- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2132件がヒットしています。check

今回の内容
生成AIの進化により、企業の業務効率化やサービス高度化が加速しています。その中でも注目されているのが「ローカルLLM(大規模言語モデル)」の構築です。本連載では、3話に渡って初心者エンジニアの方々を対象に、ローカルLLMの基礎からユースケースまでを体系的に解説し、構築の第一歩を踏み出すための知識を提供します。
第1話である本記事では、ローカルLLMの基礎と活用完全ガイドについてご紹介いたします。
[ローカルLLM入門]
第1話 ローカルLLMの基礎と活用完全ガイド
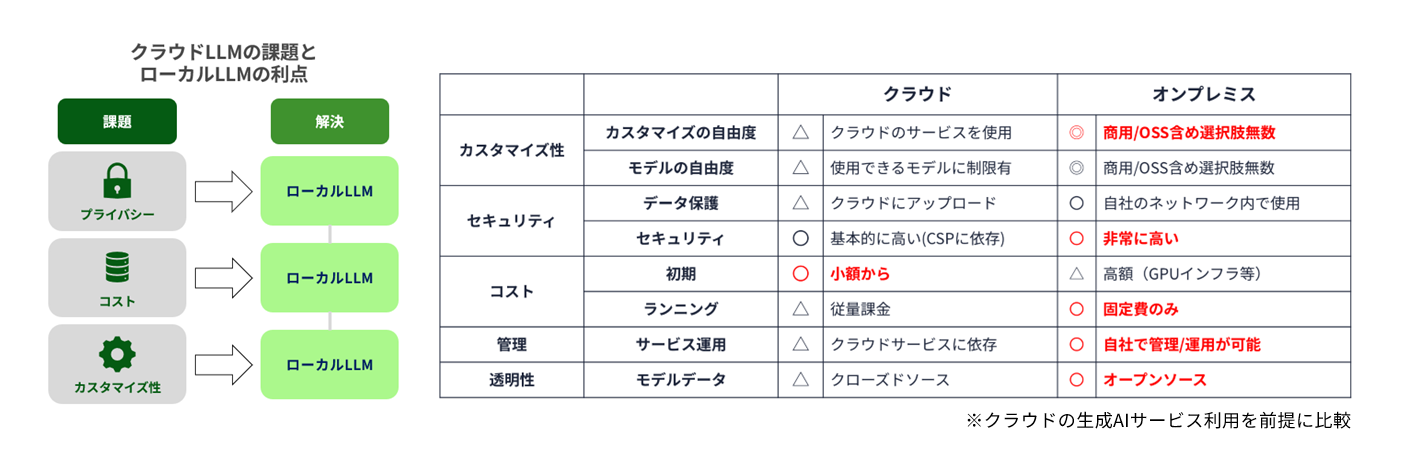
なぜ今ローカルLLMなのか?
ローカルLLMが求められる背景には、主に3つの理由があります。
1つ目はプライバシーの確保です。クラウド型LLMでは、社内の機密情報や個人情報を外部に送信する必要があり、情報漏洩のリスクがつきまといます。特に金融、医療、製造業などでは、クラウドに上げられないデータが多く、ローカルでの処理が必須です。
2つ目はコストの最適化です。クラウドLLMは従量課金制が一般的で、利用量が増えるとコストも比例して高騰します。ローカルLLMであれば、初期投資は必要ですが、長期的にはコストを抑えることが可能です。
3つ目はカスタマイズ性です。クラウドLLMではモデルの挙動を細かく制御することが難しい場合がありますが、ローカル環境であれば、オープンウェイトモデルを活用して独自のファインチューニングやRAG(検索拡張生成)を行うことができます。
ただし、ローカルLLMの構築には高性能なGPUや専門的な知識が必要であり、OSSだけでは限界があります。そこで、NVIDIAのハードウェアとマクニカの技術支援が、実用的かつ安定したローカルLLMの実現において重要な役割を果たします。
LLMの基礎知識:ローカル構築の前に知っておきたいこと
LLM(大規模言語モデル)とは、大量のテキストデータを学習し、人間のような自然な文章を生成するAIモデルです。代表的な例としてChatGPT、Llama、Mistral、DeepSeek、Claudeなどがあり、質問応答、要約、翻訳、コード生成など多様な用途に活用されています。

LLMには「クラウド型」と「ローカル型」があり、それぞれにメリットと課題があります。クラウド型は導入が容易でスケーラブルですが、プライバシーやコスト、カスタマイズ性に制限があります。一方、ローカル型は自由度が高く、セキュリティ面でも安心ですが、構築や運用には専門知識と高性能なハードウェアが必要です。
また、LLMの中にはオープンウェイト(Open Weight)モデルと呼ばれるものがあります。これは、ニューラルネットワークの重みデータが公開されているLLMで、再学習やファインチューニングが可能です。代表的なオープンウェイトLLMには、Meta社のLlama、Google社のGemma、Mistral AI社のMistralなどがあり、Hugging Face Hubで公開されるのが一般的です。一方、OpenAI社の商用ベースのモデルはクローズドモデルであり(2025/8月現在)、ファインチューニングはOpenAI社のツールを通じてのみ可能で、処理内容の詳細は非公開です。
基本用語の理解も重要です。「トークン」はモデルが処理する文字列の単位で、「モデルサイズ」は学習に使われたパラメーターの数を指します。例えば、Llama 8Bは80億、70Bは700億、405Bは4,050億パラメーターを持ち、サイズが大きいほど高精度ですが、必要なGPUメモリーも増加します。
技術的な観点では、LLMをサービスとして提供するには「推論サーバー」が必要です。これは、ユーザーからの入力に対してリアルタイムに応答を返す仕組みで、GPUの性能が応答速度に直結します。モデルサイズが大きくなるほど、必要なVRAMも増加します。例えば、Llama 3.1-8Bは約16GB、70Bは約141GB、405Bでは812GBものVRAMが必要となり、複数GPUや分散処理が不可欠です。
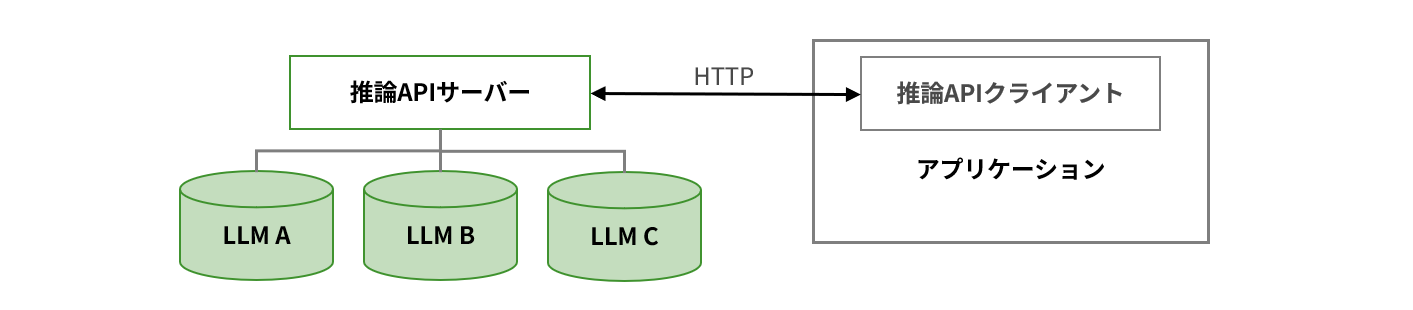
※通信形式はOpenAI Chat Completions APIに準拠するのが一般的。
※推論サーバーの性能が、リクエスト→回答遅延やリクエストのスループットに影響
モデルごとのGPU要件の一例については、以下の表をご参照ください。
| 規模 | モデル | パラメーター数 | Precision | 必要なメモリー量 |
| 小 | meta-llama/Llama-3.1-8B-Instruct | 8.03Billion(80.3億) | BF16 | 16.06GB(8.03x2) |
| 中 | meta-llama/Llama-3.1-70B-Instruct | 70.6Billion(706億) | BF16 | 141.2GB(70.6x2) |
| 大 | meta-llama/Llama-3.1-405B-Instruct | 406Billion(4060億) | BF16 | 812GB(406 x2) |
※その他ワーキングメモリー分もVRAMに必要。
※中規模程度のLLMになると、複数のGPUカードにまたがってロードする必要がある。
※RAGなどを活用した推論サーバーの構築の前提。学習には高性能なGPU環境が求められる。
このような技術的要件を理解することで、ローカルLLM構築の難易度と必要な支援が明確になります。マクニカでは、こうした課題を乗り越えるための技術支援を提供しています。
ローカルLLMのユースケース:現場で活きる活用例
ローカルLLMは、企業の現場で多様な業務支援に活用できます。ここでは、実際のユースケースを紹介しながら、ローカルLLMの可能性を具体的にイメージしていただきます。
まずは社内チャットボットです。社内規定や業務マニュアル、FAQなどを学習させたLLMを活用することで、従業員からの問い合わせに即時対応できるAIアシスタントを構築できます。これにより、総務・人事・IT部門の負担を軽減し、業務効率を向上させることが可能です。
次に、ドキュメント検索・要約です。社内に蓄積された膨大な資料や議事録、技術文書を対象に、自然言語での検索や要約を行うことで、情報の利活用が飛躍的に高まります。特にRAG(検索拡張生成)を活用すれば、特定の文書に基づいた正確な回答を生成することができます。
また、コード補完やレビュー支援にもLLMは有効です。エンジニアが書いたコードに対して、次の処理を提案したり、バグの可能性を指摘したりすることで、開発スピードと品質の向上が期待できます。社内のコーディング規約に特化したモデルを構築すれば、より実用的な支援が可能です。
さらに、セキュリティ・コンプライアンス対応にもローカルLLMは活躍します。社内文書から機密情報や個人情報を自動検出したり、法令違反のリスクがある表現を指摘したりすることで、リスク管理を強化できます。
これらのユースケースを実現するには、モデル選定、GPU構成、推論環境の設計など、専門的な知識と経験が必要です。マクニカでは、NVIDIAのGPUを活用した最適な構成提案から導入・運用支援までを提供しています。ローカルLLMの導入を検討されている方は、ぜひご相談ください。
次回、ローカルLLMを構築するために必要なシステム全体像を解説!
本記事では、ローカルLLMの基礎と活用完全ガイドについてご紹介いたしました。
次回は、ローカルLLMを構築するために必要なシステム全体像や、マクニカが提供するサポート情報について、実践的な視点から詳しく解説します。
お見積もり/お問い合わせはこちら

