- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2138件がヒットしています。check

[NVIDIA DGX Sparkで試すAIペルソナマーケティング]
第1話 デモの概要
第2話 調査対象の抽出
第3話 質問の生成
第4話 回答の生成と収集
第5話 調査結果の可視化
第6話 まとめ
ペルソナマーケティングとは?
ペルソナ(Persona)とは、ユーザー中心設計やマーケティングにおいて、サイト、ブランド、製品を使用する典型的なユーザーを表すために作成された仮想的な人物像のことです。 出典:Wikipedia:ペルソナ (ユーザーエクスペリエンス)
このペルソナを使って、マーケティング活動の精度を上げる取り組みがペルソナマーケティングと呼ばれます。近年、大規模言語モデル(LLM)の発展に伴い、ペルソナマーケティングにLLMを取り入れ、効率化を図る試みが増加しています。設定したペルソナになりきったLLMを「AIペルソナ」や「デジタルペルソナ」と呼び、以下のようなユースケースが考えられます。
- AIペルソナに対して、アンケート調査を行う。
- AIペルソナと討議を重ねながら、製品企画を練る。
本デモの目的
本記事で紹介するAIペルソナマーケティング・デモの目的は以下の通りです。
- 日本の人口統計、職業、生活背景を反映したペルソナの合成データセットであるNemotron-Personas-Japan(*1)から抽出したペルソナを基に、LLMがアンケート調査に回答するプロセスを示す。
- アンケートの質問と選択肢の作成もLLMに託し、それが機能することを示す。
- 上記プロセスをすべて、NVIDIA DGX Spark™上で実施できることを示す。
*1: Fujita, A., Gong, V., Ogushi, M., Yamamoto, K., Suhara, Y., Corneil, D., & Meyer, Y. (2025). Nemotron-Personas-Japan: Synthetic Personas Aligned to Real-World Distributions. https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
本デモの題材(仮想的なもので、現実のプロジェクトは存在しない)
グミ菓子の新製品企画のため、ターゲットとなる消費者(*2)にアンケートを実施し、以下の事項を決定するためのヒントを得ることを想定します。
- フレーバー
- パッケージデザイン
- CMに起用するタレント
以下のプロセスに対してLLMを用います。
- アンケート作成
- アンケート回答
デモプログラムはPythonで実装し、Jupyterノートブック上で動作確認を行いました。
*2: 本デモではペルソナデータを与えられたLLMが消費者に成り代わってアンケートに回答する。
注意事項
- 本デモに採用した方法が実際のマーケティング活動において効果を発揮するかどうかは保証しません。
- LLMに対するアンケート調査が、人間に対するアンケート調査を完全に代替するとは考えておらず、あくまで、補助的なものと認識しています。
- 本デモにおいては、手軽に試すことを重視して、Nemotron-Personas-Japanデータセットをそのままペルソナデータとして利用しましたが、Nemotron-Personas-Japanデータセットの本来の利用目的は、ユーザーが独自の合成データを生成する際に、そのシードとすることです。
参考:Nemotron-Personas-Japan を用いた NVIDIA NeMo Data Designer による合成データ生成
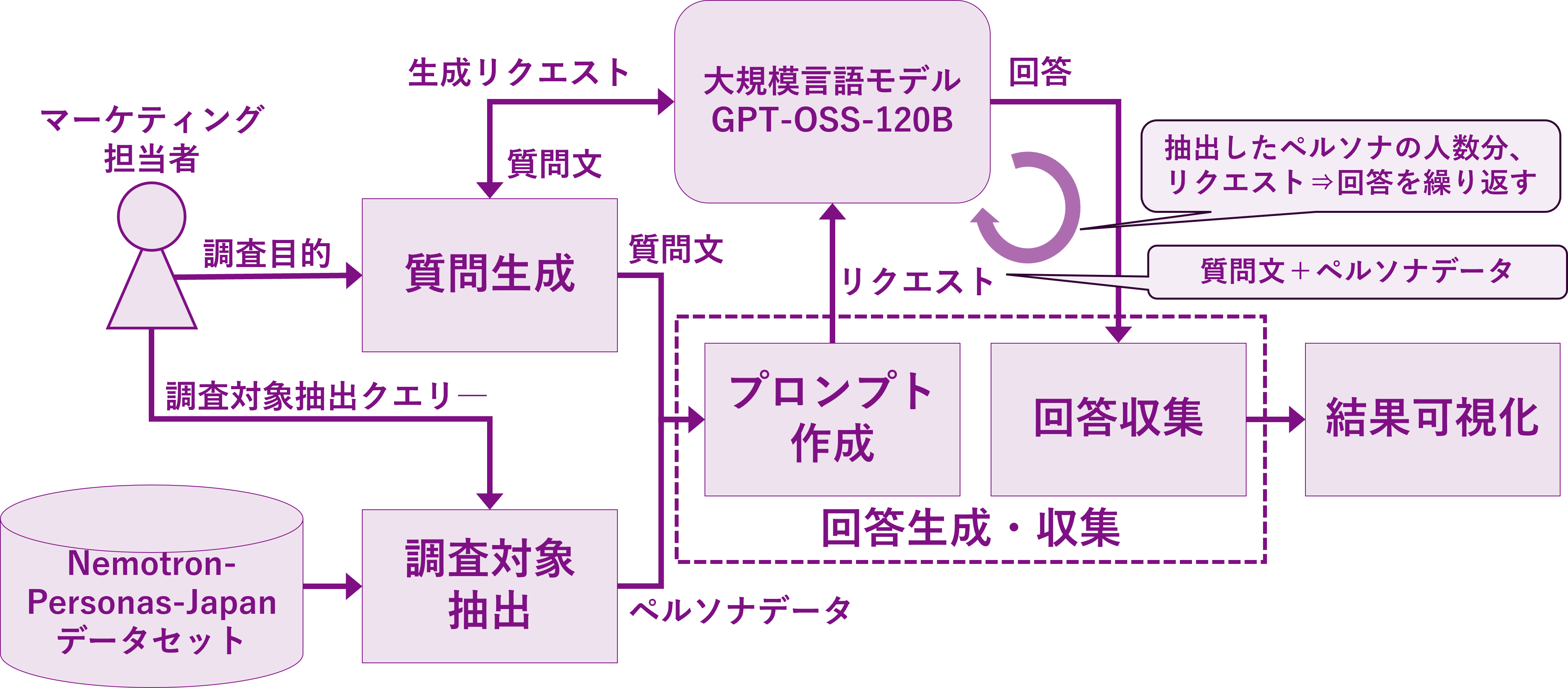
処理パイプライン
本デモの処理パイプラインは以下のとおりです。
1.調査対象抽出
- Nemotron-Personas-JapanデータセットをcuDFデータフレームに読み出し、条件設定により調査対象を抽出する
2.質問生成
- 調査目的と質問数など条件を記載したプロンプトをLLMに与え、LLMから質問文と選択肢のセットを得る
3.回答生成・収集
- ペルソナデータと質問からプロンプトを作成して、ペルソナになりきったLLMから回答を取得する
- 上記の処理を、抽出したペルソナ人数分繰り返す
4.結果可視化
- 結果を集計してグラフ表示する
データセット
ペルソナデータとして、NVIDIA社が公開しているNemotron-Personas-Japanデータセットを利用しました。
Nemotron-Personas-Japanデータセットの特長は以下のとおりです。
データセットの特長
- 日本における人口の多様性と豊かさを捉えることを目的とし、実世界の人口統計、地理的分布、性格特性の分布に基づいて合成的に生成されたペルソナのオープンソースデータセット
データセットの内容
- 日本語で記録された 100万件のレコード(1レコードあたり6つのペルソナ → 合計600万ペルソナ)
- 22フィールド:6つのペルソナフィールドと、公式の人口統計・労働統計に基づく16のコンテキストフィールド
- 約14億トークン数(うちペルソナ関連トークン約8.5億)
- 人口統計・地理・性格特性などの軸にまたがる包括的なデータ
- 約95万件のユニークな名前
- 日本の労働人口を反映する1,500以上の職業カテゴリ
- プロフェッショナル、スポーツ、芸術、旅行、料理など多様なペルソナタイプ
- 文化的背景、スキルと専門性、目標と志向、趣味や関心といった自然言語のペルソナ属性
ハードウェア
本デモは、LLMを含め、上記処理パイプラインのすべてを、NVIDIA DGX Spark(*3)上でローカルに実行します。
NVIDIA DGX Sparkの特長は以下のとおりです。
- NVIDIA GB10 Grace Blackwell Superchip搭載
- 電力効率に優れたコンパクトなフォームファクター
- 1 PFLOP(FP4)のAI性能
- 128GB LPDDR5x統合システムメモリー
- LLMをローカルで実行
*3: NVIDIA社のパートナーから発売されているNVIDIA GB10 Grace Blackwell Superchip搭載システムを含む
本話のまとめ
NVIDIA DGX Spark上に構築したAIペルソナマーケティング・デモの概要についてご紹介しました。次話では、Nemotron-Personas-Japanデータセットを入手し、調査対象を抽出する方法について解説いたします。
お問い合わせはこちら

