- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2137件がヒットしています。check

はじめに
大人数での利用が想定されるLLMのアプリケーションでは、ユーザーエクスペリエンスや運用コストに大きく関わる「応答性」と「スループット」が重要とされます。
LLMアプリケーションの運用コストは、ユーザーの興味を引き付けることができる応答性を保ちながら、同時に処理できる問い合わせ数をどの位に設定するか、つまりユーザーエクスペリエンスとのトレードオフになります。そのため、応答性とスループットが関心の対象となります。
本連載では全3話に渡って、NVIDIA NIM™推奨のベンチマークツールGenAI-Perfを実際に使用した結果と、出力される各指標について解説します。
コストに焦点を当てますので、LLMアプリケーションの出力品質(精度)については対象外とします。
第1話である本記事ではベンチマーク測定ツールであるGenAI-Perfの出力指標について説明します。
[LLMアプリケーションのベンチマーク測定]
第1話 GenAI-Perfとは?
第2話 GenAI-Perfの使い方
第3話 NVIDIA NIMとvLLMのベンチマーク測定
GenAI-Perfとは?
GenAI-Perfは推論サーバー上で動作する生成AIモデルのスループットと遅延を計測するためのコマンドラインツールであり、Tritonクライアントライブラリーの一部として提供されています。推論サーバーのAPIはOpenAI互換APIが想定されています。NVIDIA NIM向けベンチマークツールとしてNVIDIA社から推奨されています。
GenAI-Perfが想定するLLMアプリケーションのシナリオ
GenAI-PerfはLLMアプリケーションが以下のシナリオで動作することを想定して、スループットの遅延を測定します。
- LLMアプリケーションのユーザーが問い合わせ(クエリ)を発行します。(問い合わせにはユーザーが作成したプロンプトが含まれます。)
- 推論サーバーがそれを受信して、ジョブの待ち行列キューに入れます。
- LLMモデルがプロンプトを処理します。
- LLMモデルはユーザーに向け、トークン単位に応答を出力します。(ストリーミング形式の応答)
GenAI-Perfが出力する指標
指標(メトリックス)
- Time to First Token (TTFT)
- End-to-End Request Latency (e2e_latency)
- Inter-Token Latency (ITL)
- Total system Throughput : Tokens Per Second (TPS)
- Requests Per Second (RPS)
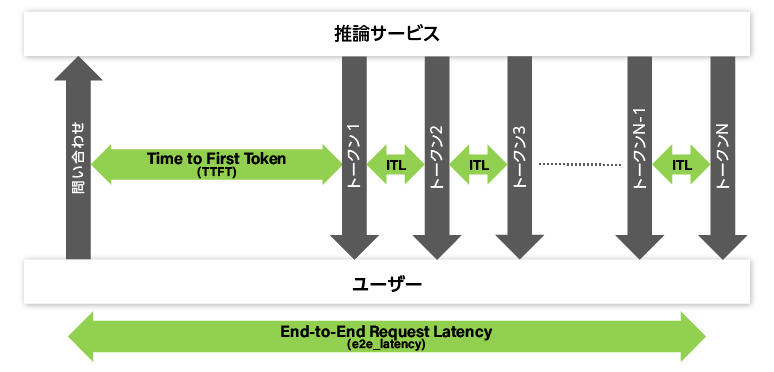
Time to First Token (TTFT)
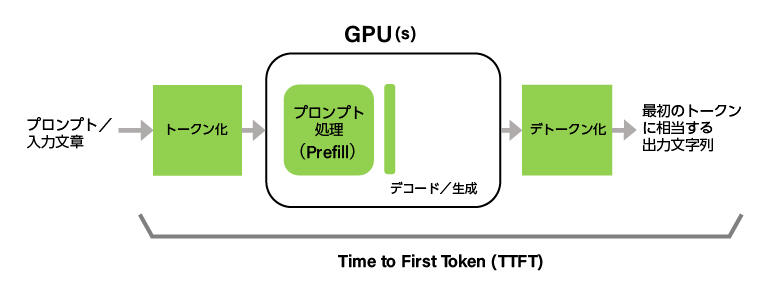
Time to First Token(TTFT)は、LLMへ問い合わせを行ってから、最初の出力トークンが返ってくるまでの時間です。LLMからの返信にトークンが含まれていない場合は除外します。(LLMからの最初の返信にトークンが含まれておらず、2番目の返信からトークンが含まれていた場合は、問い合わせから2番目の返信までの時間が、TTFT値となります。)
ストリーミング出力するLLMを利用したアプリケーションでは、通常、トークンを受信する度に、それをユーザーへ表示するので、TTFTが、ユーザーにとって待ち時間となります。
TTFTには、LLMサーバーがリクエストキューを満たす時間やネットワーク遅延を含んでいることに注意してください。また、問い合わせのプロンプトが長いほど、TTFTも長くなります。これは、LLMのアテンション機構がキーバリューキャッシュを生成するために、プロンプトすべてを必要とするからです。
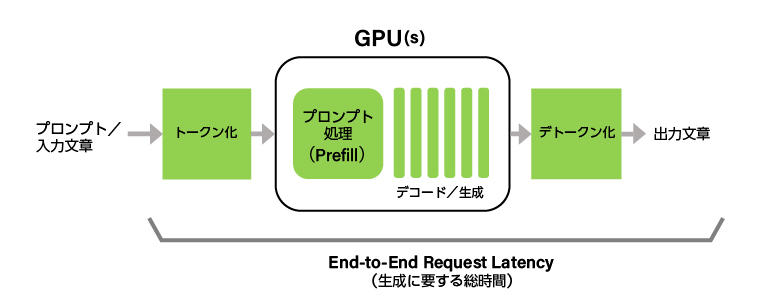
End-to-End Request Latency (e2e_latency)
End-to-End Request Latency(e2e_latency)は、ユーザーがLLMへ問い合わせを行ってから、LLMからすべての出力トークンが返るまでの時間です。e2e_latencyには、LLMサーバーのキューイング機構やバッチ編成機構に関わる時間、ネットワーク遅延が含まれることに注意してください。
ユーザーが最初のトークンを受信してから、最後のトークンを受信するまでの時間をGeneration_timeとすると、e2e_latencyは以下のように表現することが可能です。
e2e_latency = TTFT + Generation_time
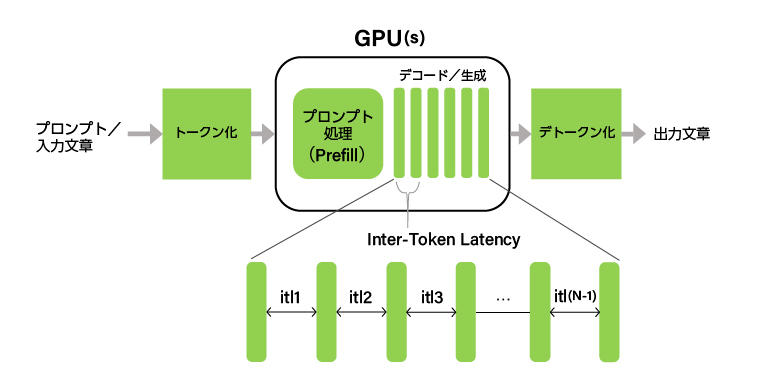
Inter-Token Latency (ITL)
Inter-Token Latency(ITL)は連続した出力トークン間の時間を平均したものです。Time Per Output Token(TPOT)と呼ばれることもあります。
同じITLという名前の指標であっても、ベンチマークツールによって、最初のトークンまでの時間(TTFT)を含めるかどうかなどの差異が存在します。GenAI-Perfでは、TTFTを含めず、以下のとおり定義されます。
ITL = (e2e_latency - TTFT) / (Total_output_tokens - 1)
Total system Throughput : Tokens Per Second (TPS)
Tokens Per Second(TPS)は1秒当たりの出力トークン数です。GPU計算リソースに余裕がある状態では、LLMサーバーへ問い合わせが増加するのに応じて、TPSも増加します。TPSの厳密な定義は以下のとおりです。
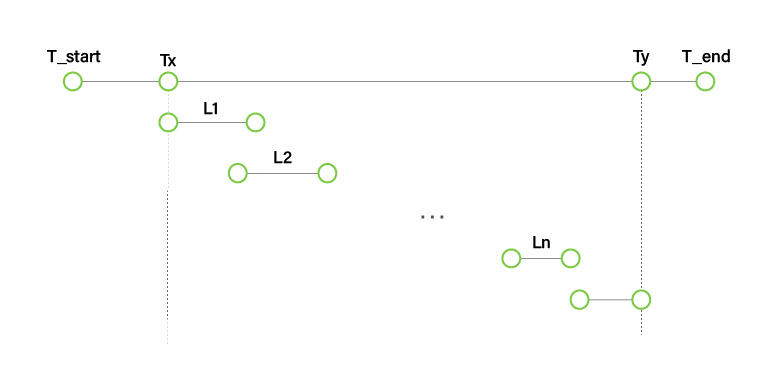
- Li:i番目の問い合わせに対するe2e_latency
- T_start:GenAI-Perfによるベンチマーク開始時刻
- Tx:最初の問い合わせを行った時刻
- Ty:最後の問い合わせに対する最後の応答を受信した時刻
- T_end:GenAI-Perfによるベンチマーク終了時刻
TPS = Total_output_tokens / (Ty - Tx)
注:TPSを算出する際に、ウォーミングアップ及びクールダウンのための問い合わせは含みません。
Requests Per Second (RPS)
Requests Per Second(RPS)は1秒間に完了した問い合わせ数です。
RPS = total_completed_requests / (Ty - Tx)
次回、GenAI-Perfの使い方を徹底解説!
本記事ではGenAI-Perfが出力する各指標についてご紹介しましたが、いかがでしたでしょうか。
次回はGenAI-Perfの使い方について解説します。
AI導入をご検討の方は、ぜひお問い合わせください
AI導入に向けて、弊社ではハードウェアのNVIDIA GPUカードやGPUワークステーションの選定やサポート、また顔認証、導線分析、骨格検知のアルゴリズム、さらに学習環境構築サービスなどを取り揃えています。お困りの際は、ぜひお問い合わせください。

