- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2132件がヒットしています。check

今回の内容
第1話では、マイクロベースの開発とNVIDIA NIMについて解説しました。
第2話では具体的に必要なソフトウェアやハードウェア、デプロイ方法について解説します。
[NVIDIA NIMを活用したRAGのChatbotの開発]
第1話 マイクロサービスを利用したRAGシステム開発
第2話 RAGシステムで必要なソフトウェア/ハードウェアの構成とは?
第3話 RAGシステムのサンプルコード
RAGで必要なソフトウェア/ハードウェアのセットアップ
今回は第1話で示した最小限の構成でのチャットボットの構築に関して解説いたします。
マイクロサービスベースの開発ではLLM、埋め込みモデル、ベクトルデータベースをそれぞれコンテナで用意します。
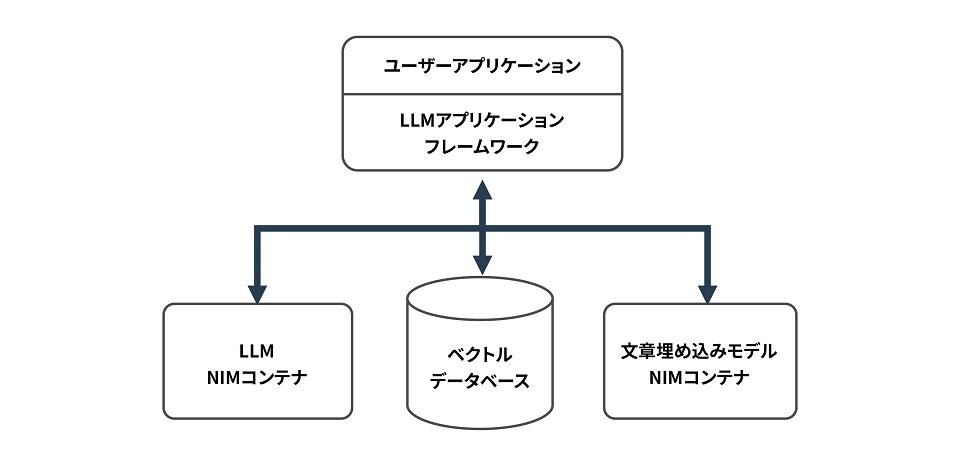
NIMコンテナ
第3話で示すサンプルコードではLLMはmeta/llama-3.1-70b-instruct、文章埋め込みモデルはnvidia/nv-embedqa-e5-v5を使用します。
NIMでコンテナが提供されているこれらのモデルに必要なハードウェアリソース条件、ソフトウェア条件の最新情報はこちらで確認できます。
ソフトウェア条件(Release 1.3.0、2024/12/12)
・Linux operating systems(Ubuntu 20.04 or later recommended)
・NVIDIA Driver >= 560
・NVIDIA Docker >= 23.0.1
ハードウェア条件(Release 1.3.0、2024/12/12)
meta/llama-3.1-70b-instruct(Release 1.3.0、2024/12/12)
|
GPU |
Precision |
Profile |
# of GPUs |
Disk Space |
|---|---|---|---|---|
| H200 SXM | FP8 | Throughput | 1 | 67.87 |
| H200 SXM | FP8 | Latency | 2 | 68.2 |
| H200 SXM | BF16 | Throughput | 2 | 133.72 |
| H200 SXM | BF16 | Latency | 4 | 137.99 |
| H100 SXM | FP8 | Throughput | 2 | 68.2 |
| H100 SXM | FP8 | Throughput | 4 | 68.72 |
| H100 SXM | FP8 | Latency | 8 | 69.71 |
| H100 SXM | BF16 | Throughput | 4 | 138.39 |
| H100 SXM | BF16 | Latency | 8 | 147.66 |
| H100 NVL | FP8 | Throughput | 2 | 68.2 |
| H100 NVL | FP8 | Latency | 4 | 68.72 |
| H100 NVL | BF16 | Throughput | 2 | 133.95 |
| H100 NVL | BF16 | Throughput | 4 | 138.4 |
| H100 NVL | BF16 | Latency | 8 | 147.37 |
| A100 SXM | BF16 | Throughput | 4 | 138.53 |
| A100 SXM | BF16 | Latency | 8 | 147.44 |
| L40S | BF16 | Throughput | 4 | 138.49 |
nvidia/nv-embedqa-e5-v5(Release 1.2.0、2024/12/12)
|
GPU |
GPU Memory (GB) |
Precision |
|---|---|---|
| A100 PCIe | 40 & 80 | FP16 |
| A100 SXM4 | 40 & 80 | FP16 |
| H100 PCIe | 80 | FP16 |
| H100 HBM3 | 80 | FP16 |
| H100 NVL | 80 | FP16 |
| L40s | 48 | FP16 |
| A10G | 24 | FP16 |
| L4 | 24 | FP16 |
コンテナのデプロイ方法
下記にmeta/llama-3.1-70b-instructをデプロイする方法を示します。
まず、NGCからコンテナをPullできるようにログインします。
$ docker login nvcr.io
Username: $oauthtoken
Password: <PASTE_API_KEY_HERE>次に以下のコマンドでNVIDIA NIMのコンテナをPullします。
export NGC_API_KEY=<PASTE_API_KEY_HERE>
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
docker run -it --rm \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
nvcr.io/nim/meta/llama-3.1-70b-instruct:latestこれでNIMのコンテナをデプロイすることができました。
curlコマンドを使用してモデルに質問をすることも可能です。
curl -X 'POST' \
'http://0.0.0.0:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama-3.1-70b-instruct",
"messages": [{"role":"user", "content":"Write a limerick about the wonders of GPU computing."}],
"max_tokens": 64
}'同様の方法で文章埋め込みモデル(nvidia/nv-embedqa-e5-v5)のデプロイを実行することが可能です。
詳細はこちらをご確認ください。
ベクトルデータベース
今回は生成AIアプリケーション用に構築されたオープンソースのベクトルデータベースであるMilvusを使用します。
Milvusではコンテナが提供されており、今回はコンテナをデプロイして使用します。
Milvusの詳細はこちらをご確認ください。
ソフトウェア条件(version 2.5.x、2024/12/12)
| Operating system | Software |
|---|---|
| Linux platforms |
Docker 19.03 or later Docker Compose 1.25.1 or later |
Hardware requirements
| Component | Requirement | Recommendation |
|---|---|---|
| CPU |
Intel 2nd Gen Core CPU or higher Apple Silicon |
Standalone: 4 core or more Cluster: 8 core or more |
| CPU instruction set |
SSE4.2 AVX AVX2 AVX-512 |
SSE4.2 AVX AVX2 AVX-512 |
| RAM |
Standalone: 8G Cluster: 32G |
Standalone: 16G Cluster: 128G |
| Hard drive | SATA 3.0 SSD or higher | NVMe SSD or higher |
コンテナのデプロイ方法
下記にMilvusのコンテナをデプロイする方法を示します。
こちらのコマンドでセットアップするとデフォルトではポート19530が使用されます。
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh下記のコマンドでコンテナのSTART、STOP、DELETEが可能です
#Start the Docker container
$ bash standalone_embed.sh start
#Stop the Docker container
$ bash standalone_embed.sh stop
#Delete the Docker container
$ bash standalone_embed.sh delete次回 サンプルコード公開!
今回はマイクロサービスを利用したRAGのチャットボットを構築する際のハードウェア構成やソフトウェアのデプロイに関して解説しました。
3話目ではサンプルコードを元にこれらを活用したマイクロサービスベースの開発に関して解説いたします。
AI導入をご検討の方は、ぜひお問い合わせください
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際はぜひお問い合わせください。

