- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2184件がヒットしています。check

はじめに
生成AIを業務に組込む現場では、推論品質だけでなく、通信断への耐性、継続稼働性、運用コストまで含めた設計が求められます。特に映像・音声・ログを常時扱うシステムでは、データをすべてクラウドへ送る構成だけでは、帯域・遅延・可用性の面でしばしば課題が生じます。
これまでエッジ側には、「大きなモデルを動かすにはGPUメモリーが不足している、実用速度での推論が難しい」という制約がありました。
NVIDIA® Jetson Thor™は、この制約を緩和し、現場でマルチモーダル生成AIを運用する現実的な選択肢を広げます。
また、NVIDIA社が提供するNVIDIA Nemotron™ 3 Nano Omniは、テキスト・画像・音声・動画を単一のモデルで扱えるマルチモーダル推論モデルであるため、複数のモデルを組み合わせる必要がなく、管理や運用の複雑さを抑えられる点や、複数のモデルをデプロイする場合よりもGPUメモリーの消費量を抑えられる可能性が高い点が魅力的です。
エッジ生成AIのユースケース
生成AIをエッジで使いたい理由は、単なる低遅延だけではありません。実運用では次の要求が同時に発生します。

・ ネットワークが不安定な拠点でも止めずに動かしたい
・ 高温、多振動、屋外など耐環境性が求められる現場で処理したい
・ カメラや音声などの大量データを24時間365日処理し、帯域とクラウド費用を抑えたい
・ クラウド停止や回線断のリスクを避け、現場側で継続運転したい
先に述べたように、エッジ側で生成AIを導入するには、「大きなモデルを動かすにはGPUメモリーが不足している、実用速度での推論が難しい」という課題がありました。
しかしJetson Thorでは、GPU性能・ソフトウェア最適化・NVFP4対応などにより、この制約は実運用レベルで大幅に緩和されてきています。
Jetson AI Lab
Jetson AI Labは、Jetson向けのモデル実行情報がまとめられており、対応モデル、導入手順、ベンチマークを素早く確認できます。
NVIDIA Nemotronシリーズだけでなく、NVIDIA Cosmos Reason、Google Gemma 4、OpenAI GPT-OSS、Alibaba Qwenシリーズなどのモデルも、Jetson AI Labで動作確認されているため、検証開始までの時間を大幅に短縮できます。
また、推論サーバーに関してもvLLMやSGLang、llama.cpp、Ollama、TensorRT Edge-LLMなど複数の選択肢が掲載されているため、モデルと推論サーバーの組み合わせを検討する際にも役立ちます。
Jetson AI Lab Models
Nemotron 3 Nano Omni
Nemotron 3 Nano Omniは、テキスト、画像、音声、動画を1つのモデルで扱うオープンなマルチモーダル推論モデルです。 画像や動画を扱えるマルチモーダルモデルは多くありますが、テキスト・画像・音声・動画を単一のモデルで扱える点が大きな特徴です。
・ 30B-A3B Hybrid MoEアーキテクチャー
・ 入力: テキスト / 画像 / 音声 / 動画
・ 出力: テキスト
Nemotron 3 Nano Omniは「マルチモーダルを1モデルに集約し、効率と運用性を両立しやすい」点が強みです。
下記リンクの各種ベンチマークが示す通り、高い精度とスループットを兼ね備えたモデルであり、JetsonThorのような高性能エッジAIデバイスと組み合わせることで、クラウド依存を下げたアーキテクチャーを設計しやすくなります。
Nemotron 3 Nano Omniに関する詳細は、以下のURLを参照してください。
Nemotron 3 Nano Omni on Hugging Face
NVIDIA Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning in a Single Efficient Open Model
MediaPerf Results for New NVIDIA Nemotron 3 Nano Omni Pushing the Efficiency Pareto Frontier
Jetson ThorでNemotron 3 Nano Omniを動かす方法
今回はJetson AI Labで紹介されている、vLLMを使ったサーバー構築の方法を紹介します。
Jetsonの基本的なセットアップ方法は弊社でも公開しておりますので、ご参考になれば幸いです。
Jetson AGX Thor 開発者キット入門:最短セットアップからAI推論の動作確認まで
まずは、ターミナルで下記コマンドを実行します。
sudo docker run -it --rm \
--runtime=nvidia --network host \
-v $HOME/.cache/huggingface:/root/.cache/huggingface \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.20.0-ubuntu2404 \
-c "pip install -q 'vllm[audio]' && vllm serve nvidia/Nemotron-3-Nano-Omni-30B-
A3B-Reasoning-NVFP4 \
--trust-remote-code \
--gpu-memory-utilization 0.65 \
--max-model-len 32768 \
--reasoning-parser nemotron_v3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder"その後、下記の画像のようにvLLMサーバーが起動し、モデルがロードされるのを待ちます。

モデルがロードされると、下記の画像のようにOpenAI互換APIのエンドポイントが起動します。

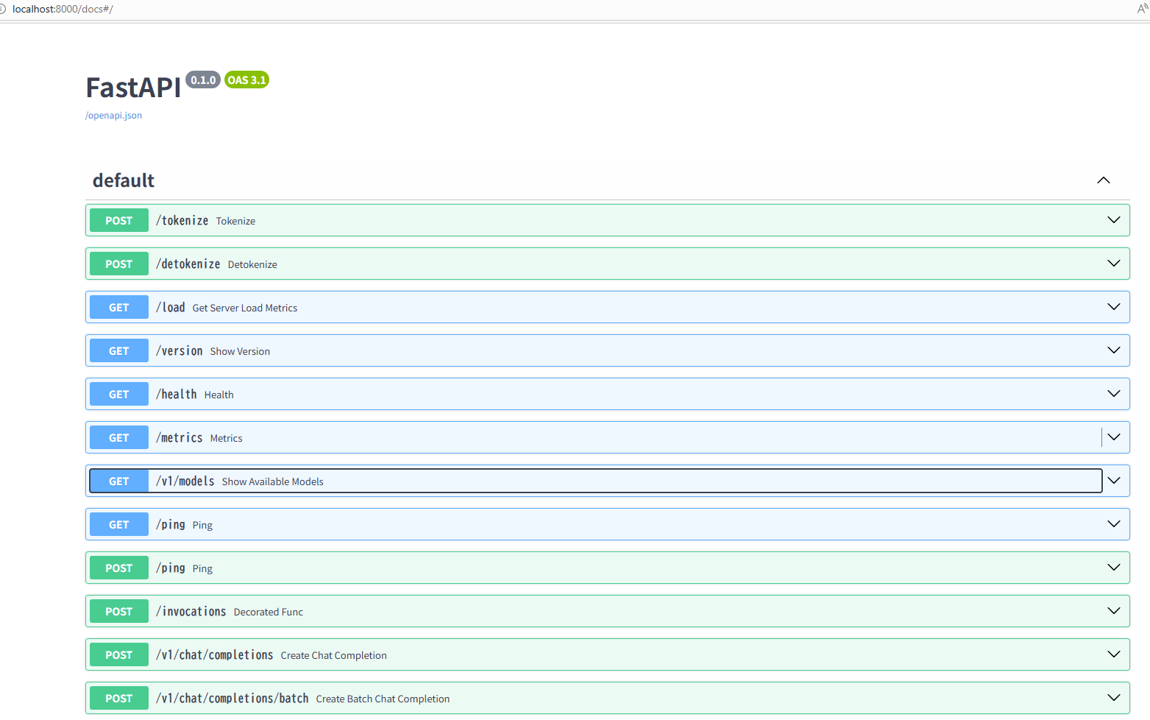
localhost:8000/docsにアクセスすると、FastAPIのドキュメント画面が表示され、API疎通の確認ができます
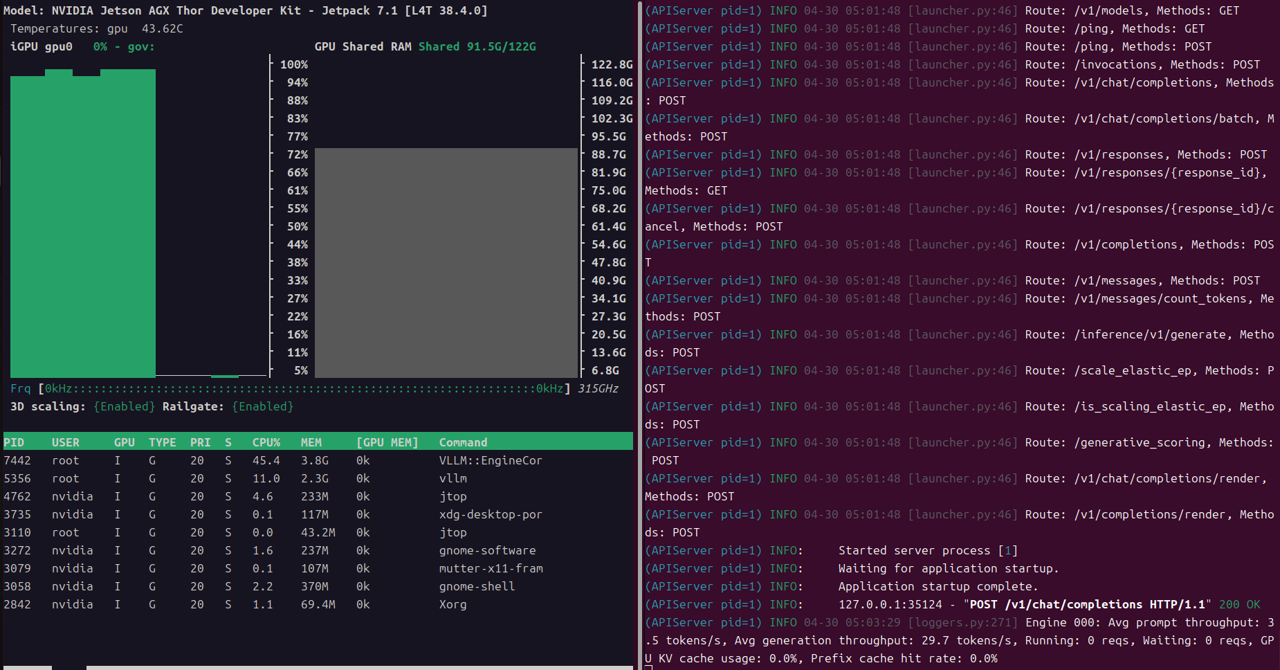
jtopなどでGPU使用率を確認しながらAPIにリクエストを投げると、推論が実行されている様子がわかります。
わずかこれだけの手順で最先端のモデルがJetson Thor上で動かせるため、検証開始までの時間を大幅に短縮できます。
実際に動いている様子
以下は、NVIDIA Nemotron 3 Nano OmniがJetson Thor上で動作している例です。 今回はHugging FaceのExampleを参考にしつつ、Pythonライブラリーの一つであるStreamlitを使って、テキスト/画像/音声/動画のマルチモーダル推論の簡易アプリケーションを作成しました。
もしご興味がある方は弊社までご連絡いただけますと幸いです。
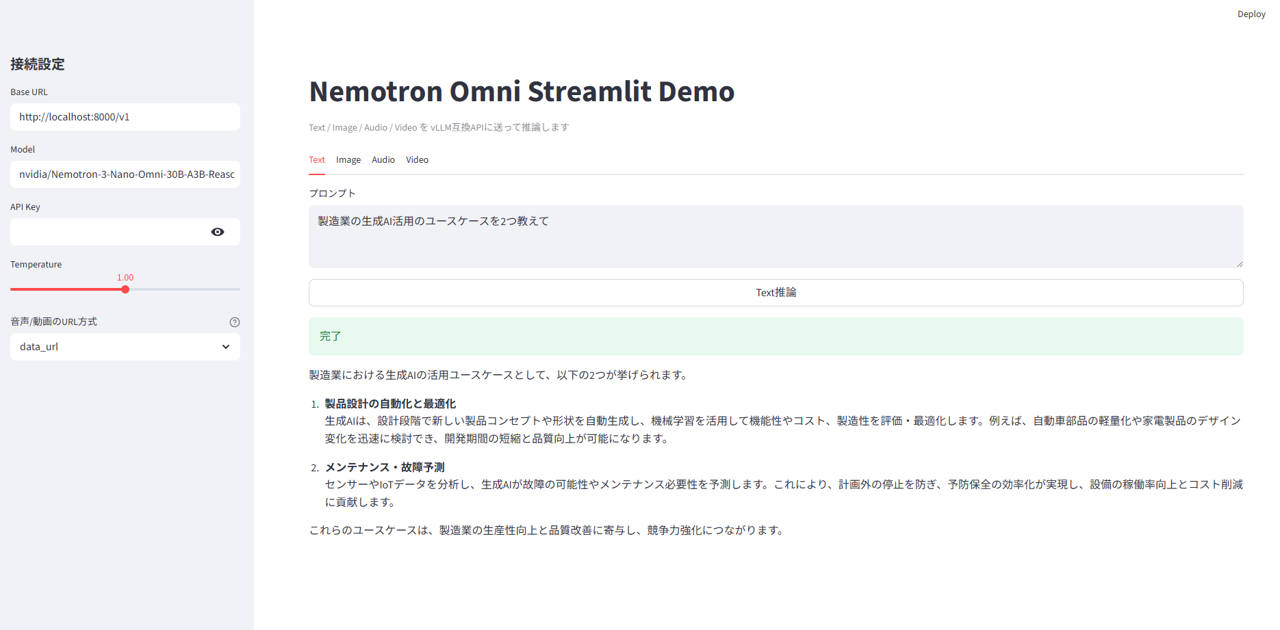
テキスト推論
日本語プロンプトに対して、UI上で推論結果が返ってきている例です。
画像推論
カメラやアップロードした画像を入力として与え、被写体や背景を説明できている例です。

この画像は、日本の公園の遊具が設置されたエリアを示しています。
・ 遊具: 画面左側には青色のフレームに吊るされた2つのスイングがあり、その下には赤色のフレームで作られた小さな遊具があります。
画面右側には、赤色の柱とアーチ状の手すり、黄色のスライド、そして青色の階段が一体になった遊具があります。
・ 地面: 遊具の下には、灰色の砂や小石で覆われた安全な地面が広がっています。
・ 背景: 遊具の奥には、黒い金属製の柵と、その上に緑の芝生が覆われた小さな丘があります。丘の上には、いくつかの木が点在しています。
さらに遠くには、住宅やアパートなどの建物が見え、電線や電柱が空を横切っています。
・ 天候: 空は曇りで、光がやや薄いようです。
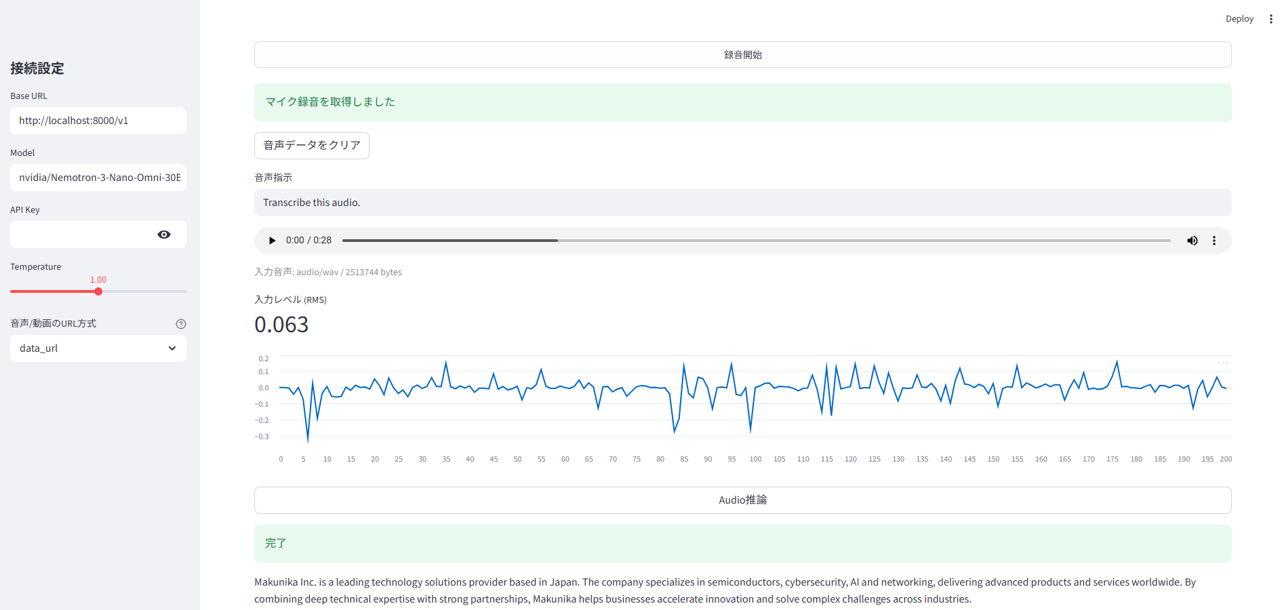
音声推論
マイクからの音声を取り込み、文字起こしを実行した例です。
動画推論
動画内容を時系列で説明し、行動変化を含めて記述している例です。

この動画は、高架の歩道や橋のような位置から、下方の鉄道レールを眺めている映像です。手前に緑色のメッシュフェンスが走っており、その下には砂利の敷かれたレールが見えます。
動画の始まりには、画面の右側から列車の全面が現れてきます。この電車は銀色の車体に、上部に鮮やかな緑色の帯が走っているデザインです。前面には大きな窓があり、上部には空気抵抗を減らす形状のデザインが採用されています。
列車がカメラの正面に近づくと、側面の様子がはっきりと見えます。車体には「JR」のロゴと「YOKOHAMA」の文字が縦向きに書かれており、これは横浜を拠点に運行するJR東日本の通勤電車であると推測されます。ドアや窓が定期的に並んでおり、車両のつなぎ目もはっきりしています。
列車が進むにつれて、後続の車両も続々と画面を通り過ぎます。背景には高さのあるコンクリートの擁壁があり、その上には緑の植生が生えています。さらに奥には、多階建てのマンションや商業施設などの建物が見え、街並みを形成しています。
上空には複雑な電線や架線柱が立っており、電車を支えています。最後に、列車の最後の車両が画面を左へと去り、レールは空っぽになり、遠くの坂道や建物が見えるようになります。この映像は、日常の通勤風景を静かに記録したものです。
まとめ
エッジ生成AIの現場では、通信品質、耐環境性、24時間365日運用、クラウド依存リスクといった要件が同時に求められる場合があります。
Jetson Thorは、これまでエッジ側のボトルネックだった「大きなモデルを動かすにはGPUメモリーが不足している、実用速度での推論が難しい」という制約を大幅に緩和し、実運用しやすい選択肢を提供します。
さらにNemotron 3 Nano Omniは、マルチモーダルを単一モデルで扱えるため、構成をシンプルにしながら高い推論品質が得られる点が魅力です。 加えて、Jetson AI Labを参考にすることで、検証開始までの時間も短縮できます。
また、Nemotron 3 Nano OmniはNVIDIA NemoClawやAIエージェントなどと組み合わせることで、より高度なマルチモーダル推論やツール連携も可能になります。
エッジでの生成AIの活用を検討されている方は、ぜひJetson ThorとNemotron 3 Nano Omniの組み合わせを試してみてください。
参考URL

お問い合せはこちら

