- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2184件がヒットしています。check

本記事の内容を解説したウェビナーを実施しました。下記のフォームよりご登録いただくとオンデマンド動画をご覧いただけるURLを送付いたします。
見逃してしまった方や参加者の方でもう一度ご覧になりたい方は、この機会にぜひご登録ください!
VAST InsightEngineを用いたRAGアプリケーションの構築
前話では、VAST InsightEngineの紹介をしました。VAST InsightEngineを用いることでRAG基盤をより簡単に作成することが可能になります。
本話では、実際にVAST InsightEngineを用いてRAGアプリケーションを構築します。
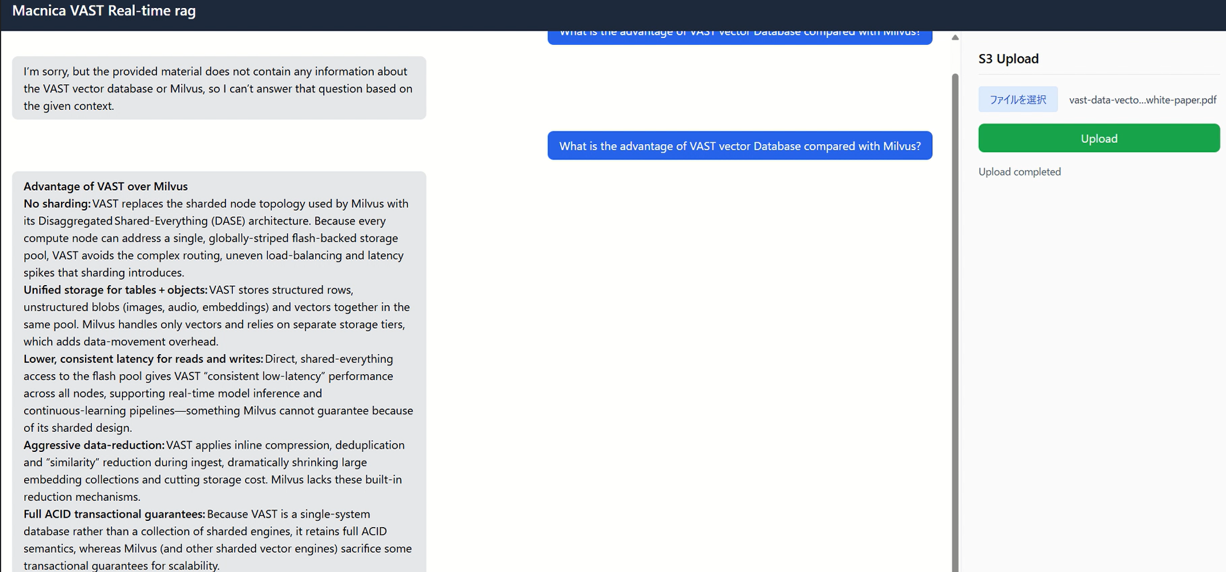
RAGアプリケーション
VAST InsightEngineを用いたRAGの基本構成
本記事では、前記事の内容を基に、文章RAGを作成していきます。
今回作成するRAGアプリケーションでは、VAST InsightEngineのkafka機能とベクトルDBを組み合わせます。ユーザーが質問をおこなうと、質問文を元にVAST内部のベクトルDBに検索をおこない該当する文章やデータを返して返答をLLMが生成します。
また、pdfデータをアップロードするとVAST内部のkafka機能によって前処理がおこなわれて、自動的にVASTベクトルDBが更新されます。
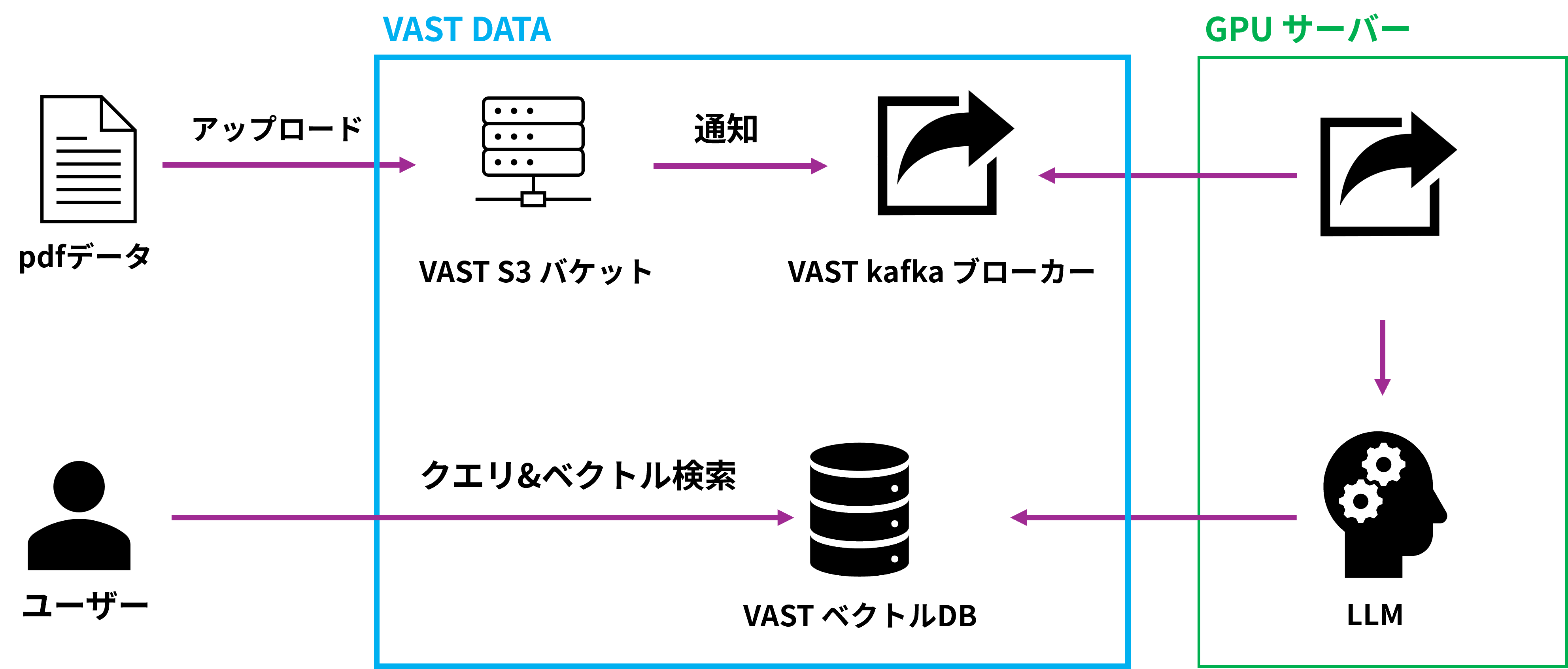
実際の構築の流れは以下のようになります。
1. VAST Data内でRAG用のkafka broker,kafka topicを作成する
2. S3バケットの作成
3. VAST Data内でRAG用のベクトルDB作成
4. 各要素を繋げてパイプラインを作成
各要素について解説しながら実際にRAGを作成していきます。
1. VAST DATA内でRAG用のkafka broker,kafka topicを作成する
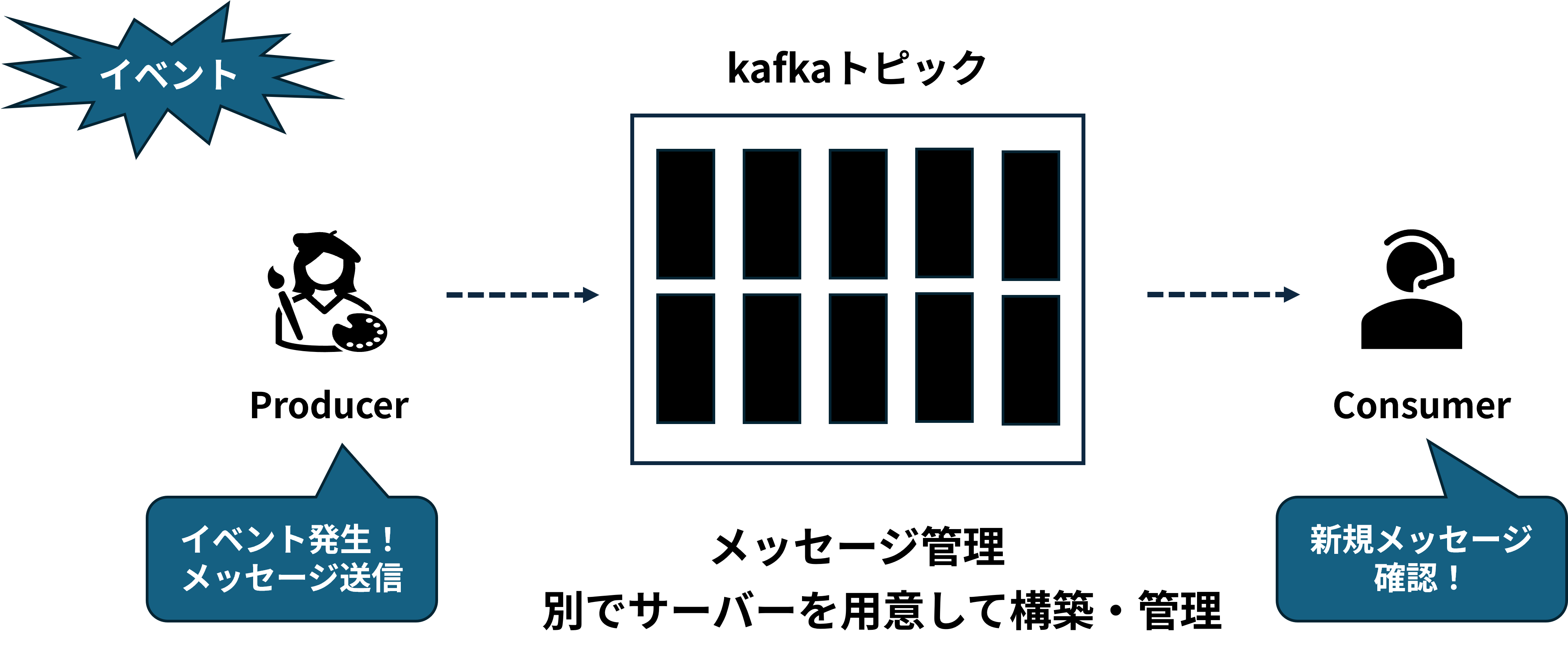
Kafkaにはメッセージを送信するProducer、メッセージを管理するBrokerがありますが、VAST InsightEngineではkafka brokerとproducer部分をネイティブにサポートしております。
それでは実際に、VASTData内でkafka brokerを作成していきます。kafka brokerはVAST Dataの管理画面(以下VMS)から作成できます。
作成手順
まずは、”Protocols”でkafkaのviewを選択します。(VAST Dataでの“view”は、共有ボリュームのような意味合いで使われます)このviewがkafka brokerとして機能します。
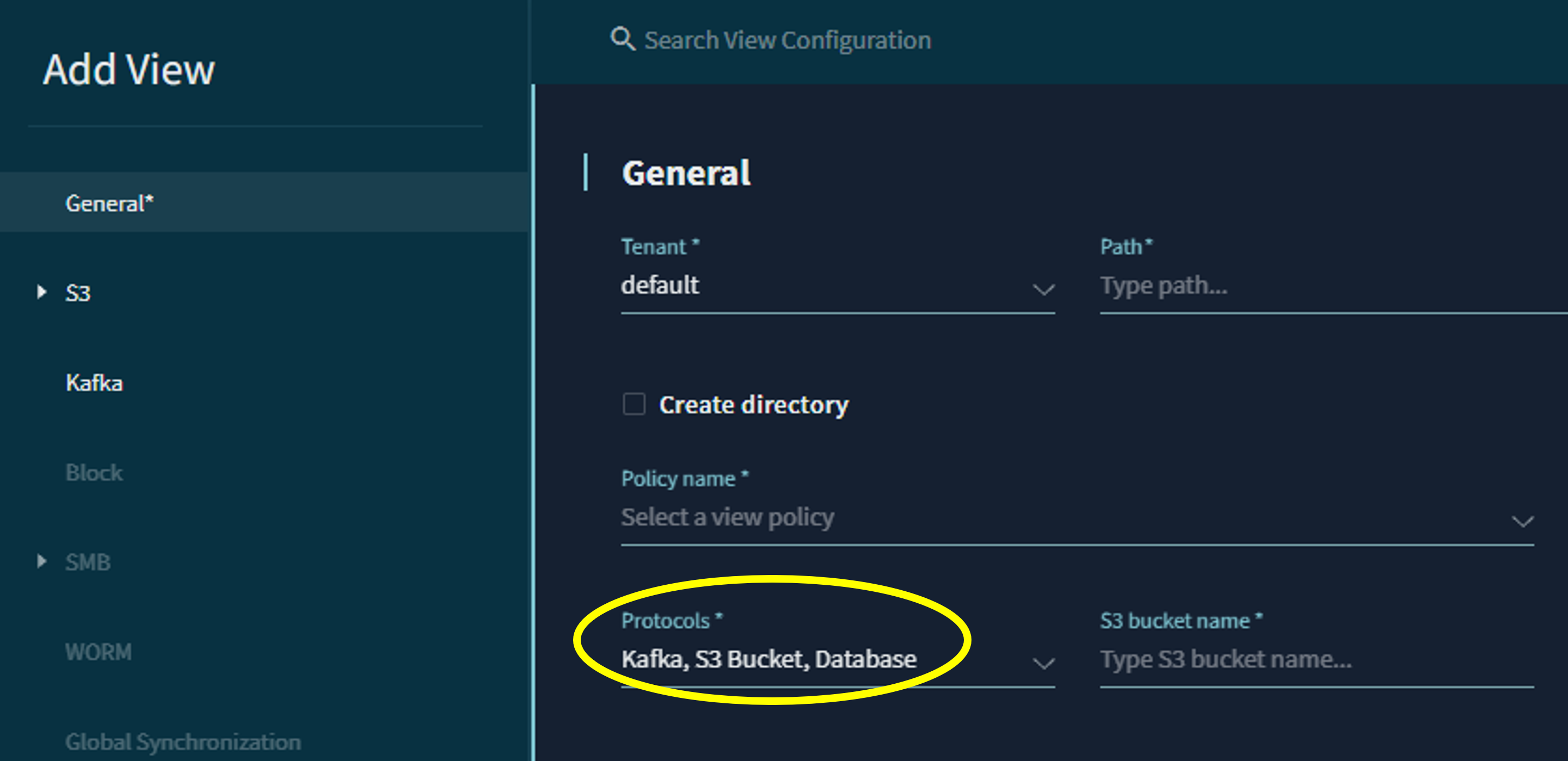
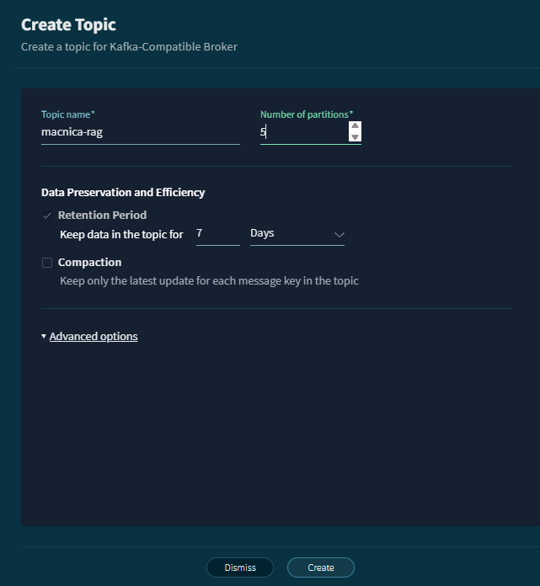
次に、このbrokerで任意のtopicを作成します。この際に、パーティションとデータ保存期間を選択可能です。
今回は、macnica-ragというkafka topicを作成します。
2. S3バケットの作成
次に、生データを保存するためのS3バケットを作成します。こちらもVMS経由で作成をおこないます。
VAST DataではS3バケットを作成するためにバケットOwnerを作成する必要があります。Owner各個人には、それぞれAccess KeyとSecret Keyが付与されます。このKeyを用いてバケットへの操作をおこないます。
作成したS3バケットにはイベント通知機能を設定することが可能です。オブジェクトの作成、削除などの操作に対してイベントを通知させることができます。このイベント通知のための媒体として、先ほど作成したkafka topicを選択することが可能です。Notificationに先ほどのkafka-topicを設定します。イベント通知をするトリガーはObjectが作成されたタイミングに設定します。
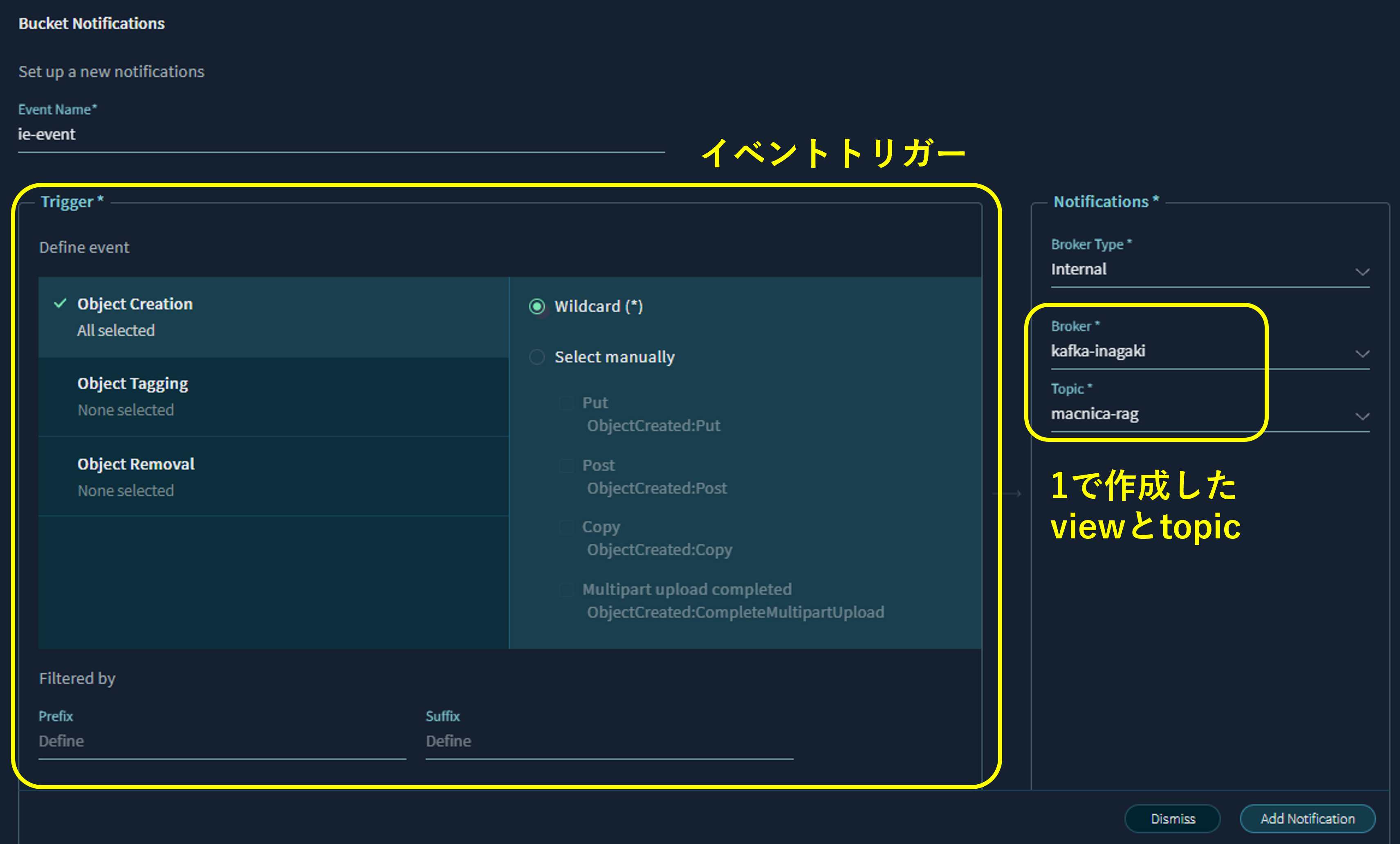
また、外部サーバーに存在する既存のkafka brokerをS3の通知用brokerとして設定することも可能となっております。
3. VAST Data内でRAG用のベクトルDB作成
VAST Data内でベクトルDBを作成するには、”Protocols”がDatabaseのviewを作成します。
VAST DataのDatabaseにはベクトルのカラムを挿入することができます。Databaseにも先ほどのS3バケットのようにユーザーを設定する必要があります。そのため、Databaseに関する操作もS3バケットのようにAccess KeyとSecret Keyを用いて操作をおこないます。
今回はdemoというDatabaseのテーブルを作成し、ベクトルを挿入して検索するまでを実行します。
まずは、VAST Databaseに関する操作をおこないます。操作には、pyarrowとvastdbライブラリを使用します。
VAST Databaseはベクトルデータを浮動小数点で保存します。
import pyarrow as pa
import vastdb
DB_ENDPOINT = "http://10.0.50.70"
DB_ACCESS_KEY = "バケットのアクセスキー"
DB_SECRET_KEY= "バケットのシークレットキー"
DB_BUCKET_NAME = "DBのバケット名"
SCHEMA_NAME = "SCHEMA名"
TABLE_NAME ="TABLE名"
##DBと接続を取る
session = vastdb.connect
(
endpoint=DB_ENDPOINT,
access=DB_ACCESS_KEY,
secret=DB_SECRET_KEY
)
#insertするデータの形式を規定
#2048次元ベクトルとその文章を入れるデータ形式
##ベクトルデータをvecとして、文章データをsentenceとして保存
dimension = 2048
columns = pa.schema([
("vec", pa.list_(pa.field(name="item", type=pa.float32(), nullable=False), dimension)),
('sentence', pa.string())
])
#インサートするデータを作成
#ベクトルデータ二つのダミーデータ
vector = [[0.1]*2048,[0.2]*2048]
#文章二つのダミーデータ
sentence = ["Hello VAST!","Hello, InsightEnigne!"]
#DBに挿入するデータを作成
data = [vector,sentence]
datas = pa.table(schema=columns,data=data)
#実際に繋いでベクトルを挿入
with session.transaction() as tx:
bucket = tx.bucket(BUCKET_NAME)
##新規schema作成
schema = bucket.create_schema(SCHEMA_NAME)
##新規table
table = schema.create_table(TABLE_NAME,columns)
table.insert(datas)
次にベクトル検索をおこないます。
検索には、VAST Dataが用意しているadbc_driver_managerを使用します。
ドライバーパッケージはVAST Dataのgithubからダウンロードできます。
https://github.com/vast-data/vastdb-adbc-driver
検索には基本的には、SQLベースの構文でおこなわれます。
import adbc_driver_manager
from adbc_driver_manager import dbapi
##ドライバーのパス
DRIVER_PATH = "PATH TO “vastdb-adbc-driver-v0.0.13-linux-amd64/libadbc_driver_vastdb.so"
DB_ENDPOINT = "http://10.0.50.70"
DB_ACCESS_KEY = "バケットのアクセスキー"
DB_SECRET_KEY= "バケットのシークレットキー"
DB_BUCKET_NAME = "DBのバケット名"
SCHEMA_NAME = "SCHEMA名"
TABLE_NAME ="TABLE名"
##ベクトル検索
vector = [0.0]*2048
sql_vector = f"{vector}::FLOAT[2048]"
##VAST ベクトルDBに接続するためにコネクターを規定
with adbc_driver_manager.dbapi.connect(
driver=DRIVER_PATH,
db_kwargs=
{
"vast.db.endpoint": DB_ENDPOINT,
"vast.db.access_key": DB_ACCESS_KEY,
"vast.db.secret_key": DB_SECRET_KEY,
},
) as conn:
#コネクターで検索を実施
with conn.cursor() as cursor:
full_table_name =f'"{DB_BUCKET_NAME}/{SCHEMA_NAME}"."{TABLE_NAME}"'
query = (
f"SELECT * FROM {full_table_name} "
##vec列で距離が近いデータを上位5個検索
f"ORDER BY array_distance(vec, {sql_vector}) LIMIT 5;"
)
#検索実行
cursor.execute(query)
#pandas形式で出力
output_as_pandas_dataframe = cursor.fetch_arrow_table().to_pandas()4. 各要素をつなげてパイプラインを作成
ここで、各要素をつなげて一つのパイプラインを作成します。流れとしては以下のようになります。
1. アップロードと同時に前処理 + ベクトル化を実行 (VAST InsightEngine kafka)
↓
2. ベクトル化したデータをVAST VectorDBに保存 (VAST InsightEngine vector)
これらをまとめて、簡単なragアプリケーションを作成しました。
ingestとrag関数はFastapi、uiはhtmxを用いています。
以下は、ragアプリケーションの動画となります。VAST S3バケットに、VAST Dataのpdf資料 (https://www.vastdata.com/resources/white-papers/vast-data-vector-database)をアップロードすると自動的にベクトルDBに更新されます。
次話では、RAGアプリケーションで一番の詰まりどころである、アクセス制限付きのRAGをVAST InsightEngineを用いて構築します。
VAST DataはベクトルDBも内包しているのでストレージの権限設定に基づいた権限をベクトルDBに付与することが出来ます。
お問い合せはこちら

