- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2132件がヒットしています。check

はじめに
現在、多くの組織において生成AIを応用したシステムが実証試験段階から実利用段階へ移行しつつあります。これには既存のエンタープライズシステムとの接続が必要であり、システム開発の容易さやシステムの拡大に対応できる柔軟性が非常に重要となります。
一般的に疎結合と高い凝縮度を持つシステムは理解やメンテナンスが容易と言われます。凝縮度とは同じ役割のものが同じ所に集まっている度合です。疎結合と高い凝縮度を実現するためのソフトウェア実装方法として、最近注目されているのがマイクロサービスです。
第1話である本記事ではNVIDIA NIMを活用したマイクロサービスベースのRAGのシステム開発について説明します。
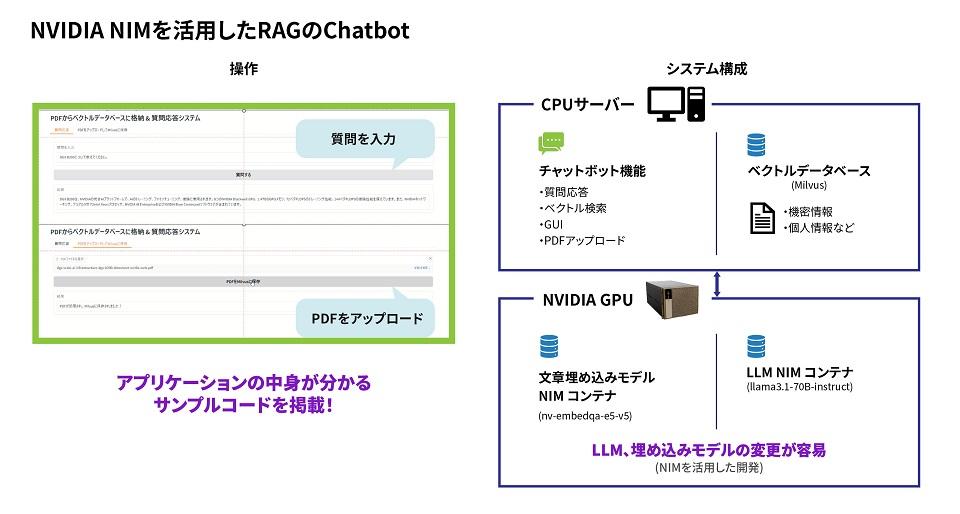
[NVIDIA NIMを活用したRAGのChatbotの開発]
第1話 マイクロサービスを利用したRAGシステム開発
第2話 RAGシステムで必要なソフトウェア/ハードウェアの構成とは?
第3話 RAGシステムのサンプルコード
マイクロサービスとは
マイクロサービスはソフトウェアが小さな独立したサービスで構成され、各マイクロサービスとはAPIを介して通信します。
APIとはアプリケーション プログラミング インターフェースの略で、ソフトウェアコンポーネント同士が情報をやり取りするための仕様というのが広義の意味であることは既にご存じのことと思います。マイクロサービスで利用するAPIはより限定的な意味合いでHTTPなどの通信プロトコル上に定義されたものになります。
NVIDIA NIMとは
本記事でご紹介するNVIDIA NIMは生成AIモデルをオンプレミスからクラウドまで容易にデプロイできるよう入念に作りこまれたマイクロサービスの集まりです。
各マイクロサービスはコンテナーイメージとして提供され、それらのデプロイを自動化するHelmチャートも併せて提供されます。NIMで提供されるマイクロサービスの機能は多岐に渡りますが、本記事で紹介させていただくRAGシステムでは大規模言語モデル(LLM)と文章埋め込み(Text Embedding)モデルのマイクロサービスを利用します。これらのモデルでは業界標準のAPIが使われているので、OpenAI社のChatGPTなどLLMとして利用している既存のシステムにおいてLLM部分をNVIDIA NIMへ移行するのは容易です。
例えば、OpenAI Python APIライブラリを通じてChat Completion APIを利用しているシステムでは、以下のようにたった3行のコード変更でNVIDIA NIMに対応できます。
import openai
client = openai.OpenAI(
base_url = "YOUR_LOCAL_ENDPOINT_URL", #<=たった3行の変更でNVIDIA NIMへ対応
api_key="YOUR_LOCAL_API_KEY" #<=たった3行の変更でNVIDIA NIMへ対応
)
chat_completion = client.chat.completions.create(
model="model_name", #<=たった3行の変更でNVIDIA NIMへ対応
messages=[{"role" : "user" , "content" : "Write me a love song" }],
temperature=0.7
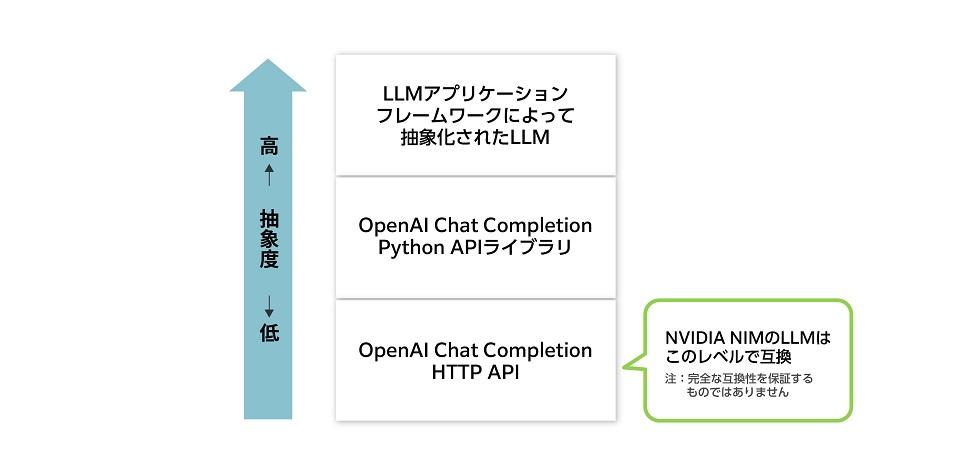
)また、NVIDIA NIMはLangChainやLlamaIndexなどのLLMアプリケーションフレームワークにも対応しています。これは下図のようにNVIDIA NIMがHTTP APIレベルで業界標準のOpenAI Chat Completion APIと互換性が保たれているからです。
RAGとは?
本記事で取り上げるのはRAGを用いたLLMシステムをNVIDIA NIMが提供するマイクロサービスによって実装する方法ですが、まずはRAGとは何かについて確認しましょう。
当然ながらLLMはそれ自体の学習に用いられた情報よりも新しい情報に基づく知識は持ちません。例えば、2023年12月に学習を完了したLLMは2024年のファッショントレンドについては何も知りません。また、ハルシネーション(幻覚)と呼ばれる不正確不適切な回答を生成する可能性があります。不正確さに対する対策となる技術の一つがRAG(Retrieval-Augmented Generation)です。
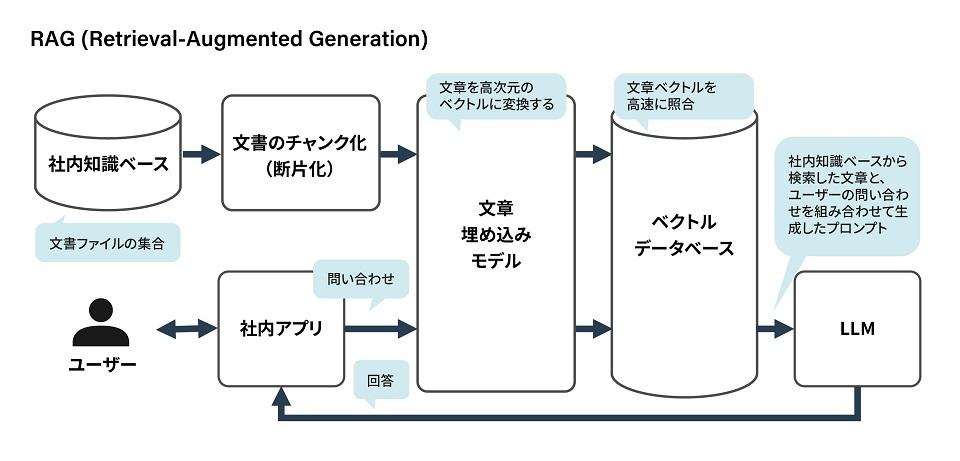
RAGでは社内に保管されている文書など知識ベースの内容を基にLLMが回答を作成します。あらかじめ知識ベース内の文書を断片化し各断片を文書埋め込みモデルにより埋め込みベクトル値に変換し、この埋め込みベクトル値と文書断片をペアとしてベクトルデータベースに保存しておきます。埋め込みベクトル値は浮動小数点の配列であり代表的な配列サイズは512または768です。各埋め込みベクトル値は各文章断片の意味的特徴を表現していると考えることができます。
一方、ユーザーが入力する質問も同じ文書埋め込みモデルにより1個の埋め込みベクトル値に変換されます。質問の埋め込みベクトル値と類似度が高い埋め込みベクトル値を持つ文章断片をベクトルデータベースから上位N個検索してその結果と共に質問をLLMへ入力し回答を得ます。これがRAGの基本的なしくみです。
NIMを利用したRAGシステムの構築
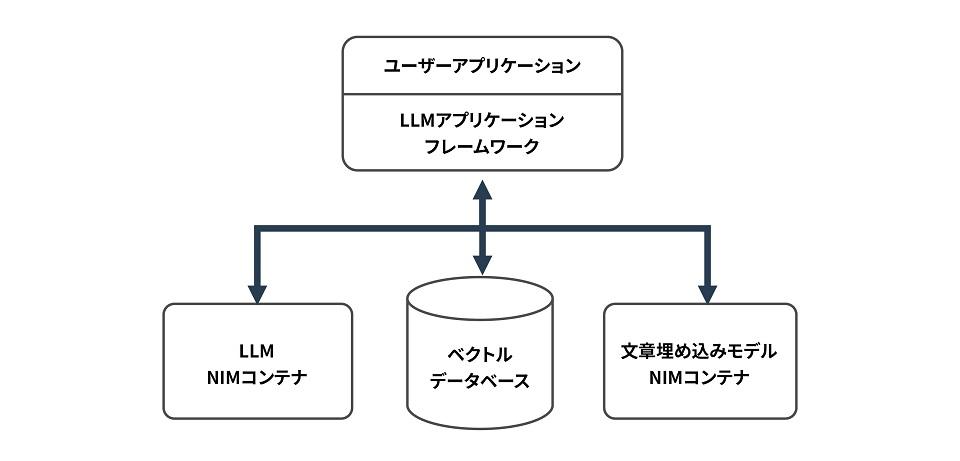
では、RAG Q&AシステムをNVIDIA NIMを利用して構築する場合の構成を考えてみましょう。
LLMと文章埋め込みモデルはコンテナイメージとしてNVIDIA NIMに含まれますので、それらのイメージからコンテナを起動します。ベクトルデータベースは現在のところNVIDIA NIMには含まれないため別途インストールします。LangChainなどのLLMアプリケーションフレームワークを利用するとLLMに限らず文章埋め込みモデルやベクトルデータベースも抽象化されているため、ユーザーアプリケーションが直接にそれらとインターフェースを取る必要はなくソフトウェア開発効率が向上します。
次回 NVIDIA NIMとベクトルデータベースのデプロイ!
本記事ではマイクロベースの開発とNVIDIA NIMについて解説しました。
次回は具体的に必要なソフトウェアやハードウェア、デプロイ方法について解説します。
AI導入をご検討の方は、ぜひお問い合わせください
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際はぜひお問い合わせください。

