- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2132件がヒットしています。check

前回は、人を検出するAIのデモを実際にFPGAに組み込み、動作確認と消費電力確認をおこないました。実際の動きや消費電力の低さをみて、今後のモチベーションがグンっと上がった私ですが、この熱が冷めないうちにリファレンスデザインの詳細を調べていきたいと思います。
心の逃避行が始まる前に…。

【目次】
リファレンスデザインのダウンロード
何は無くともまずはリファレンスデザインをダウンロードしないと話が始まりませんので、ダウンロードしていきます。前回記事でもご紹介した通り、Lattice社からは複数種類のリファレンスデザインが提供されています。その中の"Object Counting AI"を選択します。
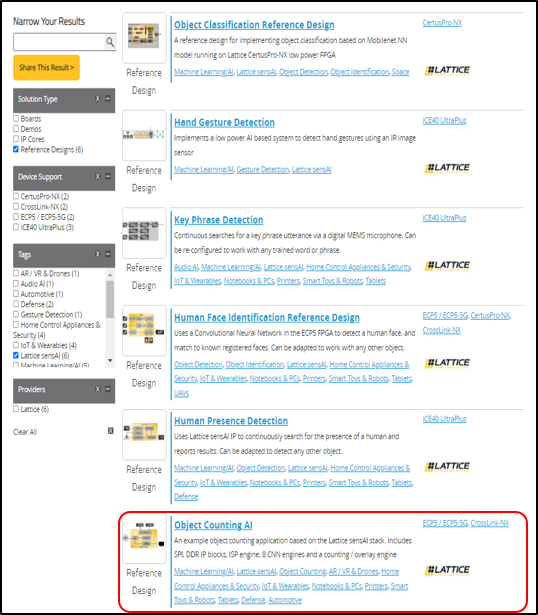
※リファレンスデザイン紹介サイトURL
サイトの下の方にドキュメントやリファレンスデザインのダウンロードリンクがありますが、今回は"CrossLink-NX Object Counting using Mobilenetv2"というリファレンスデザインをダウンロードします
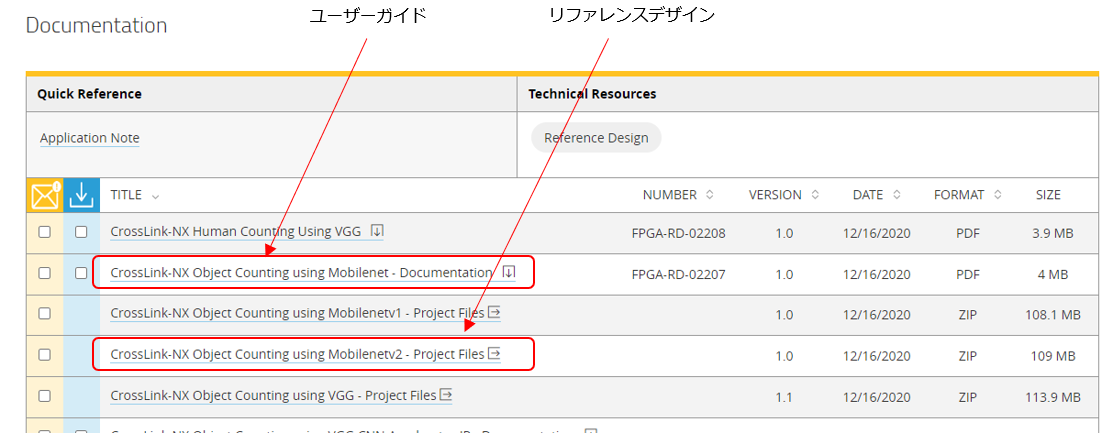
※CrossLink-NX Object Counting Reference Design ユーザーガイド
※CrossLink-NX Object Counting Reference Design プロジェクトファイル
プロジェクトファイルのダウンロードの際には途中でLicense Agreementへの同意確認のチェックがあるため、内容を確認したうえでダウンロードします。
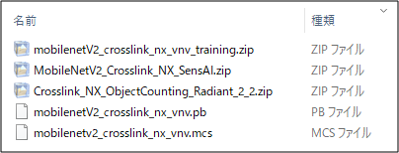
Downloadを実行するとzipファイルがダウンロードされるため、これを解凍すると以下のようなファイルが出てきました。さらに3つのzipファイルが入っています。これらの3つのzipファイルはLatticeのAIソリューションの開発フローに大きくかかわっているようです。
LatticeのAIソリューションの開発フロー
LatticeのAIソリューションの開発フローは以下の図のようになっています。前述の3つのzipファイルは、このフローの①②③それぞれの部分に対応する形で提供されているようです。
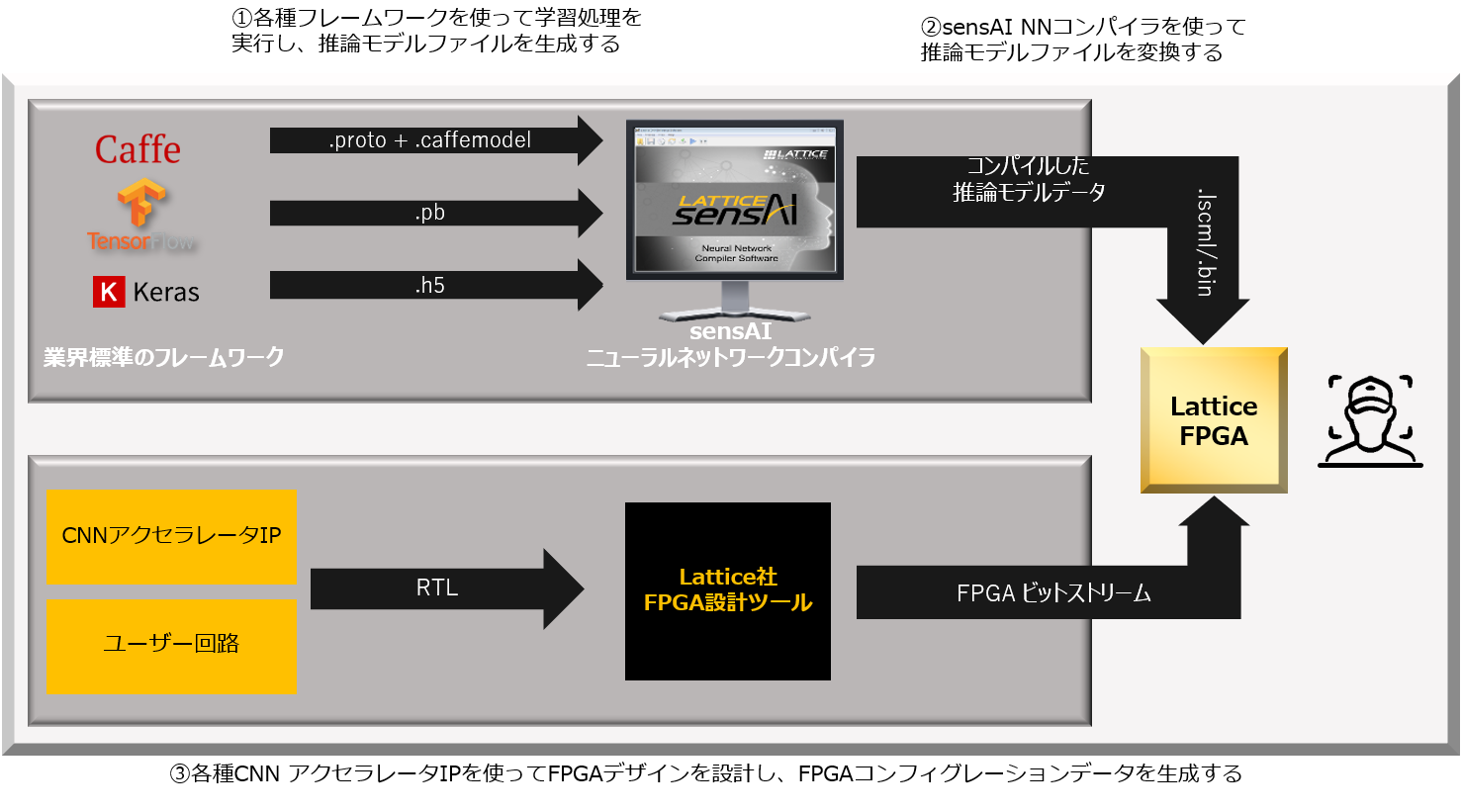
フロー上段は、ニューラルネットワークモデルの開発フローです。ニューラルネットワークモデルは、業界標準フレームワーク上で生成されます。Lattice社からはsensAIニューラルネットワークコンパイラー(以後、sensAIコンパイラーと表記)というツールが提供されます。このツールを使って学習済みのニューラルネットワークモデルをコンパイルすることにより、FPGAが解釈できる形に変換することができるようです。
フロー下段は、FPGA回路設計の開発フローです。CNNアクセラレーターIPというのは今回のLattice社のAIソリューションで提供されるようになったAI処理のエンジン部分を担うものになります。周辺ユーザー回路と合わせてLattice社FPGA設計ツール上で設計をおこないます。ニューラルネットワークモデルの情報とCNNアクセラレーターIPが共にFPGAに組み込まれた状態で、何らかのデータを与えることにより、AIによる推論処理が実行される形になるようです。
このフローを実行するためには、
①ニューラルネットワークモデルのトレーニング環境(学習用データセットやPythonスクリプトなど)
②生成した学習済みモデルをsensAIコンパイラでコンパイルするための環境
③FPGAのコンフィグレーションデータを生成するための環境(RTLソースコードなど)
が必要になってきますが、先ほどダウンロードしたzipファイルにはこれらそれぞれの環境一式がzip形式に圧縮されて含まれているようです。
① mobilenetV2_crosslink_nx_vnv_training.zip
ニューラルネットワークモデルのトレーニング環境。学習済みのニューラルネットワークモデルを生成するためのファイル群が含まれたファイルになっています。
② MobileNetV2_Crosslink_NX_SensAI.zip
sensAI コンパイラーのプロジェクトファイルが含まれたファイルになっています。拡張子*.ldnnのファイルをsensAIコンパイラーでOpenすることにより、プロジェクトの内容は確認できるようになっています。

③ Crosslink_NX_ObjectCounting_Radiant_2_2.zip
FPGAのコンフィグレーションデータを生成するためのソースコードなどが含まれたファイルになっています。Lattice Radiant(Lattice社のFPGA設計ツール)のプロジェクトファイル一式の形で提供されています。拡張子*.rpfのファイルをRadiantでOpenすることにより、プロジェクトの内容は確認できるようになっています。

Lattice社からは他にもAIのリファレンスデザインは多く提供されており、それぞれのリファレンスデザインのファイル構成を見てみたところ、大枠としてはほとんどはこれと同じようなファイル構成になっているようです。
なお、リファレンスデザインのユーザーガイドを見ますと、ニューラルネットワークモデルのトレーニングについては、LinuxのUbuntuマシン上で実施することを前提に記載されています。
ニューラルネットワークモデルのトレーニング環境をもうちょっと詳しく見てみる
その中でも特に気になる①のニューラルネットワークモデルのトレーニング環境を調べてみました。
以下のようなフォルダ構成になっているようです。

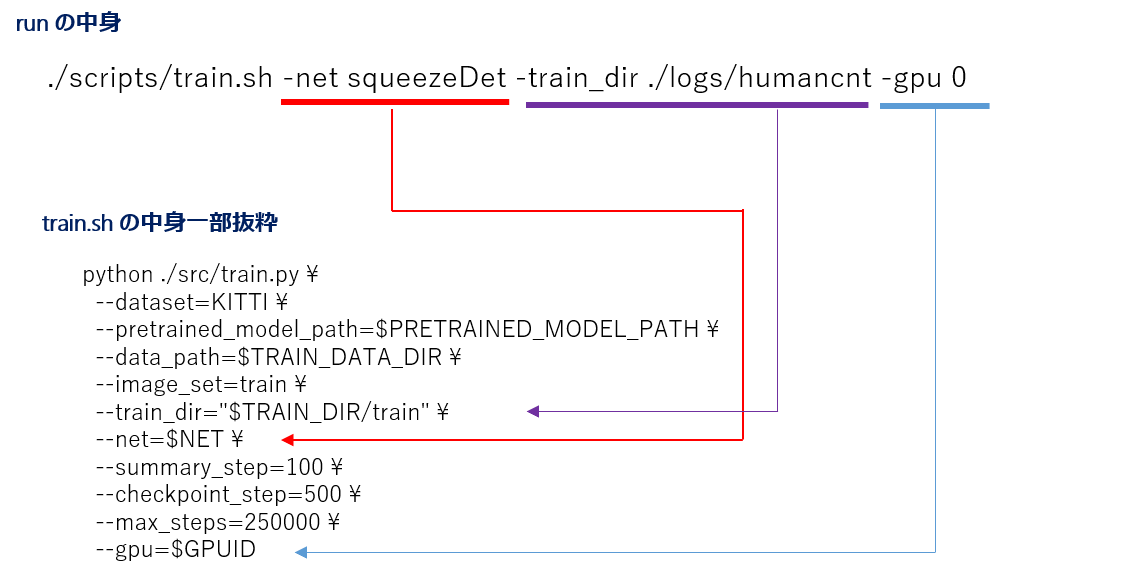
ニューラルネットワークモデルのトレーニング処理自体はこの中のrunスクリプトを実行することにより開始されるようです。runスクリプトがtrain.shを読み出し、さらにtrain.shからtrain.pyが実行されるような流れになっています。
しかし、ニューラルネットワークモデルのトレーニングを行うには大量の学習データが必要になるはずでは…。と思い、リファレンスデザインの資料をよく確認すると、"Prepairing the Dataset"という章があることを発見!今回の人検知のリファレンスデザインでは、トレーニング用の学習データとして、Googleが無償提供しているOpen Image Dataset v4というデータセットを利用しているようです。
Google Open Image Dataset v4
Google Open Image Dataset v4は合計でなんと900万枚以上の画像データの集まりになっているそうです。また、それぞれに対して、画像内に写っている物体が何なのかを示すラベルと座標情報がペアになっているデータセットのようです。最新バージョンはv6になりますが、今回のリファレンスデザインではv4を利用しています。物体の種類(クラス)は全部で600クラスまであり、今回の人検知のリファレンスデザインではその中の"Person"クラスのデータを利用する形です。そんな便利なものが無償で提供されているんですね!さすがGoogleです。
データセットはOpen Image DatasetのサイトやGithubからダウンロードできそうですが、特定のクラスのデータだけをダウンロードするなどの場合は、Open Image Datasetが提供しているPythonスクリプトを利用した方がやりやすそうです。また、前述のrunスクリプトではtrain.shのようなシェルスクリプトの実行が必要になり、Windows環境でそのまま実行するのは厳しそうです。そうなってくると先にちゃんとLinux環境を整えたほうがよさそうですね。
次回はLinuxマシンを使った学習環境の構築について調べていきたいと思います。
お問い合わせ
評価ボードやサンプルデザインに関する不明点や、本ブログで扱ってほしい内容などありましたらお気軽にお問い合わせください!
