- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2132件がヒットしています。check

今回の内容
近年、生成AIの進化により、企業や研究機関では「ローカルLLM(大規模言語モデル)」の導入が急速に進んでいます。クラウド型のAIサービスが一般化する中で、ローカル環境でのLLM運用は、セキュリティの確保、カスタマイズ性の向上、そしてコスト最適化といった観点から、非常に有効な選択肢となっています。
第2話である本記事では、ローカルLLMを構築するために必要なシステム全体像、ハードウェア・ソフトウェアの要件、代表的なOSSツール、そしてマクニカが提供するサポート情報について、実践的な視点から詳しく解説します。
[ローカルLLM入門]
第2話 ローカルLLMを実際に構築するには?
システム全体像の概要
ローカルLLMの構築には、複数の技術要素が連携するシステム設計が求められます。主な構成要素は以下の通りです:
- 計算資源:モデルの学習や推論を行うためのGPUサーバー
- データ管理:学習データやモデルファイルを保存・管理するストレージ(例:S3互換)
- ネットワーク環境:複数ノード間の通信や外部連携を可能にするネットワークスイッチ
- 制御・運用ソフトウェア:モデルの実行、トレーシング、エージェント構成などを担うツール群
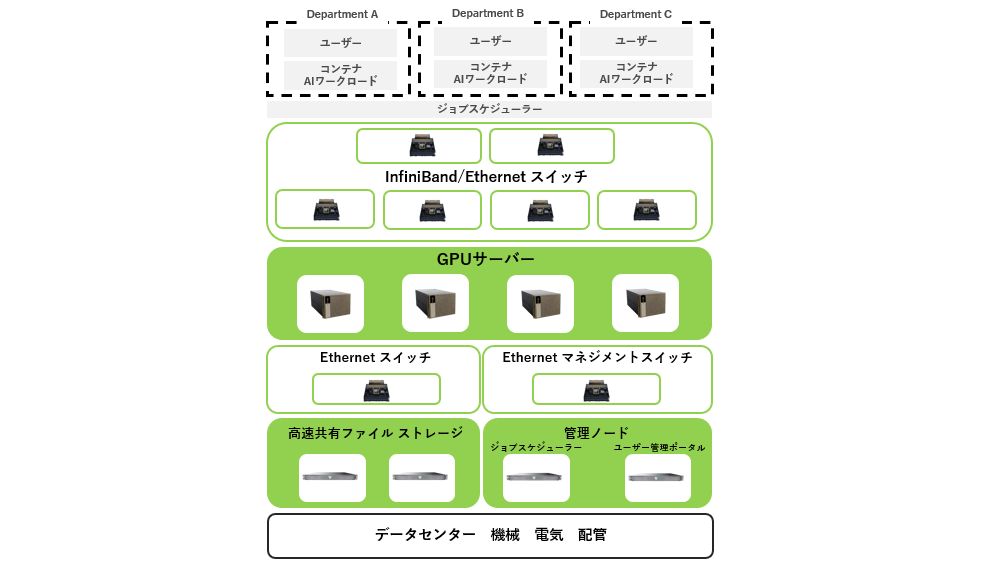
これらを組み合わせることで、用途に応じた柔軟なLLM運用が可能になります。推論専用の軽量構成から、学習も可能な高性能構成まで、目的に応じた設計が重要です。特に、社内データを活用したファインチューニングやRAG(Retrieval-Augmented Generation)構成を検討する場合は、データベースや検索エンジンとの連携も視野に入れる必要があります。
必要なハードウェア
ローカルLLMの中核を担うのがGPUサーバです。CPUやRAMも重要ですが、特にGPUの性能がモデルの処理速度や精度に直結します。推論のみを行う場合は比較的軽量な構成でも対応可能ですが、70B規模のモデルを扱う場合は、複数枚の高性能GPU(例:NVIDIA H200/B200など)と大容量メモリーが必要です。
また、モデルの量子化(Quantization)を活用することで、必要なリソースを抑えつつ高精度な推論を実現することも可能です。量子化には、INT4やINT8といった形式があり、モデルサイズを大幅に削減しながらも、実用的な精度を維持できます。
用途によっては、S3互換のストレージや高速ネットワークスイッチの導入も検討されます。特に複数ノードでの分散推論や学習を行う場合は、帯域幅やレイテンシーの最適化が重要です。
構成例としては、下記のような製品を参考にすることで、目的に応じたハードウェア選定がスムーズに進みます。
以下ページでは、用途別に最適化されたサーバ構成が紹介されており、導入検討時の参考になります。
モデルごとのGPU要件の一例については、以下の表をご参照ください。
|
Model |
GPU |
Precision |
Profile |
# of GPUs |
Disk Space |
|
DeepSeek R1 DistillLlama 8B RTX |
RTX 6000 Ada Generation |
INT4 AWQ |
Throughput |
1 |
5.42 |
|
GeForce RTX 5090 |
INT4 AWQ |
Throughput |
1 |
5.42 |
|
|
GeForce RTX 5080 |
INT4 AWQ |
Throughput |
1 |
5.42 |
|
|
GeForce RTX 4090 |
INT4 AWQ |
Throughput |
1 |
5.42 |
|
|
GeForce RTX 4080 |
INT4 AWQ |
Throughput |
1 |
5.42 |
|
|
Llama 3.2 1B Instruct |
L40S |
FP8 |
Throughput |
1 |
1.47 |
|
FP8 |
Throughput LoRA |
1 |
2.89 |
||
|
BF16 |
Throughput |
1 |
2.9 |
||
|
BF16 |
Throughput LoRA |
1 |
1.97 |
||
|
Llama 3.2 3B Instruct |
L40S |
FP8 |
Throughput |
1 |
4.17 |
|
FP8 |
Throughput LoRA |
1 |
4.17 |
||
|
FP16 |
Throughput |
1 |
6.79 |
||
|
FP16 |
Throughput LoRA |
1 |
6.79 |
|
Model |
GPU |
Precision |
Profile |
# of GPUs |
Disk Space |
|
Llama 3.3 70B Instruct |
H200 |
FP8 |
Throughput |
1 |
67.88 |
|
FP8 |
Latency |
2 |
68.23 |
||
|
BF16 |
Throughput |
2 |
68.23 |
||
|
FP8 |
Throughput |
2 |
68.1 |
||
|
FP8 |
Throughput LoRA |
2 |
68.22 |
||
|
BF16 |
Latency |
4 |
68.82 |
||
|
FP8 |
Latency |
4 |
68.68 |
||
|
BF16 |
Throughput |
4 |
68.76 |
||
|
Llama 3.1 405B Instruct |
H100 SXM |
FP8 |
Latency |
8 |
388.75 |
|
FP16 |
Latency |
16 |
794.9 |
||
|
A100 SXM |
PP16 |
Latency |
16 |
798.2 |
※NVIDIA NIM™ for Large Language Models (LLMs) : Supported Models を参照
※その他:https://docs.nvidia.com/nim/large-language-models/latest/supported-models.html#llama-3-3-70b-instructを参照
※2025/8月現在
メモリー使用量と計算負荷を削減する技術:量子化とデータ型の工夫
LLM(大規模言語モデル)の推論や学習には、大量のメモリーと計算資源が必要です。そのため、効率化のための技術がいくつか活用されています。まず、LLMの重みデータ(パラメーター)は通常、16ビット(BF16)や32ビットの浮動小数点数で表現されます。特に学習時には、一定の精度を保つために高精度なデータ型が使われる傾向があります。
一方で、推論時のメモリー使用量を削減し、処理速度を向上させるために「量子化(Quantization)」という手法が用いられることがあります。これは、重みデータのビット数をさらに小さくすることで、モデルのサイズを圧縮する技術です。たとえば、16ビットの重みを8ビットや4ビットのに変換することで、必要なメモリー量をそれぞれ1/2、1/4に抑えることができます。
ただし、量子化にはトレードオフもあります。ビット数を減らすことでモデルの精度が若干低下する可能性があるため、用途に応じたバランスが求められます。特に高精度が求められる業務では、量子化の影響を十分に評価した上で導入することが重要です。
このような技術を活用することで、限られたGPUリソースでも大規模モデルの運用が可能になります。ローカルLLM構築においては、こうした最適化手法の理解と活用が、実用的なシステム設計の鍵となります。
必要なソフトウェア
ローカルLLMの運用には、モデルの管理・実行・連携を支えるソフトウェアが不可欠です。代表的なOSS(オープンソースソフトウェア)としては、以下のようなツールが挙げられます。
・LangChain:複数の言語モデルや外部ツール(検索、計算、データベースなど)を連携させて、柔軟で高度な対話型アプリケーションを構築できるPythonベースのフレームワークです。エージェント機能やチェーン構造により、複雑な処理を段階的に実行できます。
・Llama.cpp や vLLM:軽量な推論環境を提供するOSS。量子化モデルとの相性も良好で、ローカル環境での高速推論に適しています。
これらのOSSは、柔軟性と拡張性に優れており、社内システムとの統合や独自機能の追加も可能です。一方で、OSSの運用には一定の技術的知見が求められるため、商用サポート付きの製品を選択するケースもあります。
その場合、OSSとNVIDIA独自の技術が使用された、以下のようなツール群(SDK)を活用することも選択肢の1つとなります:
・NeMo:NVIDIA製のLLM開発・運用フレームワーク。事前学習済みモデルやファインチューニング機能を提供し、商用環境での安定運用が可能です。
・NIM:推論APIをマイクロサービスとして提供し、スケーラブルな運用が可能。Kubernetes環境との親和性も高く、クラウドネイティブな構成にも対応します。
・Blueprint:LLMアプリケーションの設計テンプレートを提供。迅速な開発を支援し、PoCから本番環境への移行をスムーズにします。
・Agent Toolkit:エージェント構成を簡単に構築できるツール群。業務フローに沿ったAIエージェントの設計が可能です。

ローカルLLMの構築は、単なる技術導入ではなく、業務プロセスやデータ活用の在り方を根本から見直す機会でもあります。ハードウェアの選定、ソフトウェアの構成、セキュリティ対策、そして運用体制の整備まで、総合的な視点が求められます。
もし構築にあたって課題や不安がある場合は、マクニカが提供するサポートをご活用ください。NVIDIA製品を中心とした構築支援や技術相談を通じて、安心・確実な導入をサポートいたします。詳しくは、以下のページをご覧ください。
次回、ローカルLLMを構築するために必要なシステム全体像を解説!
本記事では、ローカルLLMを構築するために必要なシステム全体像、ハードウェア・ソフトウェアの要件、代表的なOSSツール、そしてマクニカが提供するサポート情報について解説いたしました。
次回は、軽量ファインチューニング手法であるLoRA、社内データを活用したRAG(検索拡張生成)、そしてセキュリティ・運用面での技術的な注意点について詳しく解説します。
お見積もり/お問い合わせはこちら

