- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2136件がヒットしています。check

はじめに
NVIDIA社からNVIDIA DGX Spark™が公開され、様々な用途で活用が進んでいます。SparkはGPUワークステーション単体としても優秀であり、ConnectX-7を搭載していることから、マルチノードでの作業にも優れた性能を発揮します。
実際にDGX Sparkを2台使った実装例は多くの方が紹介されています。
また分散学習や分散推論は今後のGPU活用に欠かせない技術ですが、なかなか環境を準備するのが大変だと思います。
今回は、より大規模なGPUクラスターを意識してNVIDIA® Spectrum®-2 SN3000 イーサネット スイッチとDGX Spark 4台を使用してGPUクラスターを構築し、分散学習を実施してした様子をご紹介します。

下段:NVIDIA Spectrum-2 SN3000 イーサネット スイッチ 1台
検証環境
ハードウェア
- GPU計算ノード: NVIDIA DGX Spark 4台
- ネットワークスイッチ: NVIDIA Spectrum-2 SN3000 イーサネット スイッチ 1台
ソフトウェア
- OS: DGX OS (Ubuntu 24.04)
- 分散学習: NeMo Automodel (Docker container)
- nvcr.io/nvidia/nemo-automodel:26.02.00
セットアップ
ネットワーク
まずはGPUクラスターの準備、つまり高速ネットワークで各Sparkが接続されている環境を作る必要があります。今回はDGX Spark内のパッケージ更新も必要だったため、インターネット側・高速ネットワーク側の両方のネットワークを準備しました。
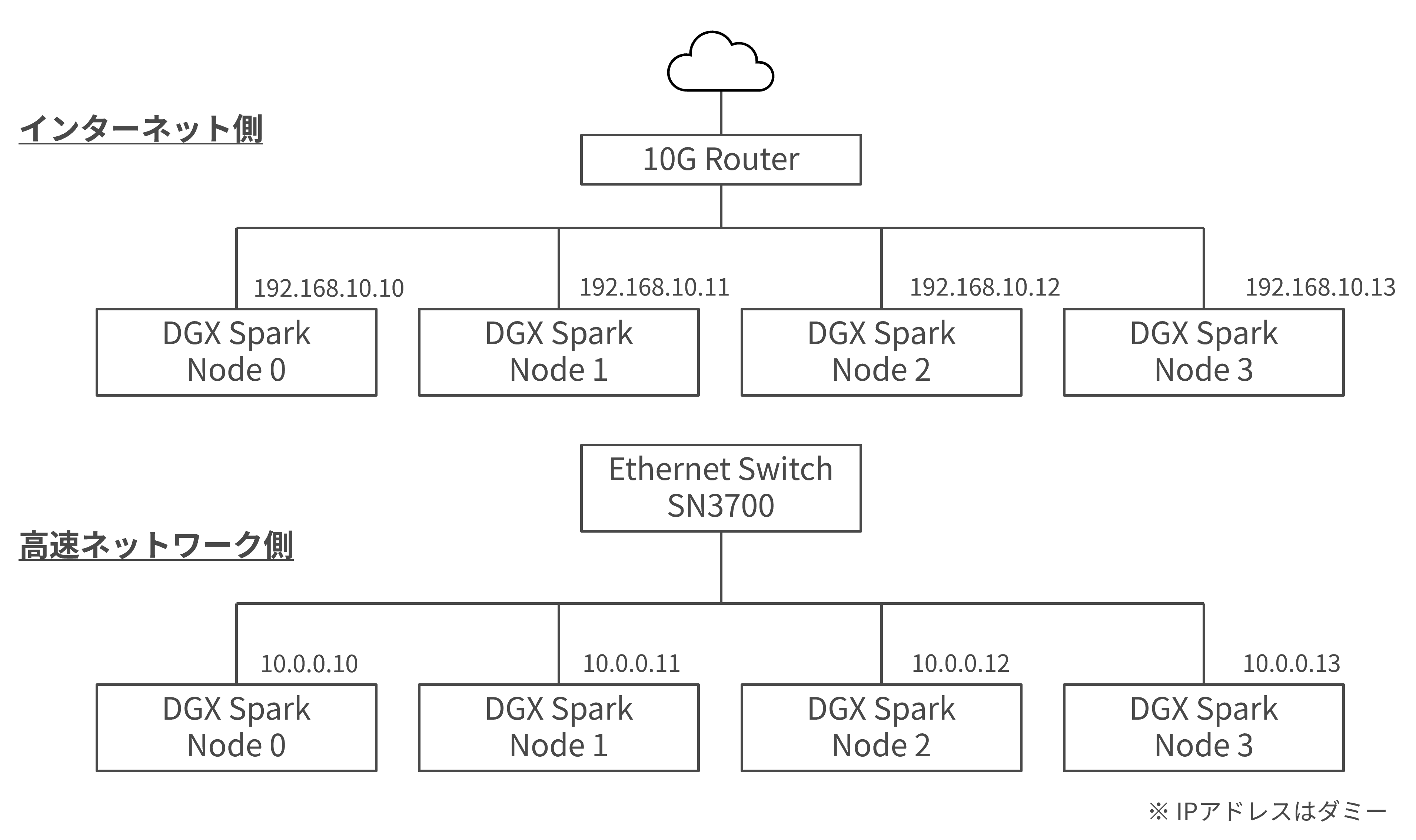
こちらのページが参考になります。1つのノードから高速ネットワークを介してpingが通ればOKです。
GPUクラスターの疎通確認
GPUクラスターとして正常に機能するかの確認には、nccl-test がよく使われます。DGX Spark 2台の事例を参考にDGX Spark 4台で設定し、動作確認を行います。
実行コマンド
mpirun -np 4 -H 10.0.0.10:1,10.0.0.11:1,10.0.0.12:1,10.0.0.13:1 --mca plm_rsh_agent "ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" -x LD_LIBRARY_PATH=$LD_LIBRARY_PATH $HOME/nccl-tests/build/all_gather_perf実行結果
Warning: Permanently added '10.0.0.11' (ED25519) to the list of known hosts.
Warning: Permanently added '10.0.0.12' (ED25519) to the list of known hosts.
Warning: Permanently added '10.0.0.13' (ED25519) to the list of known hosts.
# nccl-tests version 2.18.2 nccl-headers=22809 nccl-library=22809
# Collective test starting: all_gather_perf
# nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0 unalign: 0
#
# Using devices
# Rank 0 Group 0 Pid 61045 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 1 Group 0 Pid 61611 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 2 Group 0 Pid 63157 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 3 Group 0 Pid 59461 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
33554432 2097152 float none -1 1251.56 26.81 20.11 0 1222.51 27.45 20.59 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 20.3465
#
# Collective test concluded: all_gather_perf
#理論値200GbE(25 GB/s)に対し、20.3465 GB/sとなっており、妥当なスピードが出ていると考えられます。
分散学習の実施
分散学習用のコンテナ起動
各DGX SparkノードでNeMo Automodelのコンテナを起動します。
sudo docker run --gpus all -it --rm \
--ipc=host \
--net=host \
--privileged \
-w /opt/Automodel \
nvcr.io/nvidia/nemo-automodel:26.02.00 /bin/bash※テスト用のコマンドのため、実運用では注意してください。
分散学習ベンチマークの実行 (シングルノード)
マルチノードの検証の前に、まずはシングルノードで学習させてみます。
# 今回使用する`meta-llama/Llama-3.1-8B`モデルのダウンロードが必要なため、Hugging Faceへのログインと、モデル利用の申請を行っておきます。
hf auth login --token hf_XXXXXXXXXXXXXXシングルノードで実行
torchrun nemo_automodel/recipes/llm/benchmark.py --config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yaml実行結果(抜粋)
2026-03-26 06:25:40 | INFO | __main__ | ============================================================
2026-03-26 06:25:40 | INFO | __main__ | Benchmarking Summary
2026-03-26 06:25:40 | INFO | __main__ | ============================================================
2026-03-26 06:25:40 | INFO | __main__ | Total setup time: 412.62 seconds
2026-03-26 06:25:40 | INFO | __main__ | Total warmup time (5 steps): 580.72 seconds
2026-03-26 06:25:40 | INFO | __main__ | Total iteration time (5 steps): 576.31 seconds
2026-03-26 06:25:40 | INFO | __main__ | Average iteration time: 115.262 seconds (excluding first 5 warmup iterations)
2026-03-26 06:25:40 | INFO | __main__ | Average MFU: 3.708642% (excluding first 5 warmup iterations)
2026-03-26 06:25:40 | INFO | __main__ | ============================================================※サンプルレシピのまま実行すると、Average MFUは別GPUベースで表示されてしまうため無視します。今回、学習パフォーマンスの指標として扱う数値は Average iteration time です。
分散学習ベンチマークの実行 (マルチノード)
いよいよマルチノードで分散学習のベンチマークを取得します。全DGX Sparkで、マスターノードのIPアドレスや各インターフェースを設定します。
分散学習のための変数設定(例)
export MASTER_ADDR=10.0.0.1
export MASTER_PORT=29500
export NCCL_SOCKET_IFNAME=enP2p1s0f0np0
export GLOO_SOCKET_IFNAME=enP2p1s0f0np0
export UCX_NET_DEVICES=enP2p1s0f0np0※ 高速ネットワーク側のインターフェースを指定してください
ベンチマーク実行コマンド(マスターノード)
torchrun \
--nnodes=4 \
--nproc-per-node=1 \
--node_rank=0 \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
nemo_automodel/recipes/llm/benchmark.py \
--config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yamlベンチマーク実行コマンド (ワーカーノード)
torchrun \
--nnodes=4 \
--nproc-per-node=1 \
--node_rank=<1-3まで設定> \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
nemo_automodel/recipes/llm/benchmark.py \
--config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yaml※ 各Sparkごとに、`--node_rank=1,2,3`と変更して実行してください
分散学習ベンチマークの結果
今回はDP=4 (分散学習のパラメータ)で動かしました。
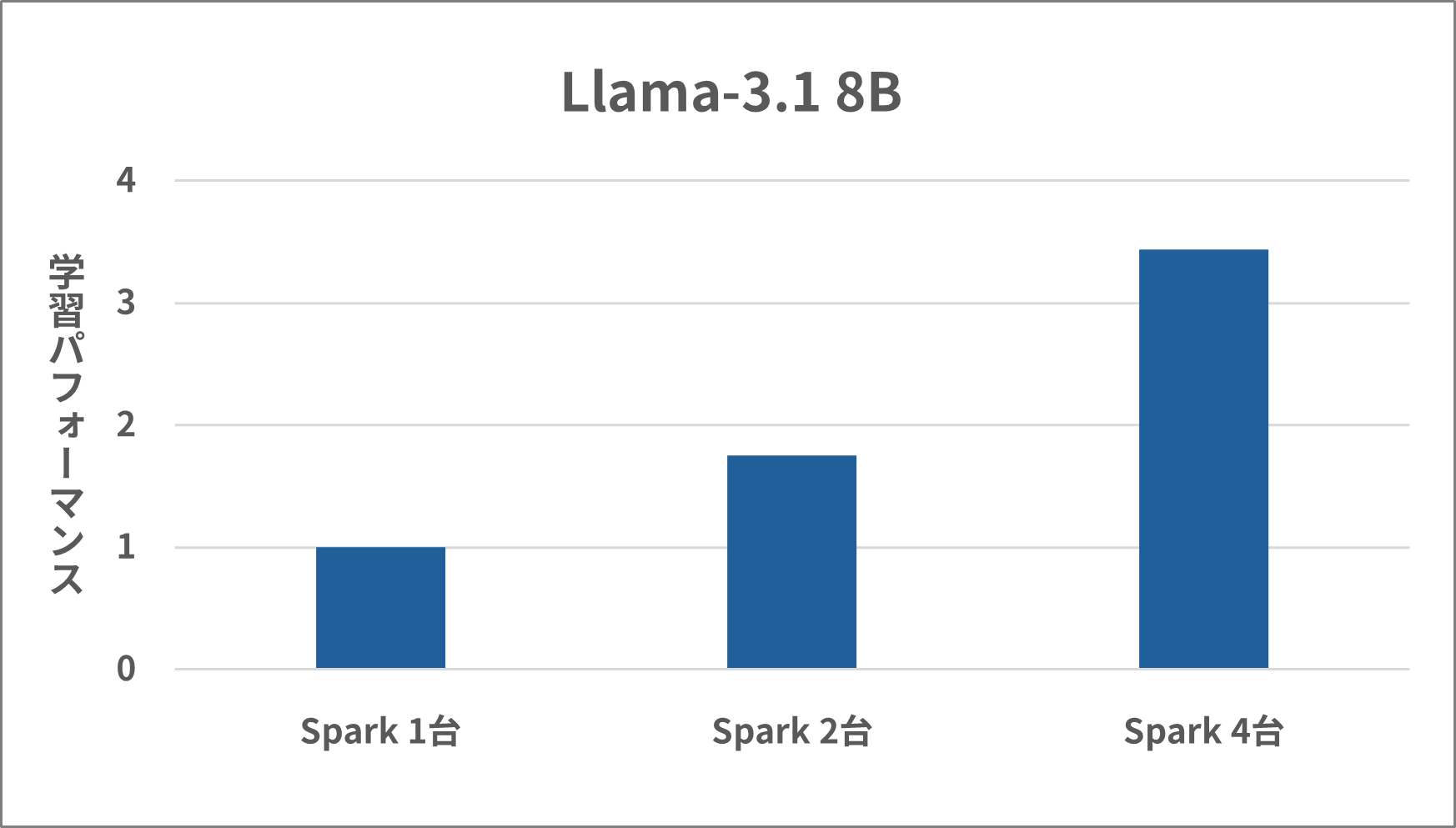
Spark 1台を基準とした学習パフォーマンスの指標は、Spark 2台で約1.75倍、4台で約3.44倍の結果となりました。
DGX Sparkの台数を増やしても、ネットワークがボトルネックにならず、効率的に学習速度を向上できていることがわかります。
まとめ
今回は、DGX SparkとSN3700でGPUクラスターを構築し、Spark 1台、2台、4台構成での学習時間を比較しました。
✅ 高速ネットワークの活用
- 200GbEの高速接続により、クラスター間の通信がボトルネックになりにくい
- ノード(DGX Spark)間のデータ転送がスムーズに行われ、効率的な分散学習が可能
✅ リニアスケーリングを実現
- Spark 1台と比較して、4台構成では約3.44倍の高速化を達成
- ノード数を増やすことで、ほぼリニアにスケールすることを確認
分散学習や分散推論の技術を学ぶ上で、小規模なクラスター構築は非常に良い勉強材料になります。皆さんもぜひ試してみてください。
お問い合わせ
NVIDIA DGX Sparkの導入をご検討の方は、ぜひお問い合わせください。


