- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2184件がヒットしています。check

グラフィックスハードウェアの性能面における急速な増強やプログラマビリティに対する最近の改良に伴い、幅広いアプリケーション分野においてグラフィックアクセラレータが演算要求のタスクに対して必要不可欠なプラットフォームとなってきております。また、その GPU の強大な計算能力により、GPU-to-GPU は科学技術の様々な分野において証明された非常に有効な手法となってきております。
GPU ベースのクラスタは有限要素計算や計算流体力学、モンテカルロシュミレーションのように膨大な計算処理を実行するために使用されております。また世界で有数のスーパーコンピュータでは要求性能を達成するために GPU を使用します。GPU は多くのコア数とフローティングポイントの演算能力を備えているため、GPU-to-GPU 通信で高いスループットと低レイテンシーを得るためには、そのプラットフォーム間を高速なインフィニバンドネットワーキングで接続する必要があります。
GPU は価格/性能や電力/性能の両方のメリットをもたらし非常に価値のあるパフォーマンスアクセラレーションを提供しますが、その一方で GPU ベースのクラスタのいくつかの領域ではより高い性能や効率性を提供する上で改善の余地も残っています。マルチGPUノードで構成されるクラスタを展開する上でのパフォーマンスの問題は、主に GPU 間の相互作用やまたはGPU-to-GPU の通信モデルが関係します。GPU Direct テクノロジー以前では、 GPU 間におけるどの通信もそのホスト CPU と必須のバッファコピーを伴わなければならず、その GPU の通信モデルはGPU とインフィニバンドネットワーク間でのメモリ転送の開始と管理を CPU に要求していました。各々の GPU-to-GPU 通信は以下のステップに従う必要がありました。
1. GPU が GPU 専用のホストメモリにデータをライトする。
2. ホスト CPU はそのデータを GPU 専用のホストメモリからインフィニバンドデバイスが RDMA 通信で利用できるホストメモリへコピーする。
3. インフィニバンドデバイスはそのデータをリードし、リモートノードへデータを転送する。
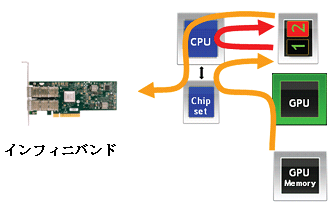
GPU 通信における CPU の関与とそのバッファコピーの必要性がシステム内にボトルネックを生み、 GPU 間でデータ到達の遅れを発生させます。
NVIDIA と Mellanox からのこの新しい GPU Direct テクノロジーは通信ループ内の CPU の関与とバッファコピーの必要性をなくすことによって、 NVIDIA Tesla と Fermi GPU に対してより高速な通信を可能にしております。この成果によって GPU-to-GPU の通信時間を 30 % 短縮することでシステム全体の性能と効率性を向上しております。NVIDIA GPU Direct は NVIDIA GPU と Mellanox インフィニバンドアダプタの間で新しいインタフェースを提供し、双方のデバイスで同じシステムメモリを共有することを可能にします。
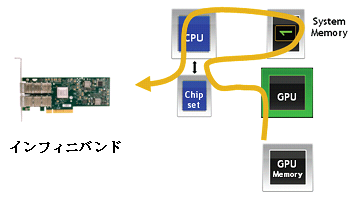
ハイパフォーマンスアプリケーションにおけるこの性能の改善は使用される GPU 通信の量に依存します。並列実行を利用するアプリケーションでは最大で 42 % の性能改善や生産性の向上を見ることが出来ます。全てのアプリケーションで Mellanox インフィニバンドアダプタと NVIDIA GPU Direct テクノロジーを使って、性能と効率性の改善が期待できます。NVIDIA GPU Direct と Mellanox インフィニバンドアダプタは GPU ベースのシステムにおいて必要不可欠なテクノロジーであり、この一体となったソリューションは GPU の動作能力とシステム全体の生産性を最大化すること、最高の ROI ( return-on-investment ) を実現します。

上記の内容は次の Mellanox 社のホワイトペーパーを参考にしております。
http://www.mellanox.com/pdf/whitepapers/TB_GPU_Direct.pdf