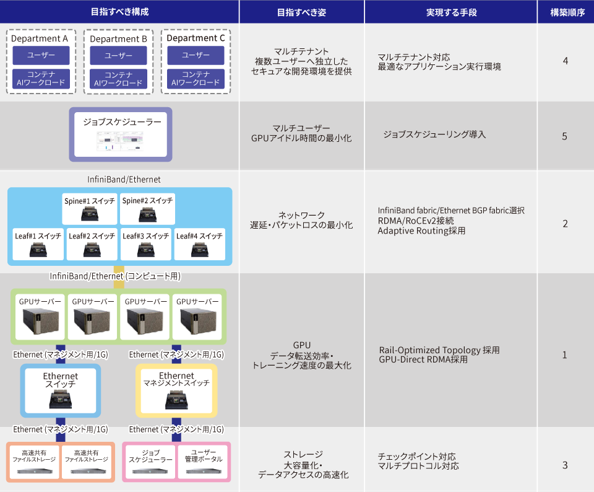
マルチノードGPUクラスターは、GPU・ネットワーク・ストレージのインフラ構築だけでなく、ユーザー利用を考慮したソフトウェア構築までを設計、実装をして初めて完成します。大別するとマルチGPUノード(Compute)、各GPUノードを接続するComute Network、高速で大容量なストレージ、GPUや各機器を管理するミドルウェアのソフト群などに分けられますが、これら各要素を最適に設計しなければGPUが持つ能力を最大限活用することができなくなってしまいます。
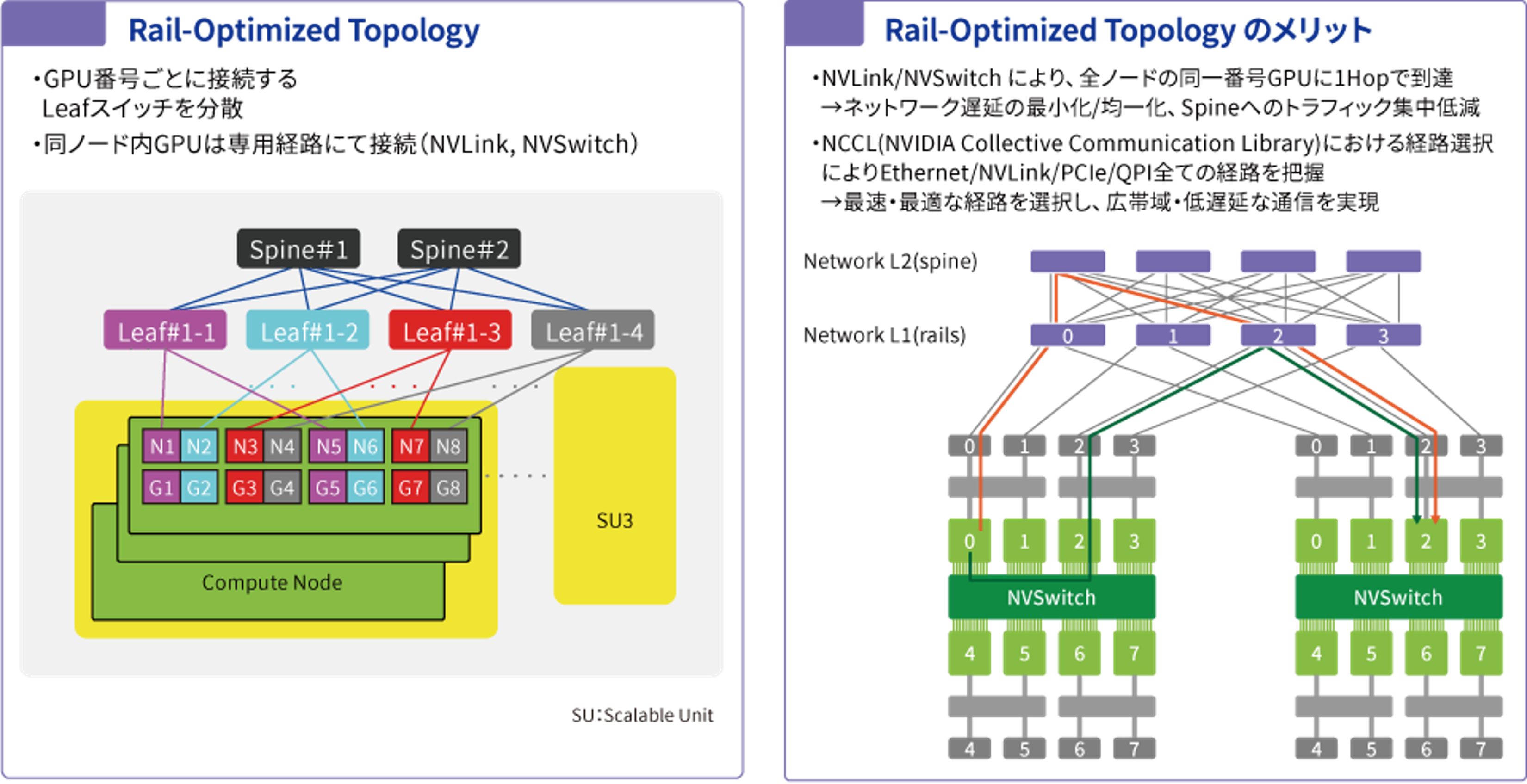
GPUデータ転送・トレーニング速度の最大化
Rail-Optimized Topology
マルチノードGPUの環境においては複数ノードにまたがるGPUをいかに遅延なく高速で活用することできるかが重要になっており、Rail-Optimized-Topologyの考え方が用いられています。マルチノードGPUクラスターではノードをまたいだGPUの接続についてはGPU番号ごとにlefスイッチを分散させ、1Hopで到達できるような構成で設計します。これにより、ネットワーク遅延の最小化/均一化を実現しspineへのトラフィックの集中を低減できます。(同ノード内のGPUはNVLink,NV switchによる専用経路接続)。またNCCLにおける経路選択によって、Ethernet/NVLink/PCIe/QPIのすべての経路を把握し、最速、最適な経路で広帯域、低遅延な通信を実現しています。
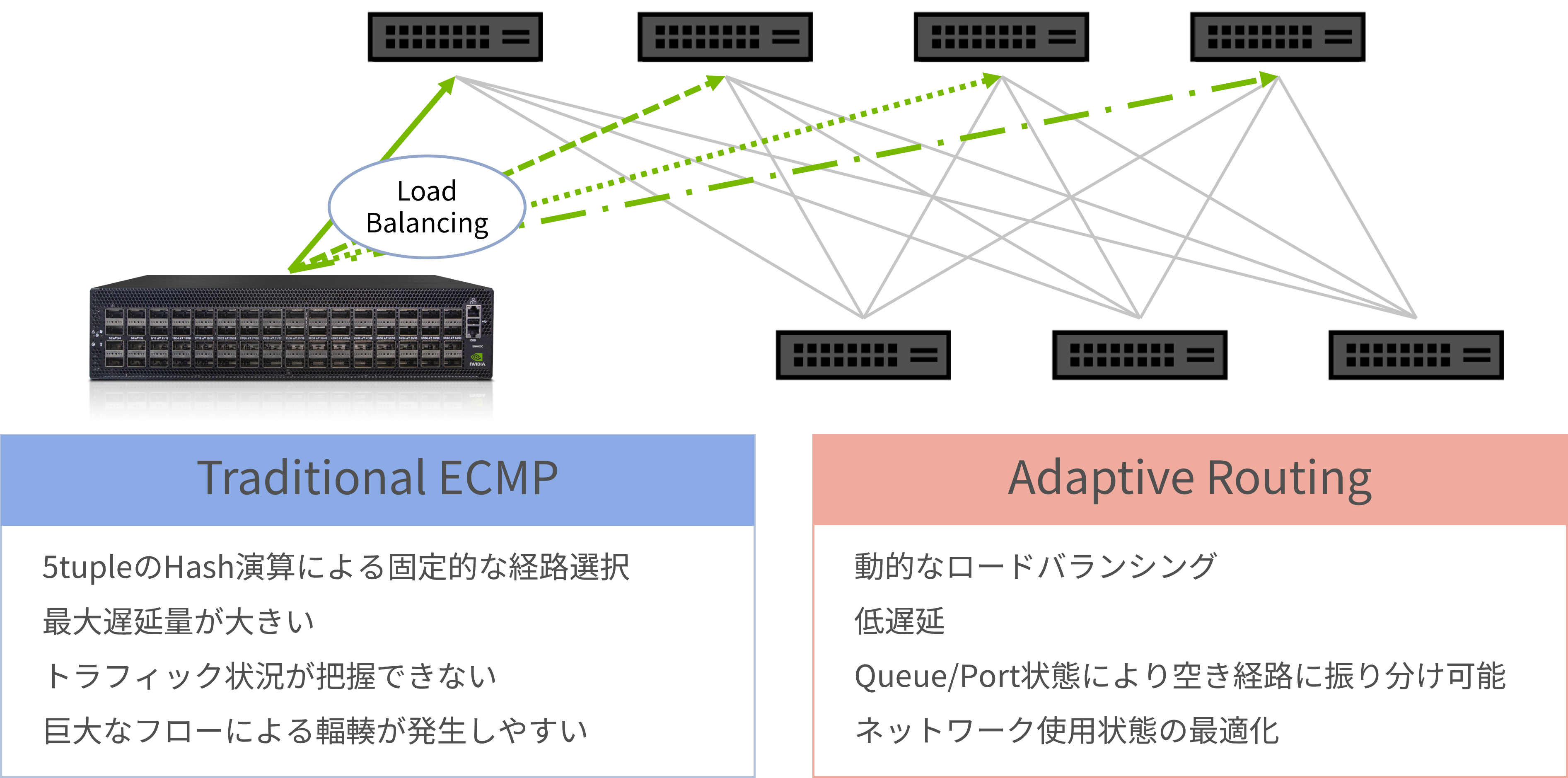
Adaptive Routing
二つ目のポイントとしてAdaptive Routingという考え方が重要になってきます。
- Adaptive Routingは、ネットワーク内の経路状況をリアルタイムに監視し、輻輳(混雑)や障害が発生しているルートを自動的に回避し、最適な経路へと動的に切り替える仕組みです。
これにより、従来の負荷分散方式(ECMP)と比較して、通信遅延の低減やスループット向上、ネットワーク全体の安定性向上を実現できます。
一方、ネットワークの品質を左右するのはルーティングだけではありません。ソフトウェアレベルでの輻輳制御・帯域制御の実装も不可欠です。AIのワークロードにおいてはアプリケーションが生成するトラフィックの種類や量が多様化し、単に物理的な帯域を増やすだけでは効率的な運用が難しくなっています。
Adaptive Routingによってネットワーク経路の最適化を図りつつ、ソフトウェアレベルの制御でトラフィックそのものの動きを調整することで、ネットワーク全体の安定性と効率性を高いレベルで確保できます。この “経路の最適化 × トラフィックの最適化” の両輪が、現代の高密度・高負荷環境におけるネットワーク設計では非常に重要となっています。
ジョブスケジューリング・クラスター管理
AI ワークロードは学習、推論、実験管理など多様な処理が混在し、GPU リソースを大量に消費します。しかし、増え続けるワークロードに対して、従来の手動オペレーションでは GPU の遊休時間やリソース断片化が発生しやすく、インフラ投資に対して十分な効率を引き出せません。
この課題に対し、Run:ai のようなジョブスケジューリング/クラスター管理ソフトウェアは、AI システムを最大限に活かすための「運用インテリジェンス」を提供します。
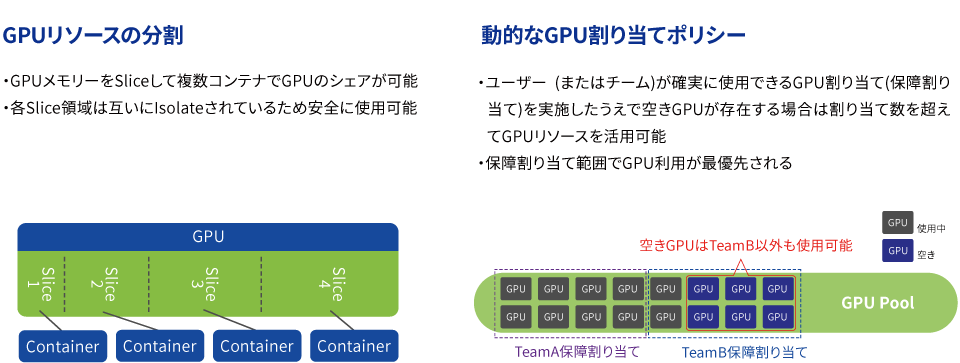
NVIDIA Run.ai
Run:ai は GPU リソースの動的な割り当てとスケジューリングを行い、GPU 集約型の AI ワークロードを効率的に実行する仕組みを提供します。
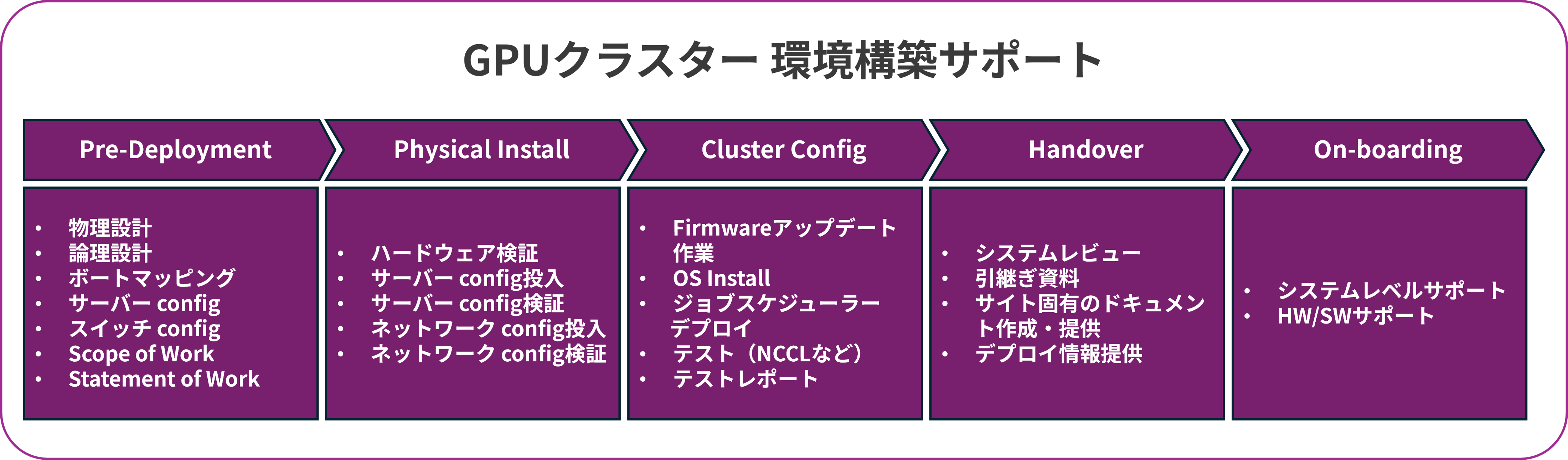
GPUクラスター 環境構築サポート
本ページを通してマルチノードGPUクラスターのシステムアーキテクチャを見ていきましたが、実際の設計ではサーバーやネットワーク機器といったハードウェア製品の知識だけではなく、これらをつなぐネットワークや、ジョブスケジューリング、クラスター管理ソフトなどの多岐にわたる専門性が必要になってきます。改めて各要素のおさらいです。
・GPUサーバーの設計・構築
ワークロードに最適なGPUの選定やGPU間の通信を最適化させるためのアーキテクチャ/トポロジーの採用。
・高速ネットワークファブリックの設計・構築
GPU性能をフルに発揮させるため、トラフィック制御やパケット経路を精密に最適化した論理設計。低遅延・高スループットを維持できるネットワーク基盤。
・高速共有ストレージの設計・構築
ワークロード特性に合わせたread/writeの中央値性能を重視したストレージ設計。GPU学習処理でボトルネックが発生しないよう、高速I/Oを確保する共有ストレージ環境。
・クラスター全体の最適化設計・構築
ジョブスケジューラ設定や可視化環境の整備により、GPUリソースの利用効率と運用性を向上。クラスター全体を俯瞰し、パフォーマンスを最大化する最適化設計と安定運用基盤を確保。
各要素を軽くおさらいしましたが実際の設計・構築ではさらに多くの要素が絡み本当の意味での性能の最適化を図るには非常に多くの分野のエンジニアが力を合わせて構築する必要があります。しかし実際にはこれほど多岐にわたるエンジニアを一つのプロジェクトで導入、運用がスタートするフェーズまで確保しておくことは多くのお客様にとって非常に困難な課題となってしまいます。また、サーバー・ネットワーク・ソフトウェアなどさまざまなレイヤーのエンジニアがプロジェクト参加するものの、各レイヤーごとのプロフェッショナルであり、End to Endで最適な設計・構築を実行できるエンジニアは少ないのが現状です。
そこでマクニカではこうしたマルチGPUクラスターの環境を構築したいというお客様に向けてGPUクラスター 環境構築サポートを提供させていただいております。物理的なハードウェアのご提案だけでなく、ハード納入前からGPUクラスター設計、構築のフェーズまで伴走し、お客様がGPU資源を最大限活用できるようサポートします。
終わりに
もしもマクニカプロフェッショナルサポートに興味があるという方や、マルチノードGPUクラスターの詳細に興味があるという方は
GPUクラスター超入門(GPUクラスター構築 超入門)により詳細を掲載しておりますのでお問い合わせください。
*本ページはGPUクラスター超入門を一部抜粋し記載しております。
関連ページ




お問い合せはこちら

