- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2183件がヒットしています。check

はじめに
NVIDIA社からNVIDIA DGX Spark™がリリースされ、様々な用途で活用が進んでいます。DGX SparkはGPUワークステーション単体としても優秀であり、NVIDIA® ConnectX® -7を搭載していることから、マルチノードでの作業にも優れた性能を発揮します。
実際にDGX Sparkを2台使った実装例は多くの方が紹介されています。 また分散学習や分散推論は今後のGPU活用に欠かせない技術ですが、なかなか環境を準備するのが大変だと思います。
今回は、より大規模なGPUクラスターを意識してNVIDIA® Spectrum®-2 SN3700 イーサネット スイッチとDGX Spark 4台を使用してGPUクラスターを構築し、分散推論を実施した様子をご紹介します。

検証環境
ハードウェア
・ GPU計算ノード: NVIDIA DGX Spark 4台
・ ネットワークスイッチ: NVIDIA Spectrum-2 SN3700 イーサネット スイッチ 1台
ソフトウェア
・ OS: DGX OS (Ubuntu 24.04)
・ 分散学習: vLLM(nvcr.io/nvidia/vllm:26.03-py3)
・ 分散処理フレームワーク: Ray(2.54.1)
セットアップ
物理的な設定に関しては、別記事にて紹介していますので、ご参照ください。
NVIDIA DGX Spark™ 4台で分散学習させてみた
また、セットアップはNVIDIA社の公式ドキュメントを参考に実施します。
vLLM for Inference
Step1 全nodeでの共通セットアップ
Step1.1 Rayのセットアップ
すべてのノードでvLLMクラスター展開スクリプトをダウンロードしてください。このスクリプトは分散推論に必要なRayクラスターのセットアップをおこないます。
wget https://raw.githubusercontent.com/vllm-
project/vllm/refs/heads/main/examples/online_serving/run_cluster.sh
chmod +x run_cluster.shStep1.2 vLLMのコンテナイメージの取得
sudo無しでdockerコマンドを実行できるようにするため、dockerグループにユーザーを追加します。
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp dockerその後、NGCコンテナカタログでvLLMコンテナを取得します。
今回はQwen3.5-397B-A17Bを使用するため、26.03-py3のイメージを使用します。
docker pull nvcr.io/nvidia/vllm:26.03-py3
export VLLM_IMAGE=nvcr.io/nvidia/vllm:26.03-py3Step1.3 LLMのModelのダウンロード
今回はnvidia/Qwen3.5-397B-A17B-NVFP4を使用します。 NVIDIA社はHugging FaceでオープンウェイトのModelをBlackwell世代で新たに対応したNVFP4形式に変換して提供しておりますので、今回はこちらを使用します。
弊社側でもNVIDIA DGX™ B200で始めるNVFP4推論 ~第1話:NVFP4とは~にてNVFP4形式やLLMの変換方法について紹介していますので、ぜひご参照ください。
仮想環境を作成し、huggingface_hubをインストールして、Modelをダウンロードします。
uv venv
source .venv/bin/activate
uv pip install -U huggingface_hub
hf auth login
hf download nvidia/Qwen3.5-397B-A17B-NVFP4Step2 Head nodeでのセットアップ
Head nodeでは下記の環境変数を設定して、クラスター展開スクリプトを実行します。 MN_IF_NAMEは実際のご自身の環境に合わせて設定ください。
export MN_IF_NAME=enp1s0f1np1
export VLLM_HOST_IP=$(ip -4 addr show $MN_IF_NAME | grep -oP '(?<=inet\s)\d+
(\.\d+){3}')
echo "Using interface $MN_IF_NAME with IP $VLLM_HOST_IP"
bash run_cluster.sh $VLLM_IMAGE $VLLM_HOST_IP --head ~/.cache/huggingface \
-e VLLM_HOST_IP=$VLLM_HOST_IP \
-e UCX_NET_DEVICES=$MN_IF_NAME \
-e NCCL_SOCKET_IFNAME=$MN_IF_NAME \
-e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \
-e GLOO_SOCKET_IFNAME=$MN_IF_NAME \
-e TP_SOCKET_IFNAME=$MN_IF_NAME \
-e RAY_memory_monitor_refresh_ms=0 \
-e MASTER_ADDR=$VLLM_HOST_IPStep3 Worker nodeでのセットアップ
Worker nodeでは下記の環境変数を設定して、クラスター展開スクリプトを実行します。MN_IF_NAME,HEAD_NODE_IPは実際のご自身の環境に合わせて設定ください。
export MN_IF_NAME=enp1s0f1np1
export VLLM_HOST_IP=$(ip -4 addr show $MN_IF_NAME | grep -oP '(?<=inet\s)\d+
(\.\d+){3}')
export HEAD_NODE_IP=<NODE_1_IP_ADDRESS>
echo "Worker IP: $VLLM_HOST_IP, connecting to head node at: $HEAD_NODE_IP"
bash run_cluster.sh $VLLM_IMAGE $HEAD_NODE_IP --worker ~/.cache/huggingface \
-e VLLM_HOST_IP=$VLLM_HOST_IP \
-e UCX_NET_DEVICES=$MN_IF_NAME \
-e NCCL_SOCKET_IFNAME=$MN_IF_NAME \
-e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \
-e GLOO_SOCKET_IFNAME=$MN_IF_NAME \
-e TP_SOCKET_IFNAME=$MN_IF_NAME \
-e RAY_memory_monitor_refresh_ms=0 \
-e MASTER_ADDR=$HEAD_NODE_IPクラスター展開の確認
Head nodeの別のターミナルを開いて、下記コマンドを実行し、クラスターが正常に展開されていることを確認します。
export VLLM_CONTAINER=$(docker ps --format '{{.Names}}' | grep -E '^node-[0-9]+$')
echo "Found container: $VLLM_CONTAINER"
docker exec $VLLM_CONTAINER ray status下記の通り、4GPUが認識されていることがわかります。
Resources
---------------------------------------------------------------
Total Usage:
0.0/80.0 CPU
0.0/4.0 GPU
0B/447.52GiB memory
0B/38.91GiB object_store_memory
From request_resources:
(none)
Pending Demands:
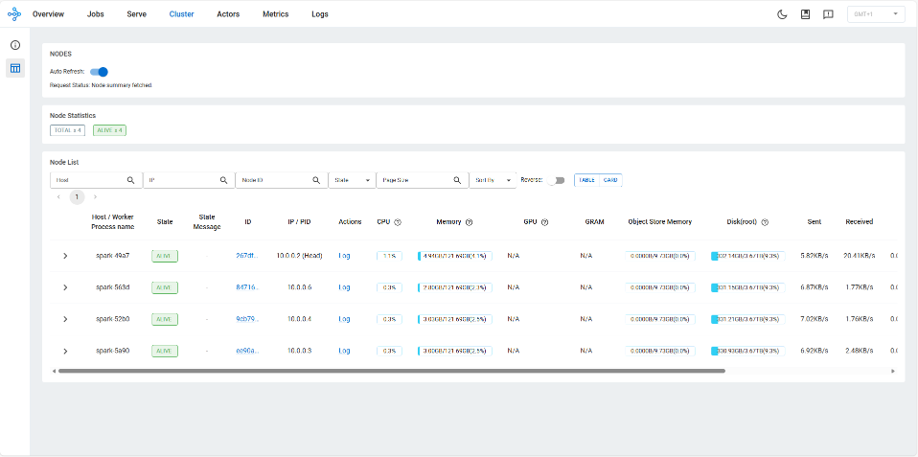
(no resource demands)また、<HEAD_NODE_IP>:8265にアクセスして、Ray Dashboardでクラスターの状態を確認することもできます。
下記のように、4nodeが正常に接続されていることがわかります。
分散推論の実施
Modelの展開
クラスターが正常に展開されたら、実際に分散推論を実施してみましょう。
export VLLM_CONTAINER=$(docker ps --format '{{.Names}}' | grep -E '^node-[0-9]+$')
docker exec -it $VLLM_CONTAINER /bin/bash -c '
vllm serve nvidia/Qwen3.5-397B-A17B-NVFP4 \
--tensor-parallel-size 4 --max-model-len 129000 --max-num-seqs 4 --trust-
remote-code'Modelの展開などでしばらく時間がかかりますが、下記のようなログが出力されれば、分散推論の準備は完了です。
(APIServer pid=5732) INFO: Started server process [5732]
(APIServer pid=5732) INFO: Waiting for application startup.
(APIServer pid=5732) INFO: Application startup complete.また、DGX Sparkの<HOST_IP>:11000にアクセスして、GPUの使用量を確認することも可能です。
推論の実行
別のターミナルで下記コマンドを実行して、推論を実行します。
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "nvidia/Qwen3.5-397B-A17B-NVFP4",
"prompt": "神奈川県の観光名所を2か所教えてください。",
"max_tokens": 4096, "temperature": 0.7
}'少し待つと下記のような応答が得られます。Qwen3.5をはじめとするReasoning Modelでは、推論の過程も多く生成されるため、応答まで少し時間がかかります。
また、max_tokensの値が小さいと思考の途中でmax_tokensを迎えてしまい、最終的な回答が生成されないので、十分に大きな値を設定することを推奨します。
神奈川県の代表的な観光名所を 2 つご紹介します。
1. **横浜中華街**
日本最 大級の中華街で、本格的な中華料理店やお土産屋さんが立ち並んでいます。
2. **鎌倉大仏(高徳院)**
鎌倉のシンボルである国宝の仏像で、歴史を感じられる人気スポットです。
Looks good.
7. **Output Generation** (matching the thought process).
</think>
神奈川県の代表的な観光名所を 2 つご紹介します。
1. **横浜中華街**
日本最大級の中華街で、本格的な中華料理店や雑貨店が立ち 並んでいます。食べ歩きやショッピングを楽しめる人気スポットです。
2. **鎌倉大 仏(高徳院)**
鎌倉のシンボルである国宝の仏像です。約 800 年の歴史を持ち、荘厳な雰囲気を感じられる県内有数の歴史観光スポットです。まとめ
今回は、DGX SparkとSN3700でGPUクラスターを構築し、分散推論をおこないました。
大きなModelをコストを気にせず使用することができるため、蒸留用の合成データの生成など大きなModelが動くこと自体に価値があるタスクには非常に有用です。
NVIDIA社では合成データ生成の為に、NVIDIA NeMo DataDesignerや、Nemotron Personas Japanを提供していますので、こちらもぜひご活用ください。
分散学習や分散推論の技術を学ぶ上で、小規模なクラスター構築は非常に良い勉強材料になります。
構築したクラスターで巨大なパラメータ数のModelから合成データを生成し、そのデータを使用して大きなパラメータ数のModelを学習することができます。
皆さんもぜひ試してみてください。
参考URL


お問い合わせはこちら

