- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録

AI Factoryとは何か

AI Factoryとは、企業が「AIを点の取組みから、事業の成長を生み出す仕組み」へと昇華させるための新しいインフラと運用モデルです。 単発のPoCや個別部署のツール導入にとどまらず、データの収集からモデル開発、サービス提供までを一つの“工場”として整え、AIを継続的に生産し続けるための土台となります。
なぜ今、AI Factoryが必要なのか
生成AIや大規模言語モデルの登場により、AIは「一部業務の効率化ツール」から「事業やビジネスモデルそのものを変える戦略テーマ」へと変化しています。 一方で、現場ごとにバラバラにAIを導入していては、コストの重複やガバナンスの欠如、セキュリティリスクなどが顕在化し、スケールしないという壁に直面します。
AI Factoryは、この分散したAI投資を集約し、「全社共通のAI生産基盤」として標準化することで、投資対効果の最大化とスピードアップを同時に実現することを狙っています。 結果として、限られた予算・人材であっても、より多くのAIサービスを高い品質で展開できるようになります。
どのような成果を生み出せるのか
AI Factoryを整備することで、企業は自社データに根ざしたAIアプリケーションを、継続的かつ計画的に増やしていくことが可能になります。 例えば、顧客対応の自動化だけでなく、需要予測、サプライチェーン最適化、製造ラインの品質検査、バックオフィス業務の自動化など、複数の業務領域にまたがってAIを横展開できるようになります。
さらに、モデルの継続学習や性能モニタリングを仕組みとして組込むことで、「一度作って終わり」ではなく、環境変化やデータ増加に応じてAIの精度と価値を高め続けることができます。 その結果、売上成長やコスト削減だけでなく、意思決定の高度化や新規ビジネス創出といった、中長期的な競争優位の獲得につながります。
AI Factoryでできること
1. AIモデル・サービスの大量生産
・ 自社データを投入し、生成AI、LLM、画像認識モデルなどを短期間で学習・微調整・デプロイ可能。製造業では工場デジタルツインを構築し、生産ライン最適化を実現。
・ AIエージェントを数百・数千規模で展開し、顧客対応自動化や業務フローのパーソナライズをスケールアウト。
・ 従来の個別開発では時間がかかっていたモデル群を、工場のように並行生産し、複数部署・複数チャネルで即座にサービス化。
2. 産業・業務領域の高度化
・ AI Factoryによって、AIの開発・運用が各部門単位の実験から、全社横断で再利用可能な仕組みに進化。部門間で共通のモデル・データ・ワークフローを活用できることで、組織全体の生産性を底上げする。
・ モデル開発や推論の高速化により、既存業務の効率化だけでなく、新たなデータサービスやAI主導のビジネスモデル創出を後押し。
・ AIを「業務単位で使うツール」から「事業拡張を牽引する基盤」へと位置づけることで、企業の競争力を持続的に強化する。
3. 継続改善とROI最大化
・ 本番運用データを自動回収し、モデル再学習(データフライホイール)で精度を継続向上。環境変化にも対応したAIの長期価値を確保。
・ 全社横断でAIを展開することで、投資を分散導入から集中投資へシフトし、トークン収益や業務効率を最大化。
これらにより、AI Factoryは「AIを試す」から「AIで稼ぐ」への転換を加速します。
AI Factoryの活用シーン
AI Factoryの活用シーンは、製造業、金融、ヘルスケアなど多様な産業で、自社データを活かしたAIの継続運用が鍵となります。
製造・物流DX
・ 工場内のカメラやセンサーデータをリアルタイムでAI Factoryに集約し、設備の予兆保全、外観検査、ロボット制御を自動化。生産ライン全体のデジタルツインを構築することで、ダウンタイムを削減し、稼働率を大幅向上させる。
・ 複数工場のデータを一元管理し、品質基準の統一や最適化ルールを全社展開することで、製造プロセスの標準化と効率化を実現。
金融・サービス業
・ 顧客取引データや問い合わせ履歴を基に、パーソナライズされたAIエージェントを大量展開し、24時間対応の自動応答やリスク予測を可能に。業務担当者の負荷を軽減し、顧客満足度を向上させる。
・ コールセンター業務では、会話の感情分析や自動要約を生成AIで実行し、オペレーターの対応品質を安定化・高速化。
ヘルスケア・創薬
・ 医療画像や患者データを継続学習させ、診断支援AIを現場で活用。検査精度の向上と医師の負担軽減により、迅速な意思決定を支援。
・ 創薬プロセスでは、分子構造データや臨床試験結果をAI Factoryで分析し、化合物スクリーニングや薬効予測を高速化。新薬開発期間の短縮と成功率向上を実現。
これらのシーンで共通するのは、AI Factoryが「データ収集→モデル生産→本番運用→継続改善」のサイクルを回すことで、単発AIから事業変革へつなげる点です。
AI Factoryの構成要素
AI Factoryはデータセンター、コンピュートノード、ネットワーキング、ストレージ、活用するデータ、これらを管理するソフトウェアスタック、アプリケーションレイヤで活用するソフトウェアを主に構成されています。
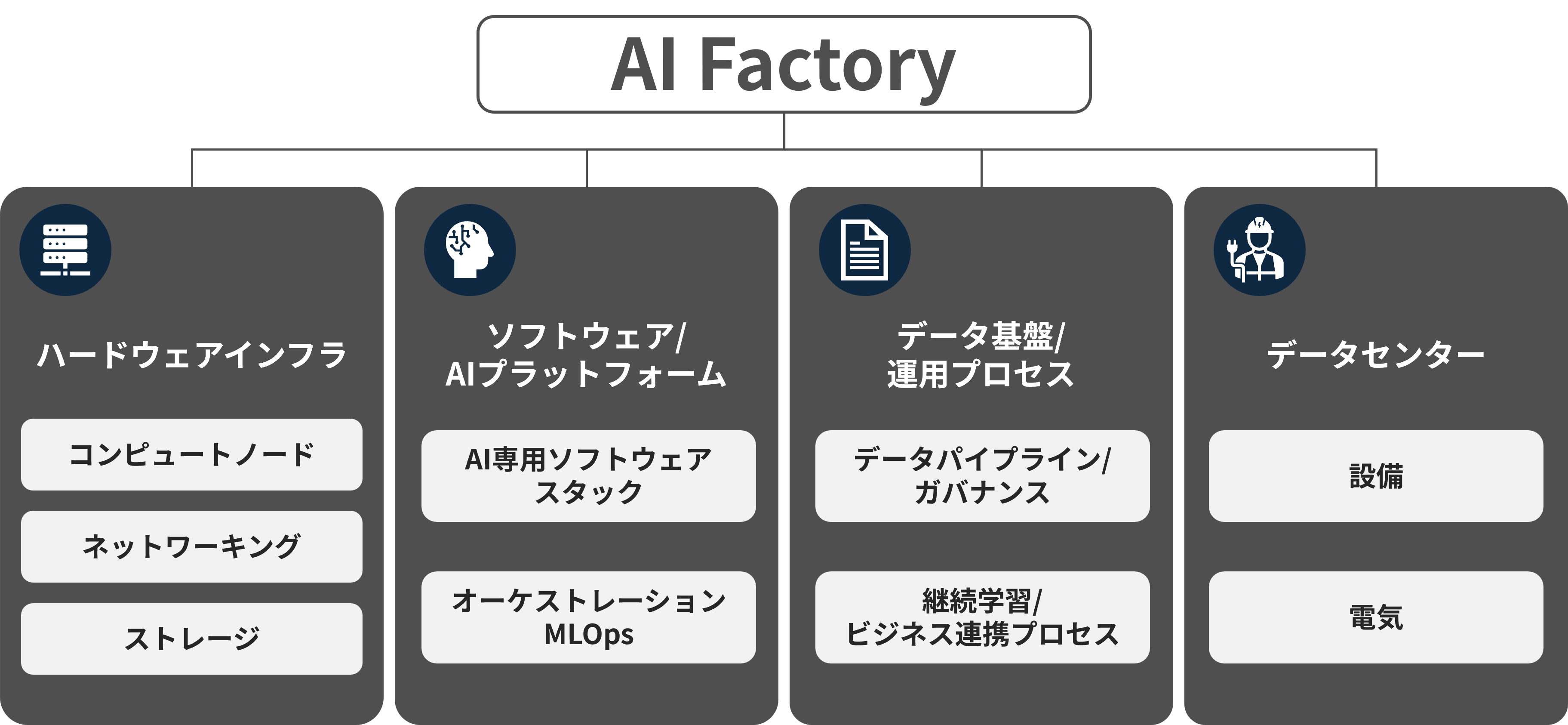
ハードウェアインフラ
・コンピュートノード
・NVIDIA Blackwell世代GPU(B200/GB200)などを中核としたGPUサーバー群と、Grace CPUを組み合わせた高密度コンピュートノードが、生成AIや大規模モデルを支える計算エンジンとなる。
・ネットワーキング
・GPU間を接続するNVLink / NVSwitch、データセンターネットワークとしてのSpectrum-Xにより、高速・低遅延な通信を実現し、ノード間のスケーラビリティを確保する。
・ストレージ
・大容量かつ高スループットなストレージを採用し、学習データの入出力を最適化。液冷を含む高効率冷却システムと組み合わせることで、AIクラスター全体のスケーラビリティと安定稼働を支える。
ソフトウェア&AIプラットフォーム
・AI専用ソフトウェアスタック
・ CUDAを土台とし、学習・推論の高速化を行うTensorRT、生成AI向けのNVIDIA AI Enterprise、NIMマイクロサービス、NeMoなどのフレームワーク群が、AIワークロード全体を支える。
・これらにより、LLMやマルチモーダルモデルの学習・微調整・展開を効率化し、企業ごとのユースケースに合わせたAIサービスを短期間で構築できる。
・オーケストレーションとMLOps
・データ前処理からモデル学習、評価、デプロイ、監視までをパイプラインとして一元管理するMLOps機能が、AIライフサイクルの標準化と自動化を実現する。
・セキュリティ、アクセス制御、監査ログなどのガバナンス機能も組み込まれ、規制産業や政府向けのAI Factoryリファレンス設計にも展開されている。
データ基盤と運用プロセス
・ データパイプラインとガバナンス
・ さまざまな業務システムやIoT、センサーからデータを収集し、品質管理・カタログ化・権限管理を行うデータ基盤が、AI Factoryの「燃料タンク」として機能する。
・ データのライフサイクル管理とガバナンスを徹底することで、コンプライアンス要件を満たしながら、安全に学習用データや推論用データを扱えるようにする。
・ 継続学習とビジネス連携プロセス
・ 本番運用中のAIサービスからログやフィードバックを収集し、モデルの再学習やチューニングに反映する「データフライホイール」が、AIの価値を継続的に高める仕組みとなる。
・ 経営・事業側のKPIとモデル性能指標を結び付ける運用プロセスを整備することで、「AI Factoryがどれだけビジネス成果に貢献しているか」を定量的に評価できるようになる。
データセンター
・ 設備
・ AI Factoryの物理的基盤として、大規模データセンターが全要素を統合。冷却システム、物理セキュリティ、サーバーラック配置を最適化し、数千GPU規模のAIクラスターを安定稼働させる。
・ ハイパースケーラー向け設計やエンタープライズ向け検証済みデータセンターリファレンスにより、高密度配置とメンテナンス性を確保。
・ 電気
・ 高性能GPUクラスターの膨大な消費電力を賄うための大容量電力供給システムを完備。再生可能エネルギー活用や効率的な電源管理で運用コストを最適化。
・ 冗長化電源とUPSを組み合わせ、99.999%以上の可用性を保証し、AIワークロードの連続稼働を実現。
AI Factoryアーキテクチャー
AI Factory向けリファレンスアーキテクチャーは、検証済み構成をベースに設計されており、企業は段階的な拡張や冗長化構成を容易に実現できます。お客様ごとに異なるビジネス要件、ITの成熟度、専門知識を踏まえ、オンプレミスからクラウドまで、インフラ戦略に最適化されたさまざまなアプローチでAI Factoryを実装できます。実装形態としては、NVIDIAのオールインワンソリューションである「DGX SuperPOD」、主要OEMパートナーとの協業による「Enterprise RA」、主要クラウドサービス上で構築する「NCP(NVIDIA Certified Partner)」の3種類を提供しています。
DGX SuperPOD
・ 大規模モデル開発のパフォーマンスとスケーラビリティを求める企業向け。NVIDIAのオールインワンオンプレミスソリューションとして、DGX SuperPOD上にフルスタックソフトウェアを統合し、直接サポートを提供。
・ 数千GPU規模のAIクラスターを短期間で構築可能で、最高性能の学習・推論環境を実現。
Enterprise RA
・ 既存のITパートナー(Dell、Supermicroなど)との関係を活用したい企業向け。OEMパートナーエコシステムを基盤とした検証済み設計で、顧客要件に最適化されたAI Factoryを展開。
・ 自社運用ノウハウを活かしつつ、段階的拡張と高可用性を確保したエンタープライズ導入に最適。
NCP(NVIDIA-Certified Partner)
・クラウドファースト戦略を推進する企業向け。主要CS(AWS、Azure、Google Cloud)でホストされる認定パートナーソリューションを活用し、AI Factoryをクラウドネイティブで実装。
・ プロトタイプから本番スケールまでシームレスに移行可能で、運用負荷を最小化しつつ柔軟なリソース拡張を実現。
マクニカのAI Factory構築支援
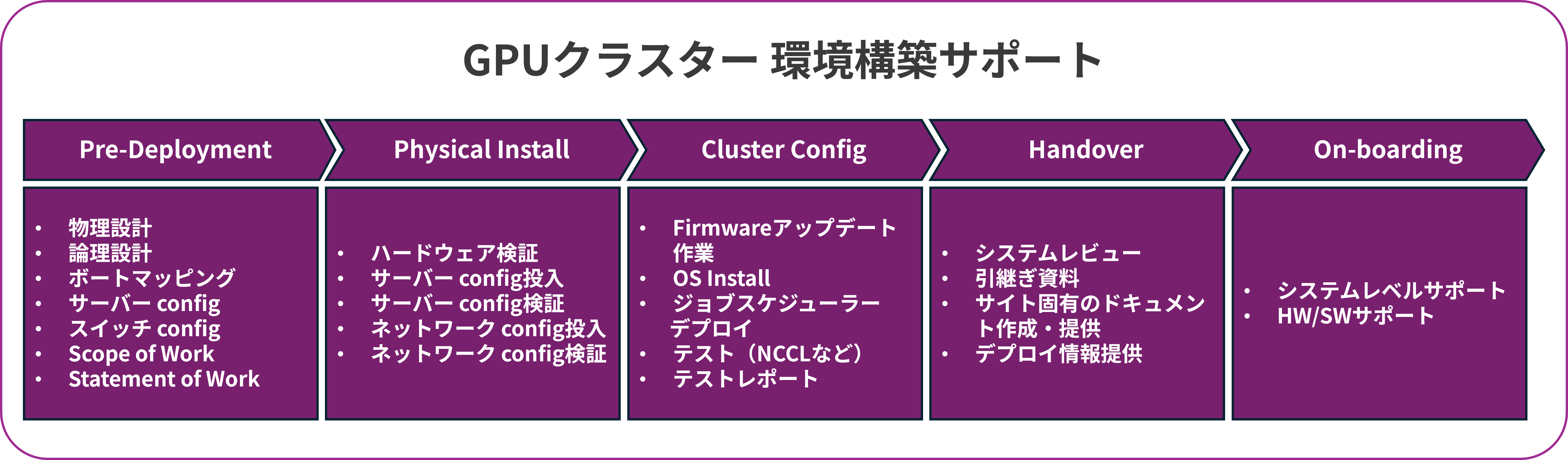
GPUクラスター 環境構築サポート
マクニカでは、AI Factoryを構築して行きたいというお客様のためにGPUクラスター 環境構築サポートを提供しています。GPUクラスター 環境構築サポートでは、GPUクラスターに特化したシステムアーキテクチャーの要件定義からインテグレーション、導入後のサポートまでをスコープとし、ご提供いたします。
詳細は以下のページよりご覧頂けます。
関連ページ



お問い合せはこちら

