- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2182件がヒットしています。check



こんにちは、マス男です。
今回は、Verilog HDL の文法でつまずいたときのことをお話しします。
研修中に出てきた例文には、値を代入する記述方法が2通りあり 混乱してしまいました。
『 a = b 』
『 a <= b 』
どちらも “b を a に代入する” という意味です。
何が違うのか文献で調べますと、
● ブロッキング代入 (=) : シーケンシャル・ブロック内で上から順番に実行される
● ノンブロッキング代入 (<=) : シーケンシャル・ブロック内で、ステートメントの記述の順番に関係なく代入できる
と説明されています。
シーケンシャル・ブロックというのは always 文の begin と end で囲われた部分のことです。
「実際に合成される回路にどのような違いがあるか?」と疑問に感じ、 Quartus® II を使ってブロッキングとノンブロッキングの違いを 4入力1出力の回路で検証しました。
結果を RTL Viewer で確認してみると、
ブロッキング代入は記述の順番によって様々な回路が生成されました。
ノンブロッキング代入は記述の順番に関係なく、同じ回路が生成されました。
ブロッキング代入 (=) の場合
|
always @ (posedge clk) begin dadb = da & db; dcdd = dc & dd; dout = dadb & dcdd; end endmodule |
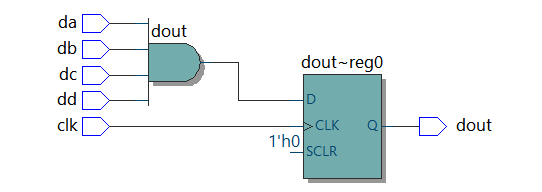 |
|
always @ (posedge clk) begin dcdd = dc & dd; dout = dadb & dcdd; dadb = da & db; end endmodule |
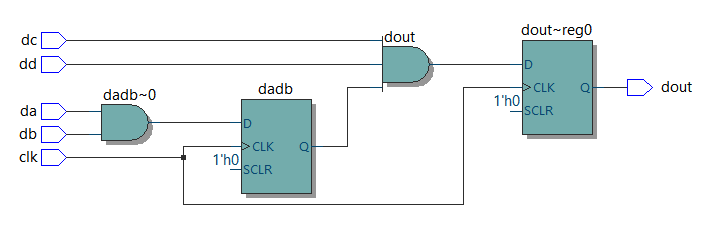 |
|
always @ (posedge clk) begin dout = dadb & dcdd; dadb = da & db; dcdd = dc & dd; end endmodule |
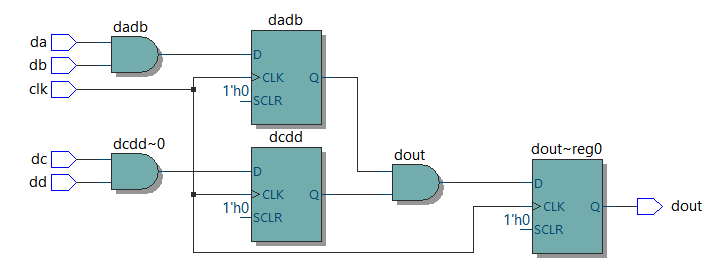 |
ノンブロッキング代入 (<=) の場合
|
always @ (posedge clk) begin dadb <= da & db; dcdd <= dc & dd; dout <= dadb & dcdd; end endmodule |
|
|
always @ (posedge clk) begin dcdd <= dc & dd; dout <= dadb & dcdd; dadb <= da & db; end endmodule |
|
|
always @ (posedge clk) begin dout <= dadb & dcdd; dadb <= da & db; dcdd <= dc & dd; end endmodule |
|
学んだこと
always 文内でブロッキング代入を記述すると実行順序に依存した回路が生成されるので、文法記述と論理合成の対を理解していないと意図しない回路が生成される。
よく例文を見ると、 assign 文ではブロッキング代入(=)、 always 文ではノンブロッキング代入(<=) で記述されていました。
私は、 always 文内でブロッキング代入を記述し、意図しない回路が生成されて思わず赤面してしまいました。