- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2183件がヒットしています。check

近年、音声認識はさまざまな場面で使用されています。音声認識、特にボイストリガーは非常に便利で需要が高い一方、導入にはさまざまな障壁があります。本記事では音声認識の基礎に触れながら、ボイストリガー開発の課題と、それを解決するソリューションを紹介します。
■目次
・音声認識の基礎知識
・ボイストリガー導入の障壁
・ボイストリガーを実現するソリューション紹介
・まとめ
音声認識の基礎知識
音声認識とは?
音声認識とは、声が持つ情報をコンピューターに認識させる技術です。
左画像の話者認識では、スマートスピーカーなどに話しかけてその内容を処理しています。右画像では、オンライン会議で発言した内容を文字に起こすためにこの技術が利用されています。


音声認識の種類
一般的に音声認識は大きく二種類に分けることができます。
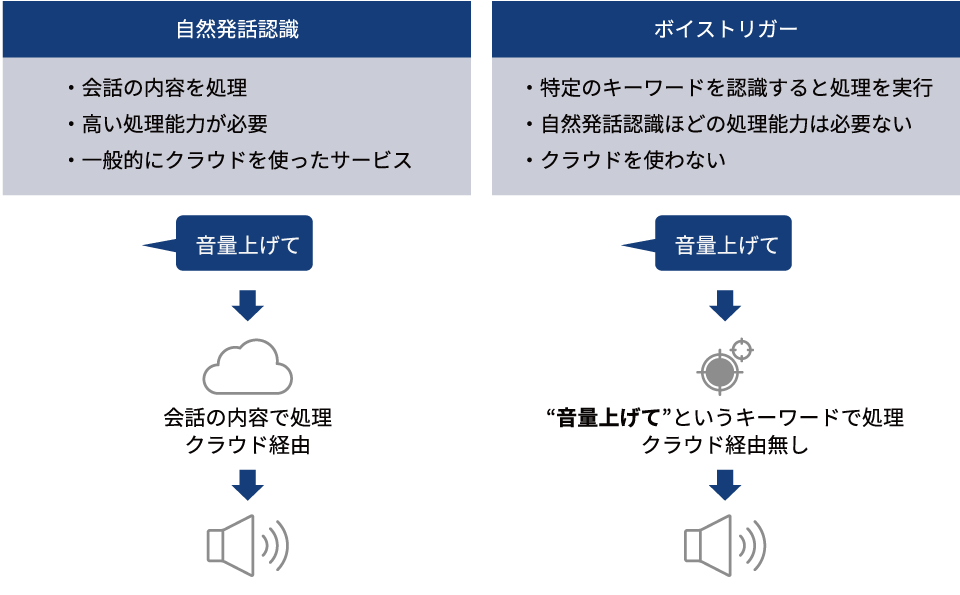
1つ目は自然発話認識です。これは会話の内容をコンピューターが理解し、その内容を処理するものです。高い処理能力が必要となるため、一般的にクラウド環境が利用されています。
2つ目は、ボイストリガーです。これはコンピューターが特定のキーワードを認識すると、あらかじめそのキーワードに対応して設定された処理が実行されます。こちらは自然発話認識ほど高い処理能力を必要としないため、クラウドを使わずに実現できます。
下図は、「音量を上げて」と発言した場合の処理を自然発話認識とボイストリガーで比較しています。
ボイストリガー導入の障壁
ここからは音声認識のなかでもボイストリガーについて解説していきます。
繰り返しになりますが、ボイストリガーとは入力された音声データ内にあらかじめ設定した“キーワード”があった場合に、コマンドを実行して、一連のアクションを発生させる機能です。
このキーワードをトリガーワードとも言います。
メリットとユースケース
ボイストリガーを導入するメリットとユースケースは以下です。
ボイストリガーのメリット
・自然な感覚で操作できる
・ハンズフリーで使える
・クラウドを必要とせずリアルタイム処理が可能
・シンプルなユーザーインターフェイスを実現できる
ボイストリガーのユースケ―ス
1. ボタンを触りたくない場合

2. 手がふさがっている場合

3. モード選択が複雑な場合

上記以外にも、ボタンで操作しているものほぼ全てボイストリガーに置き換えることが可能です。
開発手順
ボイストリガーの開発手順を解説します。ボイストリガーを開発する際は以下のフローに沿って進めるのが一般的です。
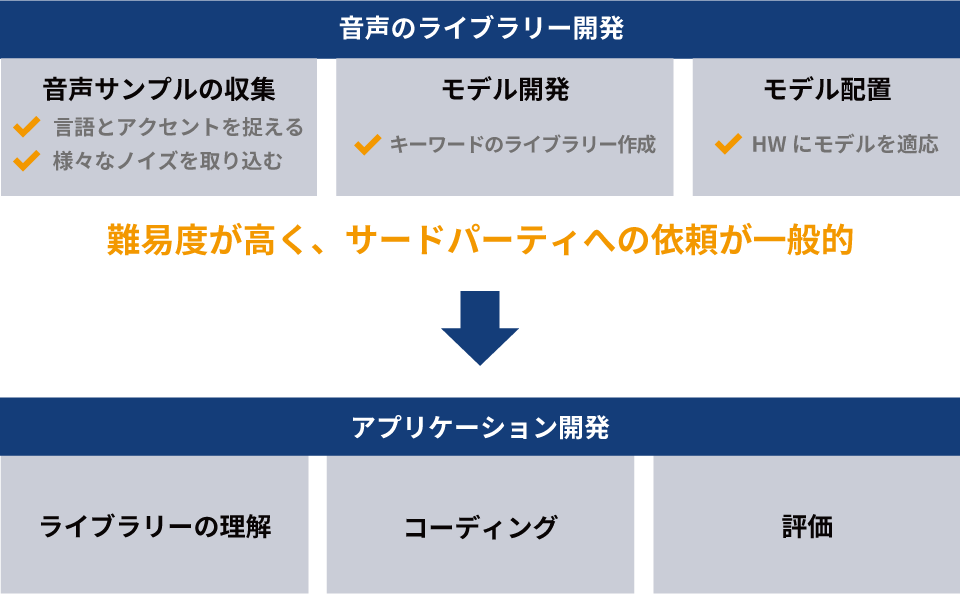
まず音声のライブラリー開発をおこない、それを用いてアプリケーション開発をおこないます。
具体的には音声サンプルの収集です。想定される利用者の言語やアクセント、周囲の状況などを考慮した音声サンプルを開発元の企業が準備する必要があります。続いて、モデル開発ではキーワードのライブラリーを作成し、モデル配置でその作ったモデルをハードウェアに適用します。その後、作ったライブラリーを用いてプログラミングをおこない、評価に移るといった手順になります。
上記フローのなかでも音声のライブラリー開発は難易度が高いため、サードパーティーに開発を委託することが一般的です。
ボイストリガー導入の障壁
ここまでの内容から、ボイストリガー実装にあたってのいくつかの課題をまとめます。
ボイストリガー導入の障壁
1. 専門的な知識が必要
2. 多数の音声データサンプルが必要
3. 音声認識の難易度が高い
1つ目がボイストリガー自体の専門的な知識が必要で、自社開発が難しいことです。
ボイストリガー自体はネットワークに接続しないため、マイコンプロセッサーのソフトウェアで実現することが可能ですが、音声データからトリガーワードを解析する処理は一般的に独自の技術が使われており、多くの場合アルゴリズムは公開されていません。そのため、自社開発は困難を極めます。このような理由から、サードパーティーに開発を委託することが一般的です。
2つ目が、ボイストリガーの技術によっては多数の音声データサンプルが必要になることです。
ボイストリガーを実現する方法として、一つのトリガーワードに対してさまざまな人の音声サンプルを学習させることがあります。その場合、独自の音声サンプルを用意する時間とコストが必要となります。独自のトリガーワードを作ることも多く、その際は既存の音声データを活用できないため、一からサンプルを用意しなければいけません。
3つ目が、ユーザー像が多岐にわたるため音声認識の難易度が高いことです。
同じ単語でも、話し手の年齢や性別、方言などによって、コンピューターには大きな差異のある音声として認識されます。そのため、ユーザーの属性によって音声認識エンジンの調整が必要となります。特に、想定されるユーザー像が多岐にわたる製品では、音声認識の難易度が高まります。
ボイストリガーを実現するソリューション紹介
ルネサス社の音声認識ソリューションキットと日立ソリューションズ・テクノロジー社のソフトウェアツールを活用することにより、これらの課題を解決し、ボイストリガー導入を実現することができます。
システム開発を簡易化するルネサス社の音声認識ソリューションキット
まずは、ルネサス社の音声認識ソリューションキットである「RA6E1」マイコンが搭載された音声ユーザーインターフェース(VUI)のハードウェアプラットフォームを紹介します。このソリューションキットを活用することで、豊富なコーディング経験や専門知識がなくとも、このシンプルな音声ユーザーリファレンスキットを使って簡単にシステム開発が可能です。
※「RA6E1」はルネサス社が提供しているArmコアを搭載したRAファミリーの低価格エントリーラインシリーズです。

このハードウェアプラットフォームは、ルネサス社が Renesas Ready Partner Network内で提供するすべてのVUIパートナー対応ソリューションに使用できます。こちらのボードにはマイクが搭載されており、ノイズ除去機能のビームフォーミングに適した配置がされています。
日立ソリューションズ・テクノロジー社のソフトウェアツール「Ruby Spotter」について
日立ソリューションズ・テクノロジー社の「Ruby Spotter」は、MCUなどの小さなメモリー量(ROMサイズ200KB程度)で動作する音声インターフェースを実現するアプリケーションプログラミングインターフェース(API)です。
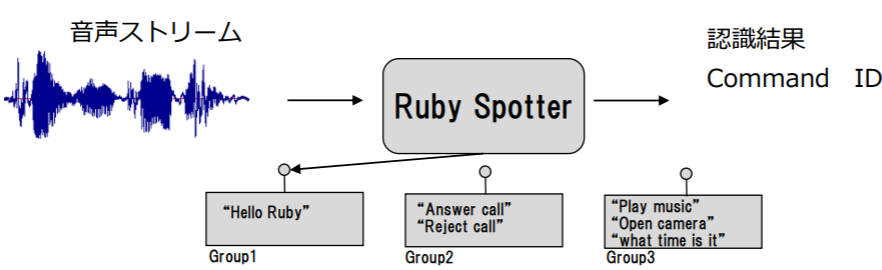
「Ruby Spotter」の特長
・小さいメモリー量(ROMサイズ200KB程度で動作)で動作
・高品質なノイズリダクション
・40か国以上の言語から認識する言語を選択可能
・Phoneme(音素)ベースのモデリングを採用しており、言語が増えてもコマンドリスト以外のデータは増えない
|
機能仕様 |
Ruby Spotter |
|
言語 |
日本語、オプションで40言語に対応可能。 |
|
音声認識 |
単語認識、ウェークアップワード、ノイズリダクション |
|
音声合成 |
- |
|
動作OS |
Linux, Android, Windows, iOS, RTOS, non-OS |
|
CPU |
60MIPS(or 35MIPS※1) |
|
コードサイズ |
40KB |
|
データサイズ |
155KB+32B×N※2 |
|
メモリー容量 |
24KB+128B×N※2 |
【備考】
※1:SIMD命令利用時
※2:N=コマンド数
ボイストリガーのプログラム作成方法
ルネサス社の音声認識ソリューションキットと日立ソリューションズ・テクノロジー社の「Ruby Spotter」を組み合わせることで、ボイストリガーをわずか3ステップで実現することができます。
Step1. 「Ruby Spotter」のGUIを使ってトリガーワードを作成(テキストを入力するだけ!)
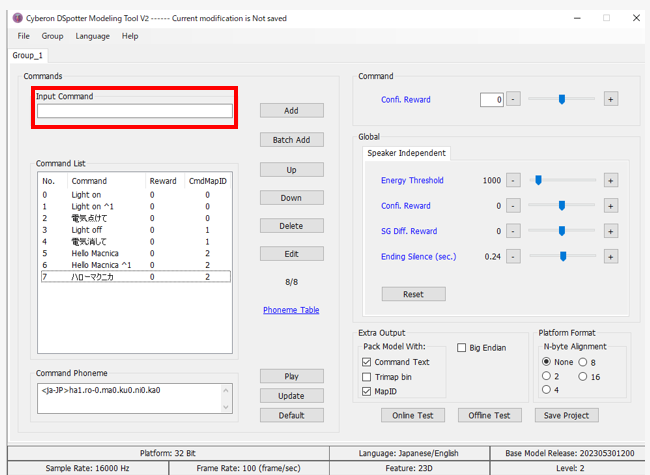
こちらが「Ruby Spotter」の画面です。
赤枠で囲われたところにテキストを入力するだけでトリガーワードを作成可能です。
また、トリガーワードを設定する際に実際の音声を使ってチューニングすることもできます。
ここで作成したトリガーワードに青枠でMapIDという番号を振り分けます。
Step2.Step1で作成したトリガーワードに紐づけたMapIDを使ってコーディング
RAマイコンの開発に使えるルネサス社の統合開発環境e2studioを使用しプログラムを作成します。
(サンプルプログラムも用意されています)
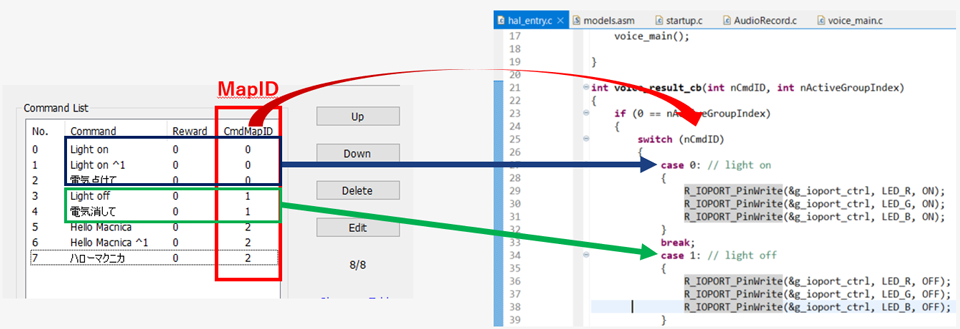
上の例では、「Light on」、「電気点けて」に紐づけたMapIDを1に設定し、
「Light off」、「電気消して」に紐づけたMapIDを2に設定しています。
このMapIDを使ってコーディングできるため、右のコードのように簡単にプログラミングをすることができます。
Step3.Step1で作成した音声ライブラリーをインポート
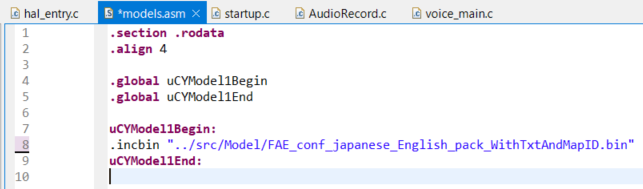
Step1で作成した音声ライブラリーを指定の場所にパスを記入しインポートするだけです。
以上3ステップで簡単にボイストリガーのプログラムを作成することができます。
まとめ
本記事では音声認識の基礎とボイストリガー導入の障壁を解説しました。また、ルネサス社の音声認識ソリューションキットと日立ソリューションズ・テクノロジー社の「Ruby Spotter」を活用することで簡単にシステム開発が可能となることを紹介しました。
お問い合わせ
ソリューションの詳細希望や不明点があれば、以下よりお問い合わせください。

