- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2135件がヒットしています。check

今回の内容
[NVIDIA DGX™ B200で始めるNVFP4推論]
第1話 NVFP4とは
第2話 NNVIDIA® TensorRT™ Model Optimizerを使用した量子化
第3話 Multi-LLM NIMでの推論
第4話 NVFP4とFP8のベンチマーク測定
第5話 Llama-3.1-405B-Instructのデプロイ
NVIDIA NIM™とは
データセンター、ワークステーション、クラウド全体での生成 AI モデルの展開を加速するように設計された、使いやすいマイクロサービスです。
NIM を使用することで、IT チームやDevOps チームは、独自のマネージド環境で大規模言語モデル (LLM) を簡単にセルフホストできます。さらにビジネスを変革できる強力なAI Agent、チャットボット、AI アシスタントを構築できる業界標準の API を開発者に提供できます。NIM は、NVIDIA の最先端の GPU アクセラレーションとスケーラブルな展開を活用して、比類のないパフォーマンスを提供します。
現在NIMには幅広いオープンなモデルや自社でファインチューニングしたmodelをセルフホストできるMulti-LLM NIMとNVIDIA社が最適化したLLM-specific NIMが存在します。これにより、ユーザーはパフォーマンス重視であっても柔軟性重視であってもNIMによりGPUに最適化された推論環境を手に入れることが可能となります。
|
|
Multi-LLM NIM
|
LLM-specific NIM
|
|
推奨用途
|
Deployするモデル用のコンテナをNVIDIAが提供していない場合
|
Deployするモデル用のコンテナをNVIDIAが提供している場合
|
|
パフォーマンス
|
最適化されたエンジンをオンザフライで構築し、ベースラインパフォーマンスを提供
|
特定のモデル/GPUの組み合わせでNVIDIA社にて事前に最適化されたエンジンを提供。最大限のパフォーマンスを提供
|
|
柔軟性
|
NGCやHuggingFace,ローカルディスクなど様々なモデル、フォーマット、量子化のタイプをサポートします
|
NIMについてはこちらの記事もご一読いただけますと幸いです。
Multi-LLM NIMでの推論
Multi-LLM NIMではこちらのリンクにあるように幅広いモデルのアーキテクチャーに対応しています。
今回は第2話で変換したMeta社のLlama3.3-70B-instructを使用します。
# Choose a container name for bookkeeping
export CONTAINER_NAME=LLM-NIM
# Choose the multi-LLM NIM image from NGC
export IMG_NAME="nvcr.io/nim/nvidia/llm-nim:1.12.0"
# Choose a HuggingFace model from NGC
export NIM_MODEL_NAME=<path to local model>
# Choose a served model name
# Highly recommended to set this to a custom model name. By default, NIM will pick the path to local model inside the container as model name
export NIM_SERVED_MODEL_NAME=macnica/test
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Add write permissions to the NIM cache for downloading model assets
chmod -R a+w "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NIM_MODEL_NAME=$NIM_MODEL_NAME \
-e NIM_SERVED_MODEL_NAME=$NIM_SERVED_MODEL_NAME \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
URL http://localhost:8000/docs にウェブブラウザーでアクセスして、NIM APIにアクセスできる、以下のようなGUIが表示されれば成功です。
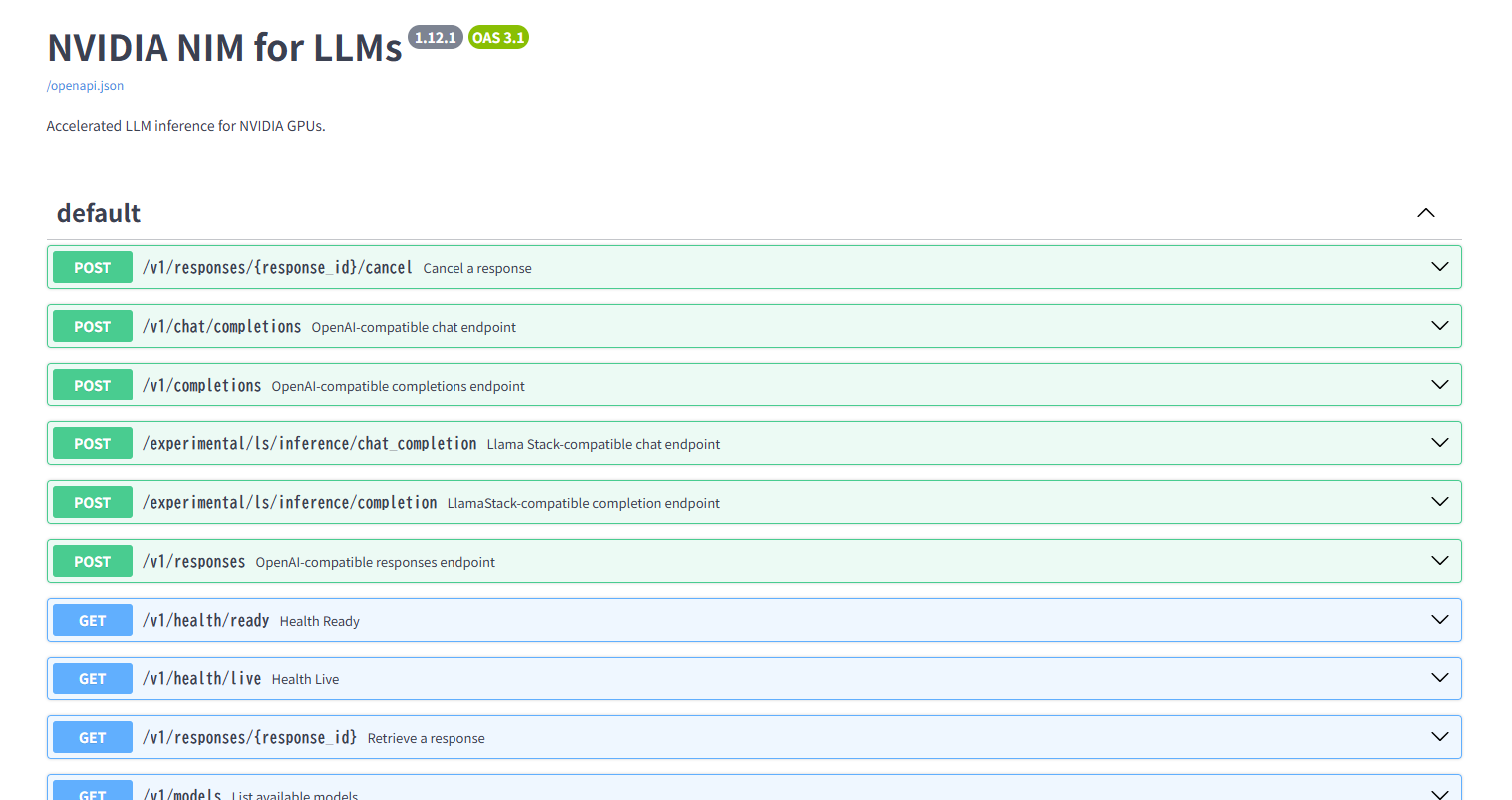
ここで起動時のlogを確認してみます。
第2話で作成したディレクトリーが読み込まれて、localのモデルを使用していることが分かります。
INFO 2025-07-28 04:13:19.864 utils.py:125] Found following files in /data/llama-33-70B-Instruct-nvfp4
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── config.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── generation_config.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── model.safetensors.index.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── special_tokens_map.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── tokenizer.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── tokenizer_config.json
INFO 2025-07-28 04:13:19.865 utils.py:129] └── trtllm_ckpt
INFO 2025-07-28 04:13:19.865 utils.py:125] Found following files in /data/llama-33-70B-Instruct-nvfp4/trtllm_ckpt
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── config.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── rank0.safetensors
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── special_tokens_map.json
INFO 2025-07-28 04:13:19.865 utils.py:129] ├── tokenizer.json
INFO 2025-07-28 04:13:19.865 utils.py:129] └── tokenizer_config.json
また、量子化の形式を確認してみるとNVFP4に量子化されていることが確認できます。
"quantization": {
"quant_algo": "NVFP4",
推論エンジンのサイズを確認してみると、メモリの使用量がおよそ半分の43GBになっていることが確認できます。
INFO 2025-07-28 04:15:36.732 utils.py:603] Engine size in bytes 42798834748これによりNVFP4で推論する準備が整いました。
Langchainを活用した推論
それでは最後に本記事でMulti-LLM NIMにデプロイしたLlama3.3-70B-instructに対して、Pythonのフレームワークの一つであるLangchainを活用して、実際に推論してみます。
今回はmacnica/testというMODEL_NAMEを環境変数にセットしていますので、こちらを使用します。
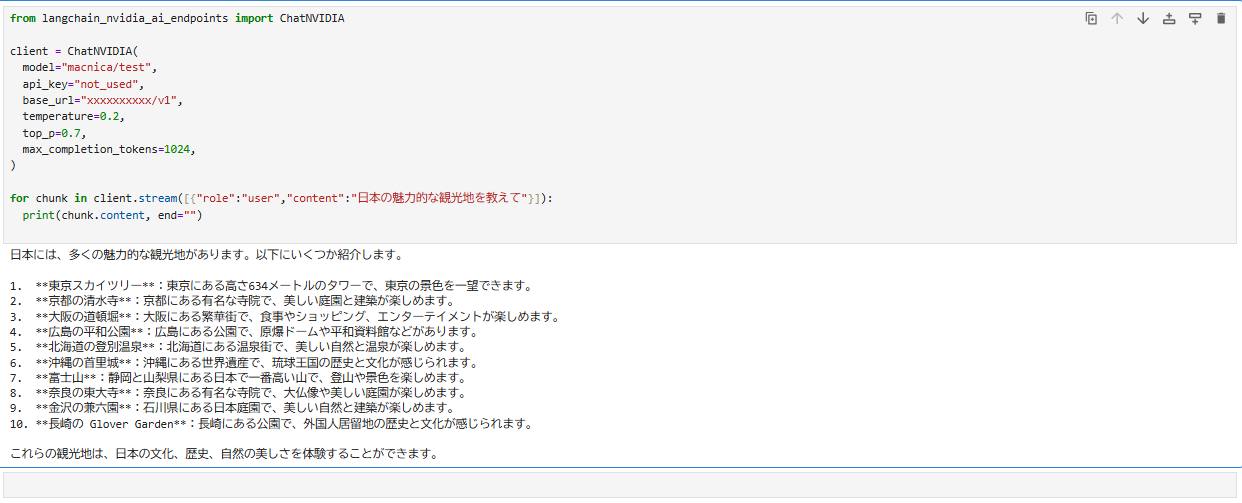
日本語の質問に対しても問題なく回答できていることが分かります。
弊社ではNIMを活用したRAGのChatbotに関する技術記事なども公開しておりますので、ご参考になれば幸いです。
また、この他にもNeMo Agent Toolkitや各種BlueprintとMulti-LLM NIMを組み合わせることで、自社のユースケースに特化したAI-Agent等の構築も可能になります。
まとめ
第3話では第2話で量子化したモデルを使用してNIMで推論する方法を紹介しました。
これによりユーザーはMulti-LLM NIMに対応したmodelを量子化して推論することが可能になり、より柔軟にGPUに最適化された推論環境を使用することが可能になります。
NIMにはNVIDIA社によって最適化されているLLM-specific NIMとユーザー自身で柔軟にmodelを変更することができるMulti-LLM NIMがあります。
ご自身でチューニングしたmodel等を使用する際にMulti-LLM NIMは最適な選択肢の一つとなるのではないでしょうか。
次回、Genai-perfでのベンチマーク測定!
本記事ではMulti-LLM NIMにデプロイして推論を行う方法を解説しましたが、いかがでしたでしょうか。
次回第4話では、Genai-perfを使用してNVFP4とFP8のベンチマークを測定します。
さらに第5話では、B200の大容量メモリーを活かして、巨大なLLMであるLlama-3.1-405B-Instructの推論を実施する方法について解説します。
《第4話 NVFP4とFP8のベンチマーク測定》 《第5話 Llama-3.1-405B-Instructのデプロイ》は、以下のフォームにご入力いただいた方にご案内しております。
ボタンをクリックすると簡単なフォーム入力画面へ遷移し、入力完了後にURLをメールでお知らせいたします。
お見積もり / お問い合わせ

