- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2141件がヒットしています。check

[NVIDIA DGX Sparkで試すAIペルソナマーケティング]
第1話 デモの概要
第2話 調査対象の抽出
第3話 質問の生成
第4話 回答の生成と収集
第5話 調査結果の可視化
第6話 まとめ
本話の内容
本話では、ペルソナデータであるNemotron-Personas-Japanデータセット(*1)をダウンロードし、そこからアンケートの調査対象を抽出するまでを解説いたします。
*1: Fujita, A., Gong, V., Ogushi, M., Yamamoto, K., Suhara, Y., Corneil, D., & Meyer, Y. (2025). Nemotron-Personas-Japan: Synthetic Personas Aligned to Real-World Distributions. https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
ペルソナデータのダウンロード
Nemotron-Personas-JapanデータセットはHugging Face Hubから以下のようにダウンロードできます。
from huggingface_hub import hf_hub_download
import cudf
import json# Nemotron-Personas-JapanデータセットのファイルをHugging Face Hubからダウンロード
num_files = 8
file_list = []
for i in range(num_files):
filename = f"data/train-{format(i, '#05d')}-of-{format(num_files, '#05d')}.parquet"
path = hf_hub_download(repo_id="nvidia/Nemotron-Personas-Japan", filename=filename, repo_type="dataset")
file_list.append(path)
file_listデータセットの読み込み
Nemotron-Personas-JapanデータセットはParquet形式のファイルとして提供されているため、NVIDIA RAPIDSエコシステムの一部であるcuDFを利用して読み込むことができます。cuDFはGPUアクセラレーションを活用したPython DataFrameライブラリーであり、Pandasと互換性のあるAPIを提供し、大規模データの読み込み、フィルタリング、操作をGPU上で高速(最大150倍 *2)に処理します。
*2: RAPIDS cuDF、コード変更ゼロで pandas を約 150 倍高速化
df = cudf.read_parquet(file_list)
print(f"Number of rows: {len(df)}")
print("Column Names:")
print(df.columns)Number of rows: 1000000
Column Names:
Index(['uuid', 'professional_persona', 'sports_persona', 'arts_persona',
'travel_persona', 'culinary_persona', 'persona', 'cultural_background',
'skills_and_expertise', 'skills_and_expertise_list',
'hobbies_and_interests', 'hobbies_and_interests_list',
'career_goals_and_ambitions', 'sex', 'age', 'marital_status',
'education_level', 'occupation', 'region', 'area', 'prefecture',
'country'],
dtype='object')以下のように、Pandasと同じ方法で、条件に合致する行を抽出できます。
# 年齢が20歳以上30歳未満のレコードを抽出
df[(df["age"] >= 20) & (df["age"] < 30)].sample(10) # 抽出したデータからランダムに10行を表示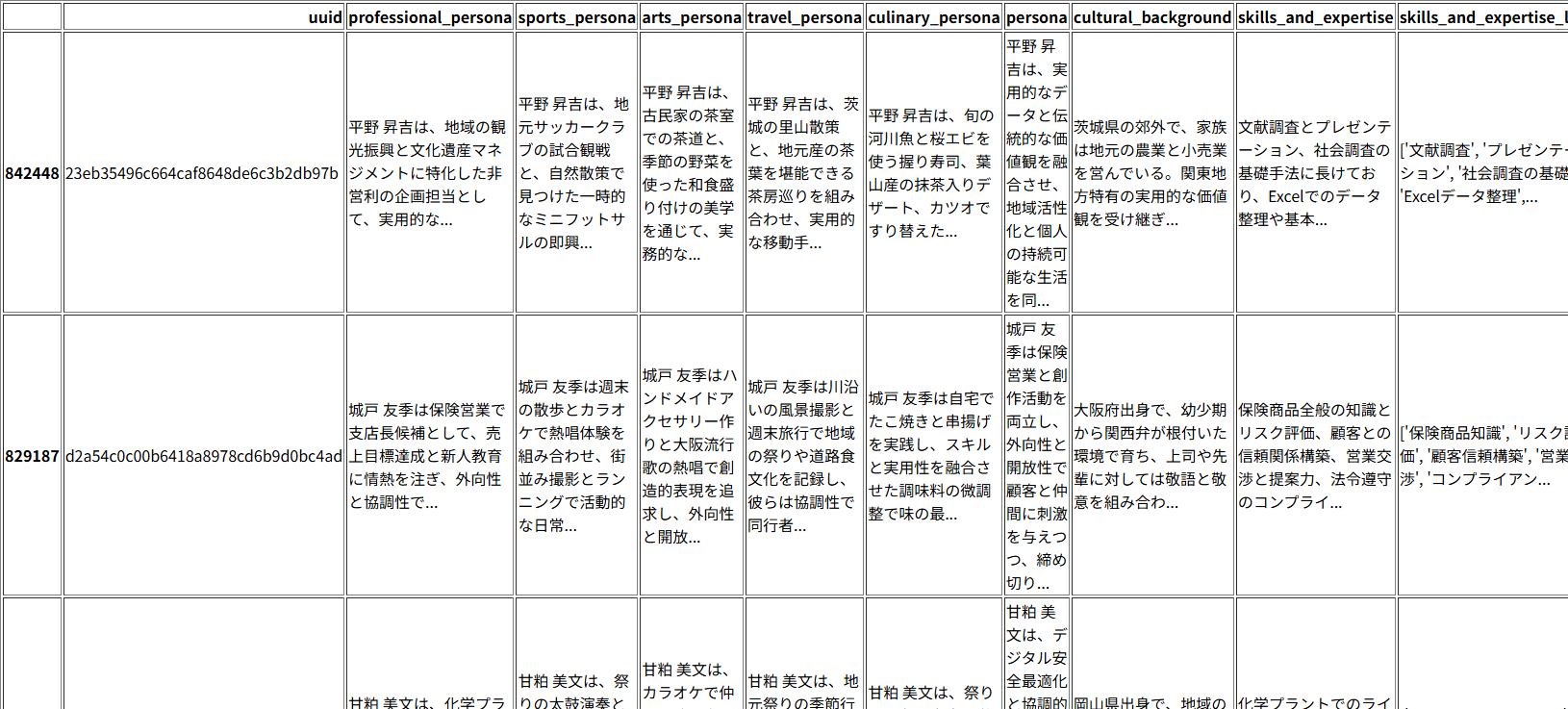
抽出した行の一部が表示されている様子
※Nemotron-Personas-JapanデータセットはAIが生成したものなので、表示されている人物名は架空の人物の名前です。
アンケート対象の抽出
アンケート対象者(*3)を以下のように抽出します。本デモでは、Nemotron-Personas-Japanデータセットに収められている架空の人物100万名の中から、20歳以上かつ30歳未満を無作為に1000名を抽出して調査対象にしました。
*3: Nemotron-Personas-Japanデータセットでは、一人の(架空)人物が6つのペルソナと、16個の属性を持っています。本デモでは、それらすべて(UUIDを除く)をLLMに与えて、アンケート調査を実施します。
# 条件に合致するレコード数を抽出
filtered_df = df[
(df["age"] >= 20)
& (df["age"] < 30)
].sample(1000)
len(filtered_df)# cuDFデータフレームをPandasデータフレームに変換
filtered_df = filtered_df.to_pandas()
len(filtered_df)# JSONL形式で保存
filtered_df.to_json("personas.jsonl", orient="records", force_ascii=False, lines=True)本話のまとめ
Nemotron-Personas-Japanデータセットをダウンロードして、ユーザーの条件設定に合致する調査対象者を抽出する方法をご紹介しました。Nemotron-Personas-Japanデータセットは100万人分のペルソナを持つ巨大なデータセットですが、cuDFのDataFrameに読み込むことで、NVIDIA社製GPUによる高速データアクセスが実現されます。
次話では、LLMを使ってアンケートの質問文と選択肢を生成する方法を解説いたします。
お問い合せはこちら

