- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2191件がヒットしています。check

本連載では、NVIDIA社が開発した「Triton Inference Server」にてYOLO v5 を実行する方法を全3話で解説いたします。
第1話は、「Triton Inference Server」とはなにか、その概要についてわかりやすくご紹介します。2話以降をご覧になりたい方は、記事の末尾の簡単なフォームへご登録すると閲覧できます。
[NVIDIA Triton Inference Server で YOLO v5 を実行する]
第1話 Triton Inference Server とは?
第2話 サーバーの構築
第3話 クライアント アプリケーションの実行
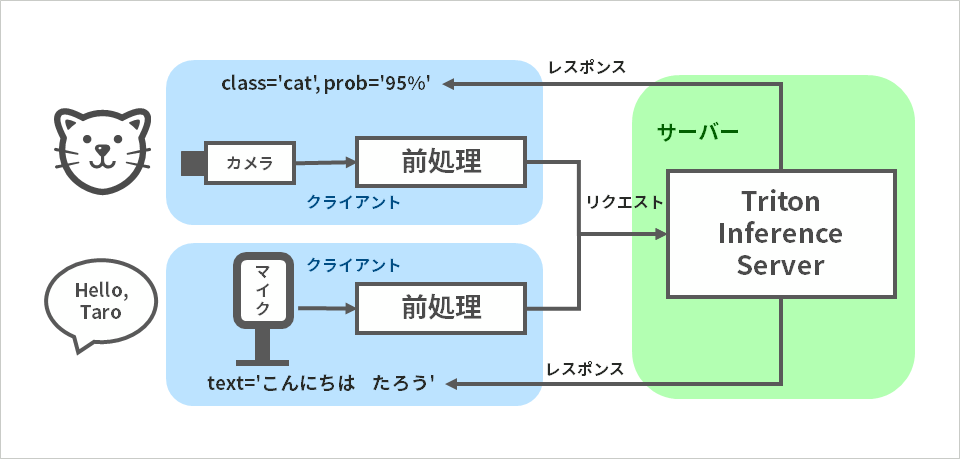
クライアント サーバー モデル
クライアント サーバー モデルはご存じのとおり、機能や情報を提供するサーバーと、それを利用するクライアントを分け、その間をコンピューター ネットワークで接続するシステムの形態です。これからご紹介する Triton Inference Server も、このクライアント サーバー モデルに基づいて設計された、AI 推論専用のサーバー ソフトウェアです。
AI 推論に関わる処理の中で、特に重たいニューラル ネットワークの処理はサーバー側で実行されるため、高性能なGPUはサーバー側にのみ配置すればよく、クライアント側は NVIDIA社製 GPU を持たない普及型の Windows PC 上にも実装可能です。
Triton Inference Server
Triton Inference Server は NVIDIA 社によって開発され、オープンソースとして提供されています。Triton Inference Server の通信プロトコルはコミュニティーによって策定が進められている KServe プロトロコルをベースにしているため、Triton Inference Server は KServe エコシステムと共に成長することが大いに期待できます。
複数のディープラーニング フレームワークや、推論実行エンジンに対応しているのも魅力です。それぞれに対応する部分は、バックエンドと呼ばれますが、Triton Inference Serverには現在、以下のバックエンドが用意されております。
Triton Inference Server の主な特長を挙げると以下のとおりです。
- 使いやすさ
- 複数のディープラーニングフレームワークに対応
- いろいろなクエリー形式に対応
- リアルタイム、バッチ、オーディオ ストリーミング、アンサンブル
- デプロイメントのコスト低減
- GPU上の推論とCPU上の推論の両方に対応
- クラウド、自社データセンター、エッジのいずれでも動作可能
- ベアメタルと仮想化の両方に対応
- ハードウェア資源の最大活用
- 複数モデルの同時実行
- ダイナミック バッチングにより、遅延の制約下でスループットを最大化
本連載でおこなう実験の内容
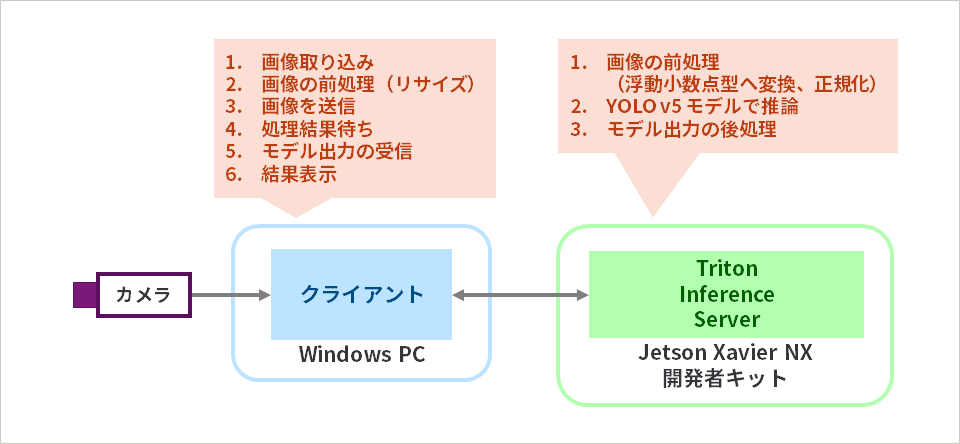
本連載では、Jetson Xavier NX 開発者キット上に、Triton Inference Server をインストールして、YOLO v5 物体検出を実行します。クライアントは Windows PC 上で実行します。Windows PC に接続されたウェブカメラで画像を入力後、同じく Windows PC 上で画像の前処理(リサイズ)をおこない、その画像を Jetson Xavier NX 開発者キット上の Triton Inference Server へ送信します。Triton Inference Sever は、クライアントから受け取った画像のデータ型を変換後、YOLO v5 モデルによる推論を実行し、後処理によりバウンディングボックス座標を算出してクライアントへ返します。最後に、クライアントは推論結果を Windows PC のディスプレイへ表示します。上記の処理は繰り返し実行されます。
※第2話で説明する理由により、前処理はクライアント側でおこなうリサイズと、サーバー側でおこなう正規化、浮動小数点型変換に分けてあります。
次回、Triton Inference Server の立ち上げについて解説
今回は、Triton Inference Server の概要と、本連載でおこなう実験について説明いたしました。次回は、YOLO v5 モデルの準備と、Triton Inference Server の立ち上げについて説明させていただきます。
第2話、3話は下記ボタンから簡単なフォームをご入力いただいたあとに閲覧できますので、ぜひお申し込みください。
お問い合わせはこちら

